Veri Madenciliği - Tüm Sorular
Ünite 1
Soru 1
İnsan beyninde yer alan sinir hücrelerinin ilk yapay modeline ne ad verilir?
Seçenekler
A
Perseptron
B
Hiyerarşik veri modeli
C
Ağ veri modeli
D
Veritabanlarında bilgi keşfi
E
SQL
Açıklama:
İnsan beyninde yer alan sinir hücrelerinin ilk yapay modeline perseptron denilir. Bu nedenle doğru cevap A'dır.
Soru 2
Bilgisayarların bazı işlemlerden çıkarsamalar yaparak yeni işlemler üretmesine ne ad verilmektedir?
Seçenekler
A
İstatistik
B
Makine öğrenimi
C
Görselleştirme
D
Veritabanı sistemleri
E
Örüntü tanıma
Açıklama:
Bilgisayarların bazı işlemlerden çıkarsamalar yaparak yeni işlemler üretmesine makine öğrenimi denilir. Bu nedenle doğru cevap B olmaktadır.
Soru 3
Olaylar ve nesneler arasında düzenli ve sistematik bir biçimde tekrarlanan ilişki modellerini ifade etmek için kullanılan kavrama ne ad verilir?
Seçenekler
A
İstatistik
B
Veritabanı
C
Örüntü
D
Makine öğrenimi
E
Veri ambarı
Açıklama:
Olaylar ve nesneler arasında düzenli ve sistematik bir biçimde tekrarlanan ilişki modellerini ifade etmek için kullanılan kavrama örüntü denilmektedir. Bu nedenle doğru cevap C seçeneğidir.
Soru 4
Aşağıdakilerden hangisi bilginin elde edilmesinde verinin işlenmesi ve dönüştürülmesi sürecinde yapılacak işlemlerden birisi değildir?
Seçenekler
A
Özetleme
B
Çoğaltma
C
Analiz
D
Temizleme
E
Sıralama
Açıklama:
Bilginin elde edilmesinde verinin işlenmesi ve dönüştürülmesi sürecinde yapılacak işlemler veri üzerinde kaydetme, sınıflama, sıralama, hesaplama, özetleme, çoğaltma, analiz ve raporlamadır. Bu nedenle doğru cevap D'dir.
Soru 5
Veri ambarında yer alan veriler üzerinde çok boyutlu, çok yönlü analiz ve sorgulama yapılmasını sağlayan sistemlere ne ad verilir?
Seçenekler
A
Üst veri
B
Veri deposu
C
Veri madenciliği
D
Veri tabanı sistemleri
E
OLAP
Açıklama:
Veri ambarında yer alan veriler üzerinde çok boyutlu, çok yönlü analiz ve sorgulama yapılmasını sağlayan sistemlere OLAP (Çevrimiçi Analitik İşleme) denilir. Bu nedenle doğru yanıt E olmaktadır.
Soru 6
Veri tabanlarında bilgi keşfi sürecinin en fazla zaman alan aşaması aşağıdakilerden hangisidir?
Seçenekler
A
Amacın tanımlanması
B
Veriler üzerinde ön işlemlerin yapılması
C
Modelin kurulması ve değerlendirilmesi
D
Modelin kullanılması ve yorumlanması
E
Modelin izlenmesi
Açıklama:
Veri tabanlarında bilgi keşfi sürecinin en fazla zaman alan aşaması veriler üzerinde ön işlemlerin yapılması olmaktadır. Bu nedenle doğru cevap B seçeneğidir.
Soru 7
Aşağıdakilerden hangisi kayıp verilerin neden olacağı olumsuzlukları ortadan kaldırmak amacıyla kullanılan yaklaşımlardan birisi değildir?
Seçenekler
A
Normalizasyon yöntemini kullanmak
B
Kayıp veri içeren kaydı veri kümesinden çıkarmak
C
Tüm kayıp veriler için aynı veriyi girmek
D
Kayıp veri yerine tüm verilerin ortalama değerini girmek
E
Kayıtlardaki diğer değişkenler yardımıyla kayıp verilerin tahmin edilmesi
Açıklama:
Kayıp verilerin neden olacağı olumsuzlukları ortadan kaldırmak amacıyla kullanılan yaklaşımlar şu şekildedir: a)Kayıp veri içeren kaydı veri kümesinden çıkarmak b)Kayıp verileri tek tek yazmak c)Kayıp verilerin hepsi için aynı veriyi girmek d)Kayıp veri yerine tüm verilerin ortalama değerinin girilmesi e)Kayıtlarda yer alan diğer değişkenler yardımıyla kayıp verilerin tahmin edilmesi. Bu nedenle doğru cevap A'dır.
Soru 8
Elde var olan mevcut sınıflanmış veriler kullanarak yeni bir verinin mevcut sınıflardan herhangi birine girme olasılığını hesaplayan yönteme ne ad verilir?
Seçenekler
A
Genetik algoritmalar
B
Zaman serisi analizi
C
Yapay sinir ağları
D
Bayes sınıflandırması
E
Karar ağaçları
Açıklama:
Elde var olan mevcut sınıflanmış veriler kullanarak yeni bir verinin mevcut sınıflardan herhangi birine girme olasılığını hesaplayan yönteme bayes sınıflandırması denilmektedir. Bu nedenle doğru cevap D seçeneğidir.
Soru 9
Farklı özelliklerin ortaya çıkma sıklığı hakkındaki bilgiye ne ad verilir?
Seçenekler
A
Sığ bilgi
B
Gizli bilgi
C
Çok boyutlu bilgi
D
Derin bilgi
E
Meta bilgi
Açıklama:
Farklı özelliklerin ortaya çıkma sıklığı hakkındaki bilgiye çok boyutlu bilgi denilmektedir. Bu nedenle doğru cevap C'dir.
Soru 10
Satış tahmininin yapılması veri madenciliğinin hangi alandaki uygulamalarına bir örnektir?
Seçenekler
A
Finans
B
Sağlık
C
Endüstri
D
Eğitim
E
Pazarlama
Açıklama:
Satış tahmininin yapılması veri madenciliğinin pazarlama alanındaki uygulamalarına örnek olarak verilebilir. Bu nedenle doğru cevap E'dir.
Soru 11
I. Yatay düzlem veri modeli
II. Hiyerarşik veri modeli
III. Perseptron veri modeli
IV. Ağ veri modeli
Yukarıdakilerden hangileri ilk veri modellerindendir?
II. Hiyerarşik veri modeli
III. Perseptron veri modeli
IV. Ağ veri modeli
Yukarıdakilerden hangileri ilk veri modellerindendir?
Seçenekler
A
Yalnız I
B
I ve II
C
I ve III
D
II ve IV
E
Yalnız III
Açıklama:
Zaman içinde giderek büyüyen veri tabanlarının organizasyonu, düzenlenmesi ve yönetimi de doğal olarak zorlaşmıştır. Bu zorlukların üstesinden gelebilmek amacıyla ise veri modelleme kavramı ortaya atılmıştır. İlk veri modelleri; Hiyerarşik Veri Modeli ve Ağ Veri Modeli olarak adlandırılan basit veri modelleridir.
Soru 12
Aşağıdakilerden hangileri veri miktarının sürekli katlanarak arttığı veri tabanları içinden, faydalı bilgilerin nasıl çıkarılabileceği konusunda gerçekleştirilen çalışmaların ilki olarak öne çıkmaktadır?
Seçenekler
A
KPP
B
ERP
C
CRM
D
KDD
E
ERA
Açıklama:
1990’lara gelindiğinde ise artık araştırma konusu; veri miktarının sürekli katlanarak arttığı veri tabanları içinden, faydalı bilgilerin nasıl çıkarılabileceği konusudur. Bu amaç- la pek çok çalışma ve yayın yapılmıştır. Bu çalışmalardan en önemlisi, 1989’da yapılan KDD (Knowledge Discovery in Database) IJCAI-89 Veri Tabanlarında Bilgi Keşfi Çalışma Grubu toplantısıdır. 1991 yılında ise KDD (IJCAI)-89’un sonuç bildirgesi sayılabilecek “Knowledge Discovery in Real Databases: A Report on the IJCAI-89 Workshop” makalesi ile Bilgi Keşfi ve Veri Madenciliği ile ilgili temel tanım ve kavramlar ortaya konmuştur.
Soru 13
I. Felsefe
II. Ekonomi
III. İstatistik
IV. Görselleştirme
Yukarıdakilerden hangileri veri madenciliğine etki eden disiplinlerdendir?
II. Ekonomi
III. İstatistik
IV. Görselleştirme
Yukarıdakilerden hangileri veri madenciliğine etki eden disiplinlerdendir?
Seçenekler
A
I ve III
B
II ve III
C
III ve IV
D
I ve IV
E
Yalnız III
Açıklama:
Veri madenciliğine doğrudan etki eden disiplinler istatistik, makine öğrenimi, görselleştirme, veri tabanı sistemleri ve örüntü tanımadır.
Soru 14
I. Sıralama
II. Açığa çıkarma
III. Keşfetme
IV. Çoğaltma
Yukarıdakilerin hangileri verinin bilgiye dönüşme sürecindeki aşamalardandır?
II. Açığa çıkarma
III. Keşfetme
IV. Çoğaltma
Yukarıdakilerin hangileri verinin bilgiye dönüşme sürecindeki aşamalardandır?
Seçenekler
A
II ve IV
B
I ve IV
C
II ve III
D
III ve IV
E
Yalnız III
Açıklama:
Bilgi ise en yalın tanımıyla verinin işlenmiş ve dönüştürülmüş halidir. Söz konusu işleme ve dönüştürme süreci, veri üzerinde kaydetme, sınıflama, sıralama, hesaplama, özetleme, çoğaltma, analiz ve raporlama işlemlerinin uygulanması ile gerçekleştirilir.
Soru 15
Veri madenciliği için ilk yazılım ne zaman geliştirilmiştir?
Seçenekler
A
1992
B
1960
C
1952
D
1980
E
1990
Açıklama:
Veri madenciliği için ilk yazılım, 1992 yılında geliştirilmiştir. Doğru cevap A'dır.
Soru 16
Veri madenciliğinin tarihsel gelişiminde 1980'lerin önemi nedir?
Seçenekler
A
İlk bilgisayarlar ortaya çıkmıştır
B
Büyük miktarda veri içeren veri tabanları geliştirilmiştir
C
Tüm alanlar için veri madenciliği uygulamaları ortaya çıkmıştır
D
Veri madenciliği için ilk yazılım geliştirilmiştir
E
İlişkisel Veritabanı Yönetim Sistemleri geliştirilmiştir
Açıklama:
1980'lerde büyük miktarda veri içeren veri tabanları ve SQL soru dili geliştirilmesi veri madenciliğinin tarihsel gelişimindeki önemli gelişmelerdir. Doğru cevap B'dir.
Soru 17
I. İşlemsel veri tabanı
II. Veri
III. Veri ambarı
IV. Veri tabanı
Yukarıdakilerden hangileri veri madenciliği çalışmaları yapmak için var olması gereken temel ögelerdir?
II. Veri
III. Veri ambarı
IV. Veri tabanı
Yukarıdakilerden hangileri veri madenciliği çalışmaları yapmak için var olması gereken temel ögelerdir?
Seçenekler
A
II ve IV
B
II ve III
C
I ve II
D
Yalnız III
E
I ve IV
Açıklama:
Veri madenciliği çalışmaları yapmak için var olması gereken iki temel öge veri ve veri- tabanıdır. Bununla birlikte burada sözü edilen veritabanı, işletmelerin günlük kayıtlarının yer aldığı ve işlemsel veritabanı olarak adlandırılan veri tabanları değildir.
Soru 18
1990'lardan sonra, ilgilenilen verinin yığınlar içinden çekilip çıkarılması ve analizinin yapılarak kullanımına hazır hale getirilmesi sürecinde veri madenciliğine büyük katkıları olmuştur.
Yukarıda bahsedilen disiplin aşağıdakilerden hangisidir?
Yukarıda bahsedilen disiplin aşağıdakilerden hangisidir?
Seçenekler
A
Makine öğrenimi
B
Veritabanı sistemleri
C
İstatistik
D
Görselleştirme
E
Örüntü Tanıma
Açıklama:
İstatistik, verilerin analizi ve değerlendirilmesi konusunda geçmişten günümüze yoğun bir biçimde kullanılan bir disiplindir. İstatistiksel çalışmaların bilgisayar desteğiyle daha güçlü biçimde yapılması, daha önce gerçekleştirilmesi çok mümkün olmayan istatistiksel araştırmaları ve analizleri yapılabilir hâle getirmiştir. Bu anlamda 1990’lardan sonra, ilgilenilen verinin yığınlar içinden çekilip çıkarılması ve analizinin yapılarak kullanıma hazır hâle getirilmesi sürecinde istatistik, veri madenciliği ile ortak bir platformda ve sıkı bir çalışma birlikteliği içinde olmuştur. Doğru cevap C'dir.
Soru 19
I. Büyük miktarda veri içerisinden anlamlı ve yararlı ilişki kurallarını ortaya çıkarmak
II. Elde edilen bilgi ile kâr sağlamak
III. Veriler arasındaki örüntüleri ve ilişkileri keşfetmek
IV. Topluma faydalı olacak verileri ortaya koyabilmek
Yukarıdakilerden hangileri veri madenciliğinin tanımını oluşturan özelliklerdendir?
II. Elde edilen bilgi ile kâr sağlamak
III. Veriler arasındaki örüntüleri ve ilişkileri keşfetmek
IV. Topluma faydalı olacak verileri ortaya koyabilmek
Yukarıdakilerden hangileri veri madenciliğinin tanımını oluşturan özelliklerdendir?
Seçenekler
A
I ve IV
B
II ve III
C
I ve III
D
III ve IV
E
Yalnız IV
Açıklama:
- Veri madenciliği, büyük miktardaki veri yığınları üzerinde analiz yaparak veriler ara- sında var olan ve geleceğin tahmin edilmesine yardımcı olacak anlamlı ve yararlı ilişki ve kuralların bilgisayar yazılımları aracılığıyla aranması faaliyetleridir.
- Veri madenciliği, çeşitli analiz araçlarını kullanarak veriler arasındaki örüntü (desen) ve ilişkileri keşfederek, bunları doğru tahminler yapmak için kullanan bir süreçtir.
- Veri madenciliği, veri analizi için, gelişmiş ve karmaşık araçlar kullanarak yığın veri kümeleri içinden daha önceden bilinmeyen olgu ve olayları keşfetmek ve veriler arasındaki mantıklı ilişkileri ve kalıpları ortaya çıkarmak amacıyla yapılan çalışmalardır.
- Veri madenciliği, istatistiksel ve matematiksel tekniklerle birlikte örüntü tanıma tekno- lojilerini kullanarak çeşitli depolama ortamlarında kayıtlı bulunan veri yığınları üzerinde gerçekleştirilen elemeler sonucunda anlamlı yeni korelasyon, örüntü ve eğilimlerin keş- fedilmesi sürecidir.
- Yığın veri içinden anlamlı ilişkiler çıkarma ve yararlı bilgilere dönüştürme işlemine zaman içerisinde; bilgi çıkarımı, enformasyon keşfi, enformasyon hasadı, veri arkeolojisi, veri örüntü işleme, veri şablon işleme gibi farklı isimler verilmiştir.
- Burada belirtilmesi gereken diğer bir nokta, veri madenciliği kavramı ile veritabanla- rında bilgi keşfi kavramının zaman zaman aynı anlamda kullanıldığıdır. Ancak bu doğru bir kullanım değildir. Çünkü veri madenciliği, veritabanlarında bilgi keşfi sürecinin yalnızca bir adımıdır.
Soru 20
Aşağıdakilerden hangisi veritabanı yönetim sisteminin özelliklerinden biri değildir?
Seçenekler
A
Veritabanı oluşturmak
B
Veritabanının bakımını yapmak
C
Veritabanının farklı kullanıcı yetkilerini belirlemek
D
Veritabanını görselleştirmek
E
Veritabanında işlem yapmak
Açıklama:
Veritabanını görselleşmek, veritabanı yönetim sisteminin özelliklerinden biri değildir. Doğru cevap D'dir.
Soru 21
I. Modelin kurulması
II. Amacın tanımlanması
III. Modelin izlenmesi
IV. Veriler üzerinde ön işlemlerin yapılması
Yukarıdakilerden hangileri veri madeciliği öncesinde gerçekleştirilen işlemlerdendir?
II. Amacın tanımlanması
III. Modelin izlenmesi
IV. Veriler üzerinde ön işlemlerin yapılması
Yukarıdakilerden hangileri veri madeciliği öncesinde gerçekleştirilen işlemlerdendir?
Seçenekler
A
I ve II
B
II ve III
C
I ve III
D
II ve IV
E
III ve IV
Açıklama:
Veri madenciliği öncesindeki işlemler; veri tabanlarında bilgi keşfi sürecinin ilk iki aşaması olan, amacın tanımlanması ve veriler üzerinde ön işlemlerin yapılması aşamalarına karşılık gelmektedir.
Veri madenciliği işlemlerinin kendisi, modelin kurulması ve değerlendirilmesi aşamasında gerçekleştirilen faaliyetlerdir.
Veri madenciliği sonrasındaki işlemler ise modelin kullanılması ve yorumlanması ile modelin izlenmesi aşamalarındaki işlemlerdir.
Veri madenciliği işlemlerinin kendisi, modelin kurulması ve değerlendirilmesi aşamasında gerçekleştirilen faaliyetlerdir.
Veri madenciliği sonrasındaki işlemler ise modelin kullanılması ve yorumlanması ile modelin izlenmesi aşamalarındaki işlemlerdir.
Soru 22
"Büyük hacimli verilerin işlenmesi için geliştirilmiş algoritmalar ile geleneksel veri analiz yöntemlerinin karması olan teknolojiye ........... denir."
Yukarıdaki cümlede boş bırakılan yere uygun olan kavram hangisidir?
Yukarıdaki cümlede boş bırakılan yere uygun olan kavram hangisidir?
Seçenekler
A
Veri analizi
B
Veri madenciliği
C
Veri modeli
D
Veri toplama
E
Veri inceleme
Açıklama:
Veri madenciliği büyük hacimli verilerin işlenmesi için geliştirilmiş algoritmalar ile geleneksel veri analiz yöntemlerinin karması olan bir teknolojidir.
Soru 23
I. Regresyon
II. Kümeleme
III. İstisna analizi
IV. Genetik algoritmalar
Yukarıdakilerden hangileri veri madenciliğinde kullanılan tahmin edici modellerdendir?
II. Kümeleme
III. İstisna analizi
IV. Genetik algoritmalar
Yukarıdakilerden hangileri veri madenciliğinde kullanılan tahmin edici modellerdendir?
Seçenekler
A
I ve III
B
II ve III
C
I ve IV
D
III ve IV
E
Yalnız IV
Açıklama:
Veri madenciliğinde kullanılan modeller; tahmin edici modeller ve tanımlayıcı modeller olmak üzere temelde iki başlık altında incelenebilir. Tahmin edici modeller; regresyon, sınıflandırma, karar ağaçları, Bayes sınıflandırması, hatayı geri yayma, karar destek makineleri, k-en yakın komşu, yapay sinir ağları, genetik algoritmalar, zaman seri analizi ve diğer metotlar olarak öne çıkmaktadır. Tanımlayıcı modeller ise, kümeleme, birliktelik kuralları, sıra örüntü analizi, özetleme, tanımlayıcı istatistik, istisna analizi ve diğer metotlardır.
Soru 24
Aşağıdakilerden hangisi veri madenciliğinde kullanılan tanımlayıcı modellerden biridir?
Seçenekler
A
Karar ağaçları
B
Tanımlayıcı istatistik
C
Zaman serisi analizi
D
Hatayı geri yayma
E
Bayes sınıflandırması
Açıklama:
Veri madenciliğinde kullanılan modeller; tahmin edici modeller ve tanımlayıcı modeller olmak üzere temelde iki başlık altında incelenebilir. Tahmin edici modeller; regresyon, sınıflandırma, karar ağaçları, Bayes sınıflandırması, hatayı geri yayma, karar destek makineleri, k-en yakın komşu, yapay sinir ağları, genetik algoritmalar, zaman seri analizi ve diğer metotlar olarak öne çıkmaktadır. Tanımlayıcı modeller ise, kümeleme, birliktelik kuralları, sıra örüntü analizi, özetleme, tanımlayıcı istatistik, istisna analizi ve diğer metotlardır.
Soru 25
Aşağıdakilerdir hangisi, veritabanlarında bilgi keşif sürecinde izlenmesi gereken temel aşamalardan birisi değildir?
Seçenekler
A
Amacın tanımlanması
B
Veriler üzerinde ön işlemlerin yapılması
C
Modelin kurulması ve değerlendirilmesi
D
Modelin kullanılması ve yorumlanması
E
Verilerin yayımlanması
Açıklama:
Açıklama: Veritabanlarında Bilgi Keşfi sürecinde izlenmesi gereken temel aşamalar:
- Amacın tanımlanması
- Veriler üzerinde ön işlemlerin yapılması
- Modelin kurulması ve değerlendirilmesi
- Modelin kullanılması ve yorumlanması
- Modelin izlenmesi
Soru 26
Veritabanlarında bilgi keşif sürecinde en fazla zaman alan aşama hangisidir?
Seçenekler
A
Amacın tanımlanması
B
Modelin kurulması ve değerlendirilmesi
C
Veriler üzerinde ön işlemlerin yapılması
D
Modelin kullanılması ve yorumlanması
E
Modelin İzlenmesi
Açıklama:
Açıklama: Veriler üzerinde yapılan ön işlemler, veri tabanlarında bilgi keşfi sürecinin en fazla zaman alan aşamasıdır.
Soru 27
Verinin bir anlam oluşturacak şekilde düzenlenmiş haline ne ad verilir?
Seçenekler
A
Kümeleme
B
Veri Bankası
C
İstatistik
D
Enformasyon
E
Veri Düzeneği
Açıklama:
Enformasyon, verinin bir anlam oluşturacak şekilde düzenlenmiş halidir.
Soru 28
Aşağıdakilerden hangisi veritabanlarında bilgi keşif sürecinde izlenmesi gereken temel aşamalardan birisi olan; veriler üzerinde yapılan ön işlemlerin aşamalarından birisi değildir?
Seçenekler
A
Verilerin toplanması ve birleştirilmesi
B
Verilerin ortak havuzdan çekilmesi
C
Kayıp veriler için işlem yapılması
D
Verilerdeki gürültünün temizlenmesi
E
Verilerin yeniden yapılandırılması
Açıklama:
Veriler Üzerinde Yapılan Ön İşlemler
- Verilerin toplanması ve birleştirilmesi
- Verilerin temizlenmesi
- Kayıp veriler için işlem yapılması
- Verilerdeki gürültünün temizlenmesi
- Verilerin yeniden yapılandırılması
- Verilerin normalizasyonu
- Verilerin azaltılması
- Verilerin dönüştürülmesi
Soru 29
Veri toplama sürecinde yanlış araçların kullanması, veri girişinde hataların yapılması ve veri toplama aşamasında sorulara eksik cevap verilmesi sonucu ortaya çıkan veriye ne ad verilir?
Seçenekler
A
İşlenmiş veri
B
Depolanmış veri
C
Dönüştürülmüş veri
D
Normalizasyonu yapılmış veri
E
Kayıp veri
Açıklama:
Kayıp veri, veritabanlarındaki kayıtlarda eksik olan verilerdir. Veri toplamada yanlış araçların kullanılması, veri girişinde hata yapılması yada veri toplama aşamasında sorulara eksik cevap verilmesi bu nedenlerden bazılarıdır.
Soru 30
Aşağıda verilenlerden hangisi, kayıp verilerin neden olacağı olumsuzlukları ortadan kaldırmak amacıyla kullanılan yaklaşımlardan birisi değildir?
Seçenekler
A
Kayıp veri içeren kaydı veri kümesinden çıkarmak
B
Kayıp verilerin olduğu düşünülen dosyayı silmek
C
Kayıp verilerin hepsi için aynı veriyi girmek
D
Kayıp veri yerine tüm verilerin ortalama değerinin girilmesi:
E
Kayıtlarda yer alan diğer değişkenler yardımıyla kayıp verilerin tahmin edilmesi
Açıklama:
Kayıp verilerin neden olacağı olumsuzlukları ortadan kaldırmak amacıyla kullanılan
yaklaşımlar:
yaklaşımlar:
- Kayıp veri içeren kaydı veri kümesinden çıkarmak
- Kayıp verileri tek tek yazmak:
- Kayıp verilerin hepsi için aynı veriyi girmek
- Kayıp veri yerine tüm verilerin ortalama değerinin girilmesi:
- Kayıtlarda yer alan diğer değişkenler yardımıyla kayıp verilerin tahmin edilmesi:
Soru 31
Veri ambarlarında aykırı veriyi bulma ve düzeltme için, verilerdeki gürültünün temizlenmesi yaklaşımlarından hangisi kullanılır?
Seçenekler
A
Bölümleme yöntemi yaklaşımı
B
Sınır değerleri yaklaşımı
C
Kümeleme yöntemi yaklaşımı
D
Regresyon yöntemiyle yaklaşımı
E
Ayıklama yöntemi yaklaşımı
Açıklama:
Kümeleme yöntemi yaklaşımı: aykırı değerlerin ortaya çıkarılması ve düzeltilmesinde kullanılır. Buna göre, veri setinde yer alan veriler birbirlerine olan benzerlik ve yakınlıklarına göre kümelere ayrılır. Bu kümeleme işlemi sırasında uç değer olarak kabul edilen bazı veriler hiçbir küme içinde yer alamayacaktır. Bu şekilde belirlenen her bir aykırı değere, en yakın olduğu kümenin ortalama değeri veya en küçük ya da en büyük değeri atanarak aykırı veriler temizlenmiş olur.
Soru 32
Aşağıda verilen ve veri madenciliğinde kullanılan modellerden hangisi, sınıflandırma modelleri arasında yer almaz?
Seçenekler
A
Sıra Örüntü Analizi
B
Genetik Algoritmalar
C
Hatayı Geri Yayma
D
Yapay Sinir Ağları
E
Zaman Serisi Analizi
Açıklama:
Veri Madenciliğinde Kullanılan Sınıflandırma Modelleri:
- Karar Ağaçları
- Bayes Sınandırması
- Hatayı Geri Yayma
- Karar Destek Makineleri
- k-En Yakın Komsu
- Yapay Sinir Ağları
- Genetik Algoritmalar
- Zaman Serisi Analizi
Soru 33
Aşağıda verilen veri madenciliği uygulama konularından hangisi, eğitim alanında yapılan veri madenciliği uygulama konularından değildir?
Seçenekler
A
Öğrenci verilerinin analiz edilmesi
B
Öğrenci başarı ve başarısızlık nedenlerinin tespit edilmesi
C
Üretim süreçlerinin kontrol edilmesi ve tespit edilmesi
D
Eğitim-öğretim ortamlarındaki aksaklıkların tespit edilmesi
E
Daha etkili eğitim-öğretim ortamlarının oluşturulması
Açıklama:
Eğitim alanında yapılan veri madenciliği uygulama konuları:
- Öğrenci verilerinin analiz edilmesi
- Öğrenci başarı ve başarısızlık nedenlerinin tespit edilmesi
- Öğrenci başarılarının arttırılması
- Eğitim-öğretim ortamlarındaki aksaklıkların tespit edilmesi
- Daha etkili eğitim-öğretim ortamlarının oluşturulması
Soru 34
Zaman içinde giderek büyüyen veri tabanlarının düzenlenmesi için üretilen, ilk basit veri modelleri hangileridir?
Seçenekler
A
Hiyerarşik veri modeli ve hipodermik veri modeli
B
Örümcek veri modeli ve hiyerarşik veri modeli
C
Hiyerarşik veri modeli ve ağ veri modeli
D
Sıra örüntü analizi modeli ve veri madenciliği modeli
E
Veri madenciliği modeli ve veri işçiliği modeli
Açıklama:
Zaman içinde giderek büyüyen veri tabanlarının organizasyonu, düzenlenmesi ve yönetimi de doğal olarak zorlaşmıştır. Bu zorlukların üstesinden gelebilmek amacıyla ise veri modelleme kavramı ortaya atılmıştır. Ilk veri modelleri; Hiyerarşik Veri Modeli ve Ağ Veri Modeli olarak adlandırılan basit veri modelleridir.
Soru 35
İşletmelerin varlığını sürdürebilmesi için yöneticilerinin doğru kararları ve doğru stratejileri belirlemesi için bilgiyi hangi koşullarda elde etmelidir?
Seçenekler
A
Doğru yer
B
Doğru zaman
C
Doğru kişi
D
Doğru karar
E
Doğru strateji
Açıklama:
İletişim ve bilişim teknolojilerinde yaşanan gelişmeler dünyada her şeyin hızla değişmesine neden olmaktadır. İster kâr amaçlı işletmeler, ister diğer kurum ve kuruluşlar açısından olsun, değişimlere ayak uydurabilmek başarı için önemli bir gerekliliktir. İşletmeler açısından ele alındığında bu değişimler; ekonomik koşullarda, iş yapma biçimlerinde, müşteri beklentilerinde, müşteri eğilimlerinde, rakiplerin stratejilerinde vb. ortaya çıkmaktadır. İşletmelerin bu değişimlere ayak uydurabilmesi, rakipleriyle yarışabilmesi ve varlıklarını başarılı bir biçimde sürdürebilmesi için, işletmelerde karar verici konumunda olan yöneticilerin, doğru kararlar vererek doğru stratejiler belirlemeleri gerekmektedir. Bu da ancak zamanında elde edilebilen doğru bilgilerin kullanımıyla mümkün olacaktır.
Soru 36
Veri madenciliğinin tarihsel süreci içerisinde düşünüldüğünde veri tabanı kavramı hangi amaçla ortaya çıkmıştır?
Seçenekler
A
Veri düzeni
B
Eksik verileri tamamlama
C
Verilerin depolanması
D
Verilerin kayıt altına alınması
E
Veri aktarımı
Açıklama:
Veri madenciliğinin tarihi bilgisayarların hayatımıza girmesiyle başlamıştır. 1950’li yıllardaki ilk bilgisayarların geliştirilme ve kullanım amacı sayım ve karmaşık hesaplamaları kolaylıkla yapabilmekti. Daha sonra kullanıcıların ihtiyaçları doğrultusunda, bilgisayarlar veri depolama işlemleri için de kullanılmaya başlanmıştır. Verilerin depolanması ihtiyacı ile birlikte, 1960’lı yıllardan itibaren teknoloji dünyası veri tabanı kavramı ile tanışmıştır.
Soru 37
Veri madenciliğine etki eden disiplinler düşünüldüğünde verilerin analizi ve değerlendirilmesi işlemlerini gerçekleştiren disiplin seçeneklerden hangisidir?
Seçenekler
A
Makine öğrenimi
B
Görselleştirme
C
Örüntü tanıma
D
Veritabanı sistemleri
E
İstatistik
Açıklama:
İstatistik, verilerin analizi ve değerlendirilmesi konusunda geçmişten günümüze yoğun bir biçimde kullanılan bir disiplindir. Bilgisayar sistemlerinde hem donanım hem de yazılım alanında sağlanan gelişmeler doğal olarak istatistik alanını da etkilemiştir. İstatistiksel çalışmaların bilgisayar desteğiyle daha güçlü biçimde yapılması, daha önce gerçekleştirilmesi çok mümkün olmayan istatistiksel araştırmaları ve analizleri yapılabilir hâle getirmiştir. Bu anlamda 1990’lardan sonra, ilgilenilen verinin yığınlar içinden çekilip çıkarılması ve analizinin yapılarak kullanıma hazır hâle getirilmesi sürecinde istatistik, veri madenciliği ile ortak bir platformda ve sıkı bir çalışma birlikteliği içinde olmuştur.
Soru 38
Veri madenciliğine etki eden disiplinler düşünüldüğünde verilerin işlenmesinde algoritmalar aracılığıyla sonuçlar elde edilmesi işlemlerini gerçekleştiren disiplin seçeneklerden hangisidir?
Seçenekler
A
İstatistik
B
Veritabanı sistemleri
C
Görselleştirme
D
Örüntü tanıma
E
Makine öğrenimi
Açıklama:
Makine öğrenimi bilgisayarların kendisine algoritmalar yoluyla verilen kuralları uygulaması ve büyük veri kümeleri içinden örnekler çıkararak verileri bu kurallara göre sınıflamaları, tanımlamaları ve dolayısıyla öğrenmeleri olarak ifade edilebilir. Bu öğrenmeler sonucunda çıkarımlarda bulunarak geçmiş veri örnekleri yardımıyla gelecekte daha iyi sonuçlar üretme konusunda veri madenciliği uygulamasına katkıda bulunurlar.
Soru 39
Veri madenciliğine etki eden disiplinler düşünüldüğünde verilerin tablo ve grafikler ile sunulmasını sağlayan disiplin seçeneklerden hangisidir?
Seçenekler
A
Makine öğrenimi
B
İstatistik
C
Görselleştirme
D
Örüntü tanıma
E
Veritabanı sistemleri
Açıklama:
Veri madenciliğinde söz konusu diğer bir disiplin olan görselleştirme; verilerin, tablolar ve grafikler gibi görseller yardımıyla sunulmasını sağlayan teknolojileri ifade eder.
Görselleştirme; verilerin daha kolay anlaşılmasına, analiz edilmesine ve geleceğe yönelik tahminlerde bulunulmasına önemli katkı sağlamaktadır.
Görselleştirme; verilerin daha kolay anlaşılmasına, analiz edilmesine ve geleceğe yönelik tahminlerde bulunulmasına önemli katkı sağlamaktadır.
Soru 40
Veri madenciliğine etki eden disiplinler düşünüldüğünde verilerin depolanmasını ve kullanıcıların veriler üzerinde işlem yapmasına olanak sağlayan disiplin seçeneklerden hangisidir?
Seçenekler
A
Makine öğrenimi
B
İstatistik
C
Görselleştirme
D
Veritabanı sistemleri
E
Örüntü tanıma
Açıklama:
Veri madenciliğinin olmazsa olmazlarından biri de veritabanlarıdır. Bilindiği gibi işletmelerde ve yapısal diğer tüm kurumlarda günlük işlemler ve bu işlemlere konu olan veriler kaydedilmektedir. Bununla birlikte veritabanı kavramı gelişigüzel veri yığınları olmayıp birbiriyle ilişkili olan ve amaca uygun biçimde düzenlenmiş, mantıksal ve fiziksel olarak tanımlanmış veriler bütünüdür. Veritabanı yönetim sistemi ise kısaca veritabanı tanımlamak, veritabanı oluşturmak, veritabanında işlem yapmak, veritabanının farklı kullanıcı yetkilerini belirlemek, veritabanının bakımını ve yedeklemesini yapmak için geliştirilmiş programlar bütünüdür. Son olarak, veritabanı ve veri tabanı yönetim sisteminin birlikte oluşturduğu bütün de veritabanı sistemi olarak ifade edilir.
Soru 41
Veri madenciliğine etki eden disiplinler düşünüldüğünde verilerin düzenli ve sistematik bir biçimde sıralanmasını saptayan disiplin seçeneklerden hangisidir?
Seçenekler
A
Örüntü tanıma
B
Makine öğrenimi
C
İstatistik
D
Veritabanı sistemleri
E
Görselleştirme
Açıklama:
Örüntü, olaylar ve nesneler arasında düzenli ve sistematik bir biçimde tekrarlanan ilişki modellerini ifade etmek için kullanılan bir kavramdır. Örüntü tanıma teknolojisi ise daha önceden tanımlanmış, bir model olarak düşünülebilen çok boyutlu bir örüntünün veritabanındaki benzerlerini ya da en benzerini arama ve bulma amacına yönelik yazılımları ifade eder. Örüntünün konusu yazılı bir metin olabileceği gibi parmak izi, ses, yüz tanıma, kan hücrelerinin karşılaştırılması, el yazılarının belirlenmesi gibi alanlar da olabilir. Verilen son örneklerde örüntü, el, yüz, resim, çizim ve ses gibi nesnelerin bilgisayar ortamlarında sayısal olarak ifade edilmesi anlamındadır.
Soru 42
Harf, rakam ya da çeşitli sembol ve işaretler ile temsil edilen ham gözlemler, işlenmemiş gerçekler ya da izlenimler ifadesi seçeneklerdeki kavramlardan hangisinin tanımıdır?
Seçenekler
A
Veri madenciliği
B
Veritabanı
C
Makine öğrenimi
D
Veri
E
Veri yönetimi
Açıklama:
Veri, ham gözlemler, işlenmemiş gerçekler ya da izlenimlerdir. Bu gözlemler, gerçekler ya da izlenimler harf, rakam ya da çeşitli sembol ve işaretler yardımıyla temsil edilir.
Soru 43
"İşletmelerde iç veri kaynakları ile dış veri kaynaklarının birleştirilmesi ve düzenlenmesi ile oluşturulmuş, üzerinde veri madenciliği işlemlerinin gerçekleştirileceği veriyi sağlar" ifadesi seçeneklerden hangisinin tanımıdır?
Seçenekler
A
Veritabanı
B
Veritabanı sistemleri
C
Veri işleme
D
Makine öğrenmesi
E
Veri ambarı
Açıklama:
Veri ambarı işletmelerde iç veri kaynakları ile dış veri kaynaklarının birleştirilmesi ve düzenlenmesi ile oluşturulmuş, üzerinde veri madenciliği işlemlerinin gerçekleştirileceği veriyi sağlayan daha geniş ve özel veritabanlarına verilen isimdir.
Soru 44
Veritabanlarında bilgi keşfi süreci adımları düşünüldüğünde verilerin toplanması, birleştirilmesi, temizlenmesi ve yeniden yapılandırılması işlemleri hangi adımda gerçekleştirilir?
Seçenekler
A
Amacın Tanımlanması
B
Veriler Üzerinde Ön İşlemlerin Yapılması
C
Modelin Kurulması ve Değerlendirilmesi
D
Modelin Kullanılması ve Yorumlanması
E
Modelin İzlenmesi
Açıklama:
Veriler üzerindeki ön işlemler genel olarak;
• Verilerin toplanması ve birleştirilmesi,
• Verilerin temizlenmesi,
• Verilerin yeniden yapılandırılması
biçiminde sınıflandırılabilir.
• Verilerin toplanması ve birleştirilmesi,
• Verilerin temizlenmesi,
• Verilerin yeniden yapılandırılması
biçiminde sınıflandırılabilir.
Soru 45
"İşletmelerde iç veri kaynakları ile dış veri kaynaklarının birleştirilmesi ve düzenlenmesi ile oluşturulmuş, üzerinde veri madenciliği işlemlerinin gerçekleştirileceği veriyi sağlayan daha geniş ve özel veritabanlarına verilen isimdir."
Yukarıda tanım hangi kavramı anlatmaktadır?
Yukarıda tanım hangi kavramı anlatmaktadır?
Seçenekler
A
Veri ambarı
B
Veri madenciliği
C
Veri tabanı
D
Veri yönetimi
E
Veri girişi
Açıklama:
Yukarıdaki tanım veri ambarını anlatmaktadır. Doğru cevap A'dır.
Soru 46
Bir veri ambarında yer alan veriler hakkındaki bilgiler hangi ögeden elde edilmektedir?
Seçenekler
A
İç kaynak
B
Üst veri
C
Veri
D
Veri deposu
E
OLAP
Açıklama:
İngilizce karşılığı meta data olan üst veri, veri ambarında yer alan veriler hakkındaki tanımlamalar olup veri ambarına ilişkin veri kataloğu olarak düşünülebilir. Doğru cevap B'dir.
Soru 47
Farklı kadife, keten, saten olmak üzere kumaş türleri üreten bir fabrikanın, önceki ay kadife kumaştan ne kadar satıldığını öğrenilebilmesi için veri sisteminde hangi sistemi kullanılması gerekmektedir?
Seçenekler
A
Veritabanı sorgulaması
B
Veri ambarı incelemesi
C
OLAP sorgulama işlemi
D
Veri madenciliği
E
Veri çekme
Açıklama:
Çok yönlü veri analizi ve sorgulama yapmak istediklerinde normal veri analizi ve sorgulamadan farklı bir sistem kullanırlar. Çevrimiçi Analitik İşleme olarak adlandırılan bu sisteme kısaca OLAP (OnLine Analytical Processing) denir. OLAP uygulamaları veri ambarından çekilen veriler üzerinde gerçekleştirilir. OLAP sorgulamaları işlemsel veri tabanlarında gerçekleştirilen basit analiz ve sorgulamalardan farklı olarak, veriyi çok boyutlu biçimde analiz eder ve analiz sonucunda yöneticilere stratejik kararlarında destek olacak yararlı bilgiler sunar. Çözüm için OLAP sorgulama işleminin yapılması gerekmektedir. Doğru cevap C'dir.
Soru 48
"Veriden örüntülerin çıkarılması amacıyla çeşitli algoritmaların uygulanmasıdır."
Yukarıdaki cümle hangi kavramı tanımlamaktadır?
Yukarıdaki cümle hangi kavramı tanımlamaktadır?
Seçenekler
A
OLAP
B
Veri
C
İç Kaynak
D
Dış Kaynak
E
Veri Madenciliği
Açıklama:
Veri madenciliği, veriden örüntülerin çıkarılması amacıyla çeşitli algoritmaların uygulanmasıdır. Doğru cevap E'dir.
Soru 49
Aşağıdakilerden hangisi OLAP'ı tanımlamaktadır?
Seçenekler
A
Veri ambarında yer alan veriler üzerinde çok boyutlu, çok yönlü analiz ve sorgulama yapılmasını sağlayan sistemlerdir.
B
Büyük miktardaki veri yığınları üzerinde analiz yaparak veriler arasında var olan ve geleceğin tahmin edilmesine yardımcı olacak anlamlı ve yararlı ilişki ve kuralların bilgisayar yazılımları aracılığıyla aranması faaliyetleridir.
C
Çeşitli analiz araçlarını kullanarak veriler arasındaki örüntü ve ilişkileri keşfederek bunları doğru tahminler yapmak için kullanan bir süreçtir.
D
Veri analizi için gelişmiş ve karmaşık araçlar kullanarak yığın veri kümeleri içinden daha önceden bilinmeyen olgu ve olayları keşfetmek ve veriler arasındaki mantıklı ilişkileri ve kalıpları ortaya çıkarmak amacıyla yapılan çalışmalardır.
E
İstatistiksel ve matematiksel tekniklerle birlikte örüntü tanıma teknolojilerini kullanarak çeşitli depolama ortamlarında kayıtlı bulunan veri yığınları üzerinde gerçekleştirilen elemeler sonucunda anlamlı yeni korelasyon, örüntü ve eğilimlerin keşfedilmesi sürecidir.
Açıklama:
Veri ambarında yer alan veriler üzerinde çok boyutlu, çok yönlü analiz ve sorgulama yapılmasını sağlayan sistemler OLAP'tır. Doğru cevap A'dır.
Soru 50
- Amacın tanımlanması
- Modelin izlenmesi
- Modelin kurulması ve değerlendirilmesi
- Modelin kullanılması ve yorumlanması
- Veri üzerinde ön işlemlerin yapılması
Yukarıdakilerden hangileri veri madenciliğinin sonrasındaki işlemlerdendir?
Seçenekler
A
I ve II
B
II ve III
C
III ve V
D
II ve IV
E
III ve IV
Açıklama:
"Modelin kullanılması ve yorumlanması" ve "modelin izlenmesi" veri madenciliği sonrasında yapılan işlemlerdendir. Doğru cevap D'dir.
Soru 51
Farklı değerlerdeki verilerin 0,0-1,0 gibi aralıklardaki değerlerle temsil edilmesi işlemine ______________ denir?
Seçenekler
A
Ortalama
B
Varyans
C
Hipotez
D
Normalizasyon
E
Akış
Açıklama:
Farklı değerlerdeki verilerin 0,0-1,0 gibi aralıklardaki değerlerle temsil edilmesi işlemine normalizasyon denir.
Soru 52
_____________, insan öğrenmesinde söz konusu olan özelliklerin algoritmalar yardımıyla bilgisayarlara da uygulanabileceği ve bilgisayarların da insanlar gibi öğrenebileceği düşüncesini temel alan bir disiplindir.
Seçenekler
A
Fare arayüzü
B
Klavye
C
İstatistik
D
Veri
E
Makine öğrenmesi
Açıklama:
Makine öğrenimi, insan öğrenmesinde söz konusu olan özelliklerin algoritmalar yardımıyla bilgisayarlara da uygulanabileceği ve bilgisayarların da insanlar gibi öğrenebileceği düşüncesini temel alan bir disiplindir.
Soru 53
Seçeneklerden hangisi veri madenciliğinin etkileşimde olduğu disiplinler arasında yer almaz?
Seçenekler
A
İstatistik
B
Görselleştirme
C
Örüntü Tanıma
D
Gümrük
E
Veritabanı sistemleri
Açıklama:
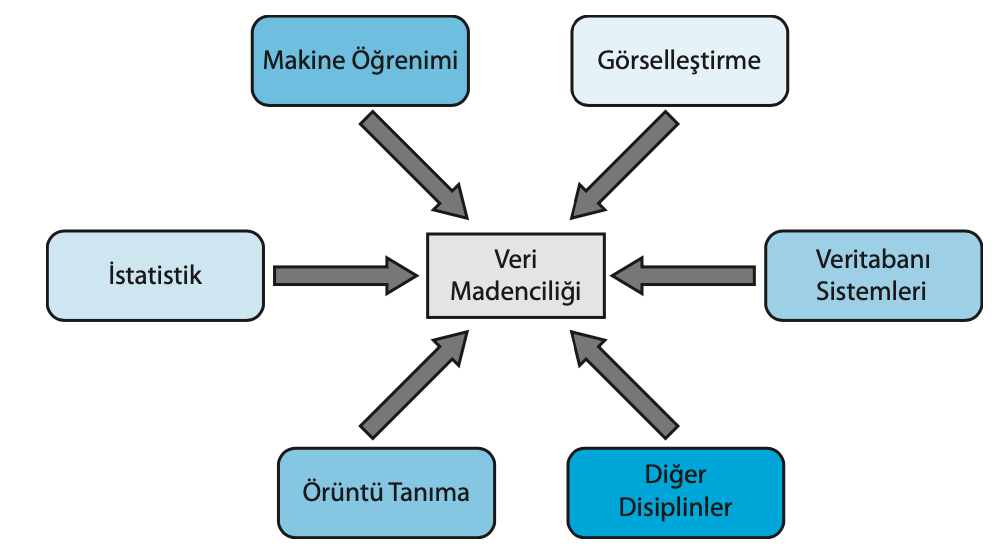
Soru 54
____________ ise en yalın tanımıyla verinin işlenmiş ve dönüştürülmüş halidir?
Seçenekler
A
İnsan
B
Makine
C
Bilgi
D
Veri
E
Deney
Açıklama:
Bilgi ise en yalın tanımıyla verinin işlenmiş ve dönüştürülmüş halidir.
Soru 55
Veri ambarında yer alan veriler üzerinde çok boyutlu,
çok yönlü analiz ve sorgulama yapılmasını sağlayan sistemler nedir?
çok yönlü analiz ve sorgulama yapılmasını sağlayan sistemler nedir?
Seçenekler
A
GLMS
B
OLAP
C
DNS
D
HTTPS
E
VIAD
Açıklama:
Çevrimiçi Analitik İşleme olarak adlandırılan bu sisteme kısaca OLAP (On- Line Analytical Processing) denir. OLAP uygulamaları veri ambarından çekilen veriler üzerinde gerçekleştirilir. OLAP sorgulamaları işlemsel veri tabanlarında gerçekleştirilen basit analiz ve sorgulamalardan farklı olarak, veriyi çok boyutlu biçimde analiz eder ve analiz sonucunda yöneticilere stratejik kararlarında destek olacak yararlı bilgiler sunar.
Soru 56
Seçeneklerden hangisi Veritabanlarında Bilgi Keşfi sürecinde izlenmesi gereken temel aşamalar arasında son aşamada yer alır?
Seçenekler
A
Amacın tanımlanması
B
Modelin İzlenmesi
C
Veriler üzerinde önizleme yapılması
D
Aritmetik ortalama hesaplama
E
Hipotez testi
Açıklama:
Veritabanlarında Bilgi Keşfi sürecinde izlenmesi gereken temel aşamalar aşağıdaki gibi sıralanabilir.
1. Amacın Tanımlanması
2. Veriler Üzerinde Ön İşlemlerin Yapılması
3. Modelin Kurulması ve Değerlendirilmesi
4. Modelin Kullanılması ve Yorumlanması
5. Modelin İzlenmesi
1. Amacın Tanımlanması
2. Veriler Üzerinde Ön İşlemlerin Yapılması
3. Modelin Kurulması ve Değerlendirilmesi
4. Modelin Kullanılması ve Yorumlanması
5. Modelin İzlenmesi
Soru 57
Veri madenciliği _____________ işlemler ise modelin kullanılması ve yorumlanması ile modelin izlenmesi aşamalarındaki işlemlerdir.
Seçenekler
A
beraberindeki
B
öncesindeki
C
kendisi
D
sonrasındaki
E
belirsizliğindeki
Açıklama:
Veri madenciliği sonrasındaki işlemler ise modelin kullanılması ve yorumlanması ile modelin izlenmesi aşamalarındaki işlemlerdir.
Soru 58
Veriler üzerinde yapılan ön işlemler göz önüne alındığında seçeneklerden hangisi verilerin temizlenmesi aşamasında yer alır?
Seçenekler
A
Normalizasyon
B
Azaltma
C
Dönüştürme
D
Kayıp veri işlemi
E
Veri birleştirme
Açıklama:
Veri temizleme aşamasında kayıp (eksik) veri, gürültülü veri ve tutarsızlıklar giderilir. Doğru cevap D.
Soru 59
Aşağıdakilerden hangisi 1957 yılında Frank Rosenblatt tarafından geliştirilen ve tekrar eden, benzerlik gösteren özelliklerin bilgisayar tarafından algılanabilmesini sağlayan bir algoritmadır?
Seçenekler
A
Destek Vektör Makineleri
B
K-En Yakın Komşu
C
Perseptron
D
Yapay Sinir Ağları
E
Naive Bayes
Açıklama:
Perseptron, insan beyninde yer alan sinir hücrelerinin (nöronların) ilk yapay modeline verilen isim olup algılayıcı, fark edici anlamındadır. 1957 yılında Frank Rosenblatt tarafından geliştirilen ve tekrar eden, benzerlik gösteren özelliklerin bilgisayar tarafından algılanabilmesini sağlayan bir algoritmadır.
Soru 60
Hangi tarihten itibaren teknoloji dünyası veri tabanı kavramı ile tanışmıştır?
Seçenekler
A
1940
B
1950
C
1960
D
1970
E
1980
Açıklama:
Verilerin depolanması ihtiyacı ile birlikte, 1960’lı yıllardan itibaren teknoloji dünyası veri tabanı kavramı ile tanışmıştır.
Soru 61
Aşağıdakilerden hangisi olaylar ve nesneler arasında daha önceden tanımlanmış, düzenli ve sistematik biçimde tekrar eden ilişkileri bir model olarak kabul eden ve bu modelin (örüntünün) benzerlerini ya da en benzerini veritabanı içinden arama ve bulmaya yönelik teknolojidir?
Seçenekler
A
Yapay Sinir Ağları
B
Destek Vektör Makineleri
C
Örüntü Tanıma
D
Perseptron
E
Çevrimiçi Analitik İşleme
Açıklama:
Örüntü tanıma: Olaylar ve nesneler arasında daha önceden tanımlanmış, düzenli ve sistematik biçimde tekrar eden ilişkileri bir model olarak kabul eden ve bu modelin (örüntünün) benzerlerini ya da en benzerini veritabanı içinden arama ve bulmaya yönelik teknolojidir.
Soru 62
Aşağıdakilerden hangisi işletmelerde iç veri kaynakları ile dış veri kaynaklarının birleştirilmesi ve düzenlenmesi ile oluşturulmuş, üzerinde veri madenciliği işlemlerinin gerçekleştirileceği veriyi sağlayan daha geniş ve özel veritabanlarına verilen isimdir?
Seçenekler
A
SQL
B
Veri Ambarı
C
Hard Disk
D
İç Veri Kaynakları
E
Dış Veri Kaynakları
Açıklama:
Veri ambarı işletmelerde iç veri kaynakları ile dış veri kaynaklarının birleştirilmesi ve düzenlenmesi ile oluşturulmuş, üzerinde veri madenciliği işlemlerinin gerçekleştirileceği veriyi sağlayan daha geniş ve özel veritabanlarına verilen isimdir.
Soru 63
Aşağıdakilerden hangisi veri ambarında yer alan veriler üzerinde çok boyutlu, çok yönlü analiz ve sorgulama yapılmasını sağlayan sistemlerdir?
Seçenekler
A
SQL
B
C#
C
JAVA
D
OLAP
E
Perseptron
Açıklama:
OLAP (Online Analytical Processing - Çevrimiçi Analitik İşleme) veri ambarında yer alan veriler üzerinde çok boyutlu, çok yönlü analiz ve sorgulama yapılmasını sağlayan sistemlerdir.
Soru 64
Veriden örüntülerin çıkarılması amacıyla çeşitli algoritmaların uygulanmasına ne ad verilir?
Seçenekler
A
Veri ambarı
B
Veri madenciliği
C
Veri birleştirme
D
Çevrim içi analitik işleme
E
Veri Temizleme
Açıklama:
Veri madenciliği, veriden örüntülerin çıkarılması amacıyla çeşitli algoritmaların uygulanmasıdır. Elde edilen örüntü ve kurallar karar vermeye ve bu kararların sonuçlarını tahmin etmeye destek olacak biçimde kullanılabilecektir.
Soru 65
Aşağıdakilerden hangisi veritabanlarında bilgi keşfi sürecinde izlenmesi gereken temel aşamalardan birisidir?
Seçenekler
A
Modelin İzlenmesi
B
Veriler Üzerinde Ön İşlemlerin Yapılması
C
Modelin Kurulması ve Değerlendirilmesi
D
Modelin Kullanılması ve Yorumlanması
E
Hepsi
Açıklama:
Veritabanlarında Bilgi Keşfi sürecinde izlenmesi gereken temel aşamalar aşağıdaki gibi sıralanabilir.
1. Amacın Tanımlanması 2. Veriler Üzerinde Ön İşlemlerin Yapılması 3. Modelin Kurulması ve Değerlendirilmesi 4. Modelin Kullanılması ve Yorumlanması 5. Modelin İzlenmesi
1. Amacın Tanımlanması 2. Veriler Üzerinde Ön İşlemlerin Yapılması 3. Modelin Kurulması ve Değerlendirilmesi 4. Modelin Kullanılması ve Yorumlanması 5. Modelin İzlenmesi
Soru 66
Veritabanlarındaki kayıtlarda eksik olan verilere ne ad verilir?
Seçenekler
A
Anlamsız veri
B
Yanlış veri
C
Kötü veri
D
Kayıp veri
E
Hasarlı veri
Açıklama:
Kayıp veri, veritabanlarındaki kayıtlarda eksik olan verilerdir. Kayıp veriler çeşitli nedenlerden kaynaklanabilir; veri toplamada yanlış araçların kullanılması, veri girişinde hata yapılması ya da veri toplama aşamasında sorulara eksik cevap verilmesi bu nedenlerden bazılarıdır.
Soru 67
Aşağıdakilerden hangisinde ilgili örneklerin gözlenmesi ve bu örneklerin özellikleri arasındaki benzerliklerden hareket ederek sınıfların tanımlanması amaçlanmaktadır?
Seçenekler
A
Tahmin analizleri
B
Sınıflama Analizi
C
Kümeleme analizi
D
Regresyon analizleri
E
Zaman serisi analizi
Açıklama:
Denetimsiz öğrenmede, kümeleme analizinde olduğu gibi ilgili örneklerin gözlenmesi ve bu örneklerin özellikleri arasındaki benzerliklerden hareket ederek sınıfların tanımlanması amaçlanmaktadır.
Soru 68
Aşağıdakilerden hangisi elde var olan, mevcut sınıflanmış verileri kullanarak yeni bir verinin mevcut sınıflardan herhangi birine girme olasılığını hesaplayan yöntemdir?
Seçenekler
A
Genetik Algoritmalar
B
Doğrusal Regresyon
C
Destek Vektör Makineleri
D
Yapay Sinir Ağları
E
Bayes sınıflandırması
Açıklama:
Bayes sınıflandırması: Bayes sınıflandırma yöntemi, elde var olan, mevcut sınıflanmış verileri kullanarak yeni bir verinin mevcut sınıflardan herhangi birine girme olasılığını hesaplayan yöntemdir.
Soru 69
Veri tabanı kavramı aşağıdaki yıllardan hangisi itibariyle ortaya çıkmıştır?
Seçenekler
A
1950ler
B
1960lar
C
1970ler
D
1980ler
E
1990lar
Açıklama:
Verilerin depolanması ihtiyacı ile birlikte, 1960’lı yıllardan itibaren teknoloji dünyası veri tabanı kavramı ile tanışmıştır.
Soru 70
"İnsan beyninde yer alan sinir hücrelerinin (nöronların) ilk yapay modeline verilen isim olup algılayıcı, fark edici anlamında kullanılan kavrama ............ denir."
Yukarıdaki boş bırakılan alana gelmesi gereken uygun kavram hangisidir?
Yukarıdaki boş bırakılan alana gelmesi gereken uygun kavram hangisidir?
Seçenekler
A
Veri tabanı
B
Ağ bağlantısı
C
Veri analizi
D
Perseptron
E
İletim sistemi
Açıklama:
Perseptron, insan beyninde yer alan sinir hücrelerinin (nöronların) ilk yapay modeline verilen
isim olup algılayıcı, fark edici anlamındadır. 1957 yılında Frank Rosenblatt tarafından geliştirilen ve tekrar eden, benzerlik gösteren özelliklerin bilgisayar tarafından algılanabilmesini sağlayan bir algoritmadır.
isim olup algılayıcı, fark edici anlamındadır. 1957 yılında Frank Rosenblatt tarafından geliştirilen ve tekrar eden, benzerlik gösteren özelliklerin bilgisayar tarafından algılanabilmesini sağlayan bir algoritmadır.
Soru 71
I. Hiyerarşik veri modeli
II. Ağ analizi modeli
III. Ağ veri modeli
IV. Veri depolama modeli
Yukarıdakilerden hangisi ilk veri modellerindendir?
II. Ağ analizi modeli
III. Ağ veri modeli
IV. Veri depolama modeli
Yukarıdakilerden hangisi ilk veri modellerindendir?
Seçenekler
A
I, II ve III
B
I ve III
C
II ve IV
D
Yalnız III
E
II ve III
Açıklama:
Zaman içinde giderek büyüyen veri tabanlarının organizasyonu, düzenlenmesi ve yönetimi de doğal olarak zorlaşmıştır. Bu zorlukların üstesinden gelebilmek amacıyla ise veri modelleme kavramı ortaya atılmıştır. İlk veri modelleri; Hiyerarşik Veri Modeli ve Ağ Veri Modeli olarak adlandırılan basit veri modelleridir.
Soru 72
Veri madenciliği açısından ilk yazılım ne zaman geliştirilmiştir?
Seçenekler
A
1972
B
1982
C
1992
D
2002
E
2012
Açıklama:
1992 yılında veri madenciliği için ilk yazılım geliştirilmiştir.
Soru 73
I. Mekatronik
II. İstatistik
III. Örüntü tanıma
IV. Güzel sanatlar
Yukarıdakilerden hangileri veri madenciliğinin etkileşimde olduğu disiplinlerdir?
II. İstatistik
III. Örüntü tanıma
IV. Güzel sanatlar
Yukarıdakilerden hangileri veri madenciliğinin etkileşimde olduğu disiplinlerdir?
Seçenekler
A
I ve II
B
II ve III
C
III ve IV
D
I ve III
E
II ve IV
Açıklama:
Veri madenciliğinin etkileşimde olduğu disiplinler;
- İstatistik
- Makine Öğrenimi
- Göreselleştirme
- Örüntü tanıma
- Veri tabanı sistemleri
- Diğer disiplinler
Soru 74
"Verinin bir anlam oluşturacak şekilde düzenlenmiş hâline .......... denir."
Yukarıdaki boş bırakılan alana gelmesi gereken uygun kavram hangisidir?
Yukarıdaki boş bırakılan alana gelmesi gereken uygun kavram hangisidir?
Seçenekler
A
Bilgi
B
Veri
C
Analiz
D
Tecrübe
E
Enformasyon
Açıklama:
Enformasyon, verinin bir anlam oluşturacak şekilde düzenlenmiş hâlidir.
Soru 75
"Büyük miktardaki veri yığınları üzerinde analiz yaparak veriler arasında var olan ve geleceğin tahmin edilmesine yardımcı olacak anlamlı ve yararlı ilişki ve kuralların bilgisayar yazılımları aracılığıyla aranması faaliyetlere ......... denir."
Yukarıdaki boş bırakılan alana gelmesi gereken uygun kavram hangisidir?
Yukarıdaki boş bırakılan alana gelmesi gereken uygun kavram hangisidir?
Seçenekler
A
Bilgi
B
Enformasyon
C
Veri madenciliği
D
Bilgi arkeolojisi
E
Data analizi
Açıklama:
Veri madenciliği, büyük miktardaki veri yığınları üzerinde analiz yaparak veriler arasında var olan ve geleceğin tahmin edilmesine yardımcı olacak anlamlı ve yararlı ilişki ve kuralların bilgisayar yazılımları aracılığıyla aranması faaliyetleridir.
Soru 76
I. Yapay sinir ağları
II. Sıra örüntü analizi
III. Zaman serisi analizi
IV. İstisna analizi
Yukarıdakilerden hangisi veri madenciliğinde tanımlayıcı modellerdendir?
II. Sıra örüntü analizi
III. Zaman serisi analizi
IV. İstisna analizi
Yukarıdakilerden hangisi veri madenciliğinde tanımlayıcı modellerdendir?
Seçenekler
A
I ve II
B
II ve III
C
III ve IV
D
I ve III
E
II ve IV
Açıklama:
Veri Madenciliği Modelleri
Veri Madenciliği Modellerinin Sınıflandırılması
Tahmin Edici (Predictive)
Regresyon (Regression)
Sınıflandırma (Classification)
Karar Ağaçları (Decision Trees)
Bayes Sınıflandırması (Bayesian Classification)
Hatayı Geri Yayma (Backpropagation)
Karar Destek Makineleri (Support Vector Machines)
k-En Yakın Komşu (k- nearest Neighbour)
Yapay Sinir Ağları (Neural Networks)
Genetik Algoritmalar (Genetic Algorithms)
Zaman Serisi Analizi (Time Series Analysis)
Diğer Metotlar (Other Methods)
Tanımlayıcı (Descriptive)
Kümeleme (Clustering)
Birliktelik Kuralları (Association Rules)
Özetleme (Summaerization)
Sıra örüntü analizi (Sequence Analysis)
İstisna Analizi (Outlier Analysis)
Diğer Metotlar (Other Methods)
Veri Madenciliği Modellerinin Sınıflandırılması
Tahmin Edici (Predictive)
Regresyon (Regression)
Sınıflandırma (Classification)
Karar Ağaçları (Decision Trees)
Bayes Sınıflandırması (Bayesian Classification)
Hatayı Geri Yayma (Backpropagation)
Karar Destek Makineleri (Support Vector Machines)
k-En Yakın Komşu (k- nearest Neighbour)
Yapay Sinir Ağları (Neural Networks)
Genetik Algoritmalar (Genetic Algorithms)
Zaman Serisi Analizi (Time Series Analysis)
Diğer Metotlar (Other Methods)
Tanımlayıcı (Descriptive)
Kümeleme (Clustering)
Birliktelik Kuralları (Association Rules)
Özetleme (Summaerization)
Sıra örüntü analizi (Sequence Analysis)
İstisna Analizi (Outlier Analysis)
Diğer Metotlar (Other Methods)
Soru 77
Aşağıdakilerden hangisi veri madenciliğinde tahmin edici modellerdendir?
Seçenekler
A
Tanımlayıcı istatistik
B
Yapay sinir ağları
C
Kümeleme
D
İstisna analizi
E
Birliktelik kuralları
Açıklama:
Sorunun doğru cevabını 19. sayfadaki tablodan kontrol edebilirsiniz.
Soru 78
Aşağıdakilerden hangisi veri madenciliğinin yoğun olarak kullanıldığı alanlardan biri değildir?
Seçenekler
A
Pazarlama
B
Finans
C
Eğitim
D
Tarım
E
Genetik
Açıklama:
Veri madenciliğinin yoğun ve başarılı bir biçimde kullanıldığı başlıca alanlar; pazarlama, finans (bankacılık, sigortacılık, borsa), parekendecilik, sağlık, telekomünikasyon, endüstri ve mühendislik, eğitim, tıp, biyoloji, genetik, kamu, istihbarat ve güvenlik biçiminde sıralanabilir.
Soru 79
Olaylar ve nesneler arasında daha önceden tanımlanmış, düzenli ve sistematik biçimde tekrar eden ilişkileri bir model olarak kabul eden ve bu modelin benzerlerini ya da en benzerini veritabanı içinden arama ve bulmaya yönelik teknolojiye ne ad verilir?
Seçenekler
A
İstatistik
B
Makine Öğrenmesi
C
Örüntü Tanıma
D
Veri Tabanı
E
Görselleştirme
Açıklama:
Söz konusu tanım, örüntü tanıma ile açıklanabilir.
Soru 80
İç veri ve dış veri kaynaklarının bir araya gelmesiyle oluşturulmuş ve üzerinde veri madenciliği işlemlerinin gerçekleştirilebileceği veriyi sağlayan veritabanlarına ne ad verilir?
Seçenekler
A
Veri ambarı
B
Veri deposu
C
İstatistiksel öğrenme
D
Üst veri
E
Örüntü
Açıklama:
Veri madenciliği işlemlerinin yürütüldüğü çok büyük veritabanlarına veri ambarı adı verilir.
Soru 81
MEB'in yönetim bilgi sisteminde sorgu yapan bir uzman, Türkiye'deki tüm 9. sınıf öğrencilerinin ilk dönem birinci matematik sınav notlarını raporlarken, 143 öğrencinin 100'ün üzerinde puan aldığını görmüştür.
Bu 143 birimin oluşturduğu veriye ne ad verilir?
Bu 143 birimin oluşturduğu veriye ne ad verilir?
Seçenekler
A
Kayıp veri
B
Gürültülü veri
C
Büyük veri
D
Değerli veri
E
Değişken veri
Açıklama:
Öğrencilerin alabileceği en yüksek sınav puanı 100'dür. Veri setinin doğasına uygun olmayan bu tip aşırı uç veriler "gürültü" olarak adlandırılır.
Soru 82
Değişkenler arasındaki yordayıcı ilişkiye dayalı olarak verideki gürültünün temizlenmesine dayalı yönteme ne ad verilir?
Seçenekler
A
Bölümleme
B
Kümeleme
C
Sınır değer
D
Regresyon
E
En yakın komşular
Açıklama:
Söz konusu yöntem, gürültünün temizlenmesinde kullanılan yöntemlerden regresyondur.
Soru 83
Bir araştırmacı yürüttüğü veri madenciliği sürecinde değişkenlerden bir kısmının 25-185, bir kısmının 5-12, kalan kısmının ise 0-50 arasında değerler aldığını görmüştür.
Araştırmacı, analizlerinin değişkenlerin ölçek düzeylerinin farklılığından etkilenmemesi için aşağıdaki yöntemlerden hangisini uygulamalıdır?
Araştırmacı, analizlerinin değişkenlerin ölçek düzeylerinin farklılığından etkilenmemesi için aşağıdaki yöntemlerden hangisini uygulamalıdır?
Seçenekler
A
Normalizasyon
B
Azaltma
C
Dönüştürme
D
Çevirme
E
Harmanlama
Açıklama:
Farklı ölçek düzeylerindeki verilerin aynı ölçek düzeyine getirilerek analizlerdeki olası yanlılığın engellenmesi normalizasyon ile mümkündür.
Soru 84
Bir araştırmacı, belirlediği bir veri setinde yanıt aradığı sorusuna çözüm üretmek için bir algoritma eğitmiştir. Ancak bu algoritmanın aynı amaçla kullanılan başka bir veri setinde beklenen sonucu vermediği, öğrenmenin gerçekleştiği veri setinden çok daha kötü çıkarımlarda bulunduğu görülmüştür.
Bu duruma ne ad verilir?
Bu duruma ne ad verilir?
Seçenekler
A
Aşırı öğrenme
B
Çapraz geçerlik
C
En yakın komşular
D
İstatistiksel öğrenme
E
Yapay sinir ağları
Açıklama:
Bir algoritma sadece öğrendiği-eğitildiği veri setinde iyi bir performans sergiliyorsa, bu durum aşırı öğrenme adını alır.
Soru 85
Ozan, telefonunun fotoğraflar bölümünde yeni bir klasör açıldığını ve en çok fotoğraf çektirdiği arkadaşlarının her biri için yeni bir klasör oluştuğunu görmüştür.
Klasörler isimsiz olduğuna göre, kullanılan veri madenciliği modeli aşağıdakilerden hangisi olabilir?
Klasörler isimsiz olduğuna göre, kullanılan veri madenciliği modeli aşağıdakilerden hangisi olabilir?
Seçenekler
A
Karar ağaçları
B
Kümeleme
C
Yapay sinir ağları
D
k-en yakın komşular
E
Regresyon
Açıklama:
Söz konusu durumda, algoritma için bir öğrenme referansı yoktur. Verileri, benzer özellliklerine göre gruplamıştır. Bu nedenle bir denetimsiz öğrenme yöntemidir. Seçenekler arasındaki tek denetimsiz öğrenme yöntemi kümeleme yöntemidir.
Soru 86
"Öklid" ve "Manhattan" benzeri uzaklık ölçülerini temel alan denetimli öğrenme yöntemi aşağıdakilerden hangisidir?
Seçenekler
A
k-en yakın komşular
B
Bayes
C
Regresyon
D
Karar ağaçları
E
Rassal orman
Açıklama:
Nesnelerin birbirine olan uzaklıklarının baz alındığı denetimli öğrenme yöntemi k-en yakın komşular yöntemidir.
Soru 87
"Kola alanlar %70 ihtimalle cips de alılar" biçiminde bir dönüt veren veri madenciliği yöntemi aşağıdakilerden hangisidir?
Seçenekler
A
Kümeleme
B
Özetleme
C
Sıra örüntü analizi
D
Birliktelik kuralları
E
Lojistik regresyon
Açıklama:
Söz konusu yöntem, birliktelik kuralları olarak adlandırılır.
Soru 88
Bir çevrimiçi öğrenme platformu yöneticisi, platforma kayıt olan öğrencilerin büyük kısmının bir süre sonra derslere devam etmediğini görmüş ve gelecekte bu durumu engellemek adına bir çalışma başlatmıştır. Buna göre eldeki veri setinden yola çıkarak gelecekte bırakma potansiyeli olan öğrencilerin belirlenmesi ve bunlar üzerinde özel bir çalışma yürütülmesi amaçlanmaktadır.
Yönetici bu amaçla aşağıdaki yöntemlerden hangisini kullanabilir?
Yönetici bu amaçla aşağıdaki yöntemlerden hangisini kullanabilir?
Seçenekler
A
İstisna
B
Karar ağaçları
C
Kümeleme
D
Özetleme
E
Sıra örüntü
Açıklama:
Soruda yer alan örnek bir tahmin edici modelin geliştirilmesini gerekmektedir. Seçenekler arasında yer alan tek tahmin modeli karar ağaçları yöntemidir. Doğru cevap B.
Soru 89
........... , 1957 yılında Frank Rosenblatt tarafından geliştirilen ve tekrar eden, benzerlik gösteren özelliklerin bilgisayar tarafından algılanabilmesini sağlayan bir
algoritmadır.
Yukarıdaki cümlede boş bırakılan yeri aşağıdakilerden hangisi doğru şekilde tamamlar?
algoritmadır.
Yukarıdaki cümlede boş bırakılan yeri aşağıdakilerden hangisi doğru şekilde tamamlar?
Seçenekler
A
Perseptron
B
Örüntü tanıma
C
Veri ambarı
D
Çevrimiçi analitik işleme
E
Kayıp veri
Açıklama:
Perseptron, 1957 yılında Frank Rosenblatt tarafından geliştirilen ve tekrar eden, benzerlik gösteren özelliklerin bilgisayar tarafından algılanabilmesini sağlayan bir algoritmadır.
Dolayısıyla, doğru cevap A şıkkıdır.
Dolayısıyla, doğru cevap A şıkkıdır.
Soru 90
Veri madenciliği için ilk yazılım hangi tarihte gerçekleştirilmiştir?
Seçenekler
A
1989
B
1990
C
1991
D
1992
E
2000
Açıklama:
1990’lara gelindiğinde ise artık araştırma konusu; veri miktarının sürekli katlanarak arttığı veri tabanları içinden, faydalı bilgilerin nasıl çıkarılabileceği konusudur. Bu amaçla pek çok çalışma ve yayın yapılmıştır. Bu çalışmalardan en önemlisi, 1989’da yapılan KDD (Knowledge Discovery in Database) IJCAI-89 Veri Tabanlarında Bilgi Keşfi Çalışma Grubu toplantısıdır. 1991 yılında ise KDD (IJCAI)-89’un sonuç bildirgesi sayılabilecek “Knowledge Discovery in Real Databases: A Report on the IJCAI-89 Workshop” makalesi ile Bilgi Keşfi ve Veri Madenciliği ile ilgili temel tanım ve kavramlar ortaya konmuştur. Bu makaleden sonra süreç daha da hızlanmış ve 1992 yılında veri madenciliği için ilk yazılım geliştirilmiştir.
Dolayısıyla doğru cevap D şıkkıdır.
Dolayısıyla doğru cevap D şıkkıdır.
Soru 91
........... , veritabanlarındaki kayıtlarda eksik olan verilerdir.
Yukarıdaki cümlede boş bırakılan yeri aşağıdakilerden hangisi doğru bir şekilde tamamlar?
Yukarıdaki cümlede boş bırakılan yeri aşağıdakilerden hangisi doğru bir şekilde tamamlar?
Seçenekler
A
Kayıp veri
B
Aykırı değer
C
Gürültülü veri
D
Yanlış veri
E
Veri kümesi
Açıklama:
Kayıp veri, veritabanlarındaki kayıtlarda eksik olan verilerdir. Veritabanlarında doğru olmayacak kadar uç değerler, aykırı değer ya da sıra dışı değer olarak
tanımlanır. Bu şekildeki aykırı değerler ya da farklı sebeplerle yanlış girilmiş değerler genel olarak gürültülü veri olarak tanımlanır.
Dolayısıyla, doğru cevap A şıkkıdır.
tanımlanır. Bu şekildeki aykırı değerler ya da farklı sebeplerle yanlış girilmiş değerler genel olarak gürültülü veri olarak tanımlanır.
Dolayısıyla, doğru cevap A şıkkıdır.
Soru 92
.............. , istatistiksel ve matematiksel tekniklerle birlikte örüntü tanıma teknolojilerini kullanarak çeşitli depolama ortamlarında kayıtlı bulunan veri yığınları üzerinde gerçekleştirilen elemeler sonucunda anlamlı yeni korelasyon, örüntü ve eğilimlerin keşfedilmesi sürecidir.
Yukarıdaki cümlede boş bırakılan yeri aşağıdakilerden hangisi doğru şekilde tamamlar?
Yukarıdaki cümlede boş bırakılan yeri aşağıdakilerden hangisi doğru şekilde tamamlar?
Seçenekler
A
Aykırı değer
B
Denetimli öğrenme
C
Veri madenciliği
D
Gürültülü veri
E
Kayıp veri
Açıklama:
Kayıp veri, veritabanlarındaki kayıtlarda eksik olan verilerdir.
Veritabanlarında doğru olmayacak kadar uç değerler, aykırı değer ya da sıra dışı değer olarak tanımlanır. Bu şekildeki aykırı değerler ya da farklı sebeplerle yanlış girilmiş değerler genel olarak gürültülü veri olarak tanımlanır.
Veri madenciliği ise, istatistiksel ve matematiksel tekniklerle birlikte örüntü tanıma teknolojilerini kullanarak çeşitli depolama ortamlarında kayıtlı bulunan veri yığınları üzerinde gerçekleştirilen elemeler sonucunda anlamlı yeni korelasyon, örüntü ve eğilimlerin keşfedilmesi sürecidir.
Dolayısıyla, doğru cevap C şıkkıdır.
Veritabanlarında doğru olmayacak kadar uç değerler, aykırı değer ya da sıra dışı değer olarak tanımlanır. Bu şekildeki aykırı değerler ya da farklı sebeplerle yanlış girilmiş değerler genel olarak gürültülü veri olarak tanımlanır.
Veri madenciliği ise, istatistiksel ve matematiksel tekniklerle birlikte örüntü tanıma teknolojilerini kullanarak çeşitli depolama ortamlarında kayıtlı bulunan veri yığınları üzerinde gerçekleştirilen elemeler sonucunda anlamlı yeni korelasyon, örüntü ve eğilimlerin keşfedilmesi sürecidir.
Dolayısıyla, doğru cevap C şıkkıdır.
Soru 93
.......... (1), veritabanlarındaki kayıtlarda eksik olan verilerken; veritabanlarındaki doğru olmayacak kadar uç değerler, ......... (2) olarak tanımlanır.
Yukarıdaki cümlede boş bırakılan yerlere aşağıdaki şıklardan hangisi doğru şekilde tamamlar?
Yukarıdaki cümlede boş bırakılan yerlere aşağıdaki şıklardan hangisi doğru şekilde tamamlar?
Seçenekler
A
Aykırı değer/kayıp veri
B
Kayıp veri/aykırı değer
C
Tutarsız değer/gürültülü veri
D
Kayıp veri/tutarsız veri
E
Gürültülü veri/aykırı değer
Açıklama:
Kayıp veri, veritabanlarındaki kayıtlarda eksik olan verilerken; veritabanlarındaki doğru olmayacak kadar uç değerler, aykırı değer olarak tanımlanır.
Aykırı değerler ya da farklı sebeplerle yanlış girilmiş değerler ise, genel olarak gürültülü veri olarak tanımlanır.
Dolayısıyla doğru cevap B şıkkıdır.
Aykırı değerler ya da farklı sebeplerle yanlış girilmiş değerler ise, genel olarak gürültülü veri olarak tanımlanır.
Dolayısıyla doğru cevap B şıkkıdır.
Soru 94
Veri madenciliğinde kullanılan modeller iki başlık altında incelenebilmektedir. Bunlardan biri olan ................ modeller, eldeki verilerden hareketle bir model geliştirilmesi ve geliştirilen bu model kullanılarak önceden sonuçları bilinmeyen veri kümeleri için sonuçların tahmin edilmesini amaçlarken; ................ modeller ise analiz edilen verilerin özelliklerini incelemek için kullanılır. Yukarıdaki cümlede boş bırakılan yeri aşağıdakilerden hangisi doğru şekilde tamamlar?
Seçenekler
A
Tanımlayıcı/tahmin edici
B
Tanımlayıcı/regresyon
C
Sınıflandırma/regresyon
D
Tahmin edici/regresyon
E
Tahmin edici/tanımlayıcı
Açıklama:
Veri madenciliğinde kullanılan modeller;
• Tahmin edici modeller,
• Tanımlayıcı modeller
olmak üzere temelde iki başlık altında incelenebilmektedir. Tahmin edici modeller; eldeki verilerden hareketle bir model geliştirilmesi ve geliştirilen bu model kullanılarak önceden sonuçları bilinmeyen veri kümeleri için sonuçların tahmin edilmesini amaçlar. Tanımlayıcı modeller ise, verilerdeki örüntü veya ilişkileri tanımlar. Bu modeller tahmin edici modellerin aksine analiz edilen verilerin özelliklerini incelemek için kullanılan modellerdir.
Regresyon modelleri ve sınıflandırma modelleri ise, doğrudan tahmin edici modellerin kapsamına girmektedir.
Dolayısıyla doğru cevap E şıkkıdır.
• Tahmin edici modeller,
• Tanımlayıcı modeller
olmak üzere temelde iki başlık altında incelenebilmektedir. Tahmin edici modeller; eldeki verilerden hareketle bir model geliştirilmesi ve geliştirilen bu model kullanılarak önceden sonuçları bilinmeyen veri kümeleri için sonuçların tahmin edilmesini amaçlar. Tanımlayıcı modeller ise, verilerdeki örüntü veya ilişkileri tanımlar. Bu modeller tahmin edici modellerin aksine analiz edilen verilerin özelliklerini incelemek için kullanılan modellerdir.
Regresyon modelleri ve sınıflandırma modelleri ise, doğrudan tahmin edici modellerin kapsamına girmektedir.
Dolayısıyla doğru cevap E şıkkıdır.
Soru 95
I. Bilinenden yola çıkarak bilinmeyeni tahmin etme çabasıdır.
II. Özellikle karar verme süreci açısından büyük önem taşır.
III. Verilerdeki örüntü veya ilişkileri tanımlar.
IV. Analiz edilen verilerin özelliklerini incelemek için kullanılır.
Veri madenciliğinde kullanılan modeller; tahmin edici modeller ve tanımlayıcı modeller olmak üzere temelde iki başlık altında incelenebilmektedir.
Buna göre, yukarıdakilerden hangisi tahmin edici modelleri açıklarken kullanılabilecek doğru bir ifadedir?
II. Özellikle karar verme süreci açısından büyük önem taşır.
III. Verilerdeki örüntü veya ilişkileri tanımlar.
IV. Analiz edilen verilerin özelliklerini incelemek için kullanılır.
Veri madenciliğinde kullanılan modeller; tahmin edici modeller ve tanımlayıcı modeller olmak üzere temelde iki başlık altında incelenebilmektedir.
Buna göre, yukarıdakilerden hangisi tahmin edici modelleri açıklarken kullanılabilecek doğru bir ifadedir?
Seçenekler
A
I ve II
B
I ve III
C
Yalnız II
D
III ve IV
E
Yalnız IV
Açıklama:
Tahmin edici modeller; eldeki verilerden hareketle bir model geliştirilmesi ve geliştirilen bu model kullanılarak önceden sonuçları bilinmeyen veri kümeleri için sonuçların tahmin edilmesini amaçlar. Kısaca bilinenden yola çıkarak bilinmeyeni tahmin etme çabasıdır. Tahmin edici modeller özellikle karar verme süreci açısından büyük önem taşır.
Tanımlayıcı modeller ise, verilerdeki örüntü veya ilişkileri tanımlar. Bu modeller tahmin edici modellerin aksine analiz edilen verilerin özelliklerini incelemek için kullanılan modellerdir.
Dolayısıyla, doğru cevap A şıkkıdır.
Tanımlayıcı modeller ise, verilerdeki örüntü veya ilişkileri tanımlar. Bu modeller tahmin edici modellerin aksine analiz edilen verilerin özelliklerini incelemek için kullanılan modellerdir.
Dolayısıyla, doğru cevap A şıkkıdır.
Soru 96
Veri madenciliğinde kullanılan modeller, temelde iki başlık altında incelenebilir. Bunlardan biri ise, analiz edilen verilerin özelliklerini incelemek için kullanılır.
Bu modelin adı aşağıdaki şıkların hangisinde verilmiştir?
Bu modelin adı aşağıdaki şıkların hangisinde verilmiştir?
Seçenekler
A
Tahmin edici modeller
B
Denetimli öğrenme
C
Tanımlayıcı modeller
D
Sınıflandırma modelleri
E
Denetimsiz öğrenme
Açıklama:
Tahmin edici modeller; eldeki verilerden hareketle bir model geliştirilmesi ve geliştirilen bu model kullanılarak önceden sonuçları bilinmeyen veri kümeleri için sonuçların tahmin edilmesini amaçlar. Sınıflandırma modelleri de, tahmin edici modellerdendir. Tahmin edici modeller de kendisine verilen veritabanını inceler ve bu veritabanındaki temel unsurları birbirine benzeterek tanımlamaya, onları isimlendirmeye ve sınıflamaya çalışır. Burada öğrenme işlevinin denetimli ve denetimsiz öğrenme olarak ikiye ayrılır.
Tanımlayıcı modeller ise, verilerdeki örüntü veya ilişkileri tanımlar. Bu modeller tahmin edici modellerin aksine analiz edilen verilerin özelliklerini incelemek için kullanılan modellerdir.
Dolayısıyla, doğru cevap C şıkkıdır.
Tanımlayıcı modeller ise, verilerdeki örüntü veya ilişkileri tanımlar. Bu modeller tahmin edici modellerin aksine analiz edilen verilerin özelliklerini incelemek için kullanılan modellerdir.
Dolayısıyla, doğru cevap C şıkkıdır.
Soru 97
I. Üretim süreçlerinin kontrol edilmesi
II. Hisse senedi fiyatlarının tahmin edilmesi
III. Kalite kontrol analizlerinin gerçekleştirilmesi
IV. Sigorta dolandırıcılıklarının belirlenmesi
Veri madenciliği bir çok alanda yoğun bir şekilde kullanılmaktadır. Endüstri ve mühendislik alanı da bunlardan biridir.
Yukarıdakilerden hangisi veri madenciliğinin endüstri ve mühendislik alanındaki uygulamalarına örnek teşkil edemez?
II. Hisse senedi fiyatlarının tahmin edilmesi
III. Kalite kontrol analizlerinin gerçekleştirilmesi
IV. Sigorta dolandırıcılıklarının belirlenmesi
Veri madenciliği bir çok alanda yoğun bir şekilde kullanılmaktadır. Endüstri ve mühendislik alanı da bunlardan biridir.
Yukarıdakilerden hangisi veri madenciliğinin endüstri ve mühendislik alanındaki uygulamalarına örnek teşkil edemez?
Seçenekler
A
I ve II
B
I ve III
C
II ve III
D
II, III ve IV
E
II ve IV
Açıklama:
Hisse senedi fiyatlarının tahmin edilmesi ve sigorta dolandırıcılıklarının belirlenmesi veri madenciliğinin finans alanındaki uygulamalarına örnek teşkil etmektedir.
Bu sebeple, doğru cevap E şıkkıdır.
Bu sebeple, doğru cevap E şıkkıdır.
Soru 98
".................., insan beyninde yer alan sinir hücrelerinin (nöronların) ilk yapay modeline verilen isim olup algılayıcı, fark edici anlamındadır. 1957 yılında Frank Rosenblatt tarafından geliştirilen ve tekrar eden, benzerlik gösteren özelliklerin bilgisayar tarafından algılanabilmesini sağlayan bir algoritmadır."
Metinde boş bırakılan yere aşağıdaki seçeneklerden hangisi getirilmelidir?
Metinde boş bırakılan yere aşağıdaki seçeneklerden hangisi getirilmelidir?
Seçenekler
A
Terabyte
B
Perseptron
C
Peta
D
Exa
E
Zetta
Açıklama:
Perseptron, insan beyninde yer alan sinir hücrelerinin (nöronların) ilk yapay modeline verilen isim olup algılayıcı, fark edici anlamındadır. 1957 yılında Frank Rosenblatt tarafından geliştirilen ve tekrar eden, benzerlik gösteren
özelliklerin bilgisayar tarafından algılanabilmesini sağlayan bir algoritmadır.
özelliklerin bilgisayar tarafından algılanabilmesini sağlayan bir algoritmadır.
Soru 99
- İstatistiksel çalışmalar bilgisayar desteğiyle daha güçlü biçimde yapılmaktadır.
- Gerçekleştirilmesi çok mümkün olmayan istatistiksel araştırmaları ve analizleri yapılabilir.
- İlgilenilen verinin yığınlar içinden çekilip çıkarılması ve analizinin yapılarak kullanılabilir.
- Veri madenciliği çalışmalarında etkili olan ve yapay zekâ çalışmalarının da temelini oluşturan istatistiktir.
Seçenekler
A
Yalnız IV
B
II - III
C
III - IV
D
I - II - III
E
I - II - III - IV
Açıklama:
İstatistik, verilerin analizi ve değerlendirilmesi konusunda geçmişten günümüze yoğun bir biçimde kullanılan bir disiplindir. Bilgisayar sistemlerinde hem donanım hem de yazılım alanında sağlanan gelişmeler doğal olarak istatistik alanını da etkilemiştir. İstatistiksel çalışmaların bilgisayar desteğiyle daha güçlü biçimde yapılması, daha önce gerçekleştirilmesi çok mümkün olmayan istatistiksel araştırmaları ve analizleri yapılabilir hâle getirmiştir. Bu anlamda 1990’lardan sonra, ilgilenilen verinin yığınlar içinden çekilip çıkarılması ve analizinin yapılarak kullanıma hazır hâle getirilmesi sürecinde istatistik, veri madenciliği ile ortak bir platformda ve sıkı bir çalışma birlikteliği içinde olmuştur. Veri madenciliği çalışmalarında etkili olan ve yapay zekâ çalışmalarının da temelini oluşturan makine öğrenimi, kısaca bilgisayarların bazı işlemlerden çıkarsamalar yaparak yeni işlemler üretmesi olarak tanımlanabilir.
Soru 100
- Örüntü tanıma
- Veritabanı sistemleri
- Makine öğrenimi
- Görselleştirme
- İstatistik
Seçenekler
A
Yalnız I
B
II - III
C
III - IV - V
D
I - III - IV - V
E
I - II - III - IV - V
Açıklama:
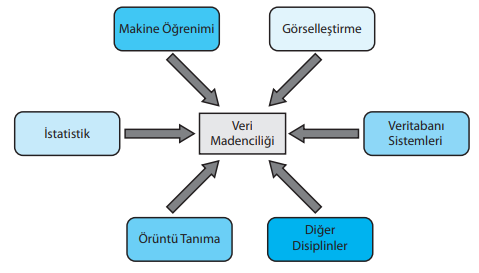 Görselde veri madenciliğinin etkileşimde olduğu disiplinler verilmiştir.
Görselde veri madenciliğinin etkileşimde olduğu disiplinler verilmiştir.Soru 101
"...................., işletmelerde iç veri kaynakları ile dış veri kaynaklarının birleştirilmesi ve düzenlenmesi ile oluşturulmuş, üzerinde veri madenciliği
işlemlerinin gerçekleştirileceği veriyi sağlayan daha geniş ve özel veritabanlarına verilen isimdir."
Metinde verilen boşluğa aşağıdaki seçeneklerden hangisi getirilmelidir?
işlemlerinin gerçekleştirileceği veriyi sağlayan daha geniş ve özel veritabanlarına verilen isimdir."
Metinde verilen boşluğa aşağıdaki seçeneklerden hangisi getirilmelidir?
Seçenekler
A
Veri ambarı
B
Üst veri
C
OLAP sunucusu
D
Meta data
E
Veri tabanı
Açıklama:
Veri ambarı, işletmelerde iç veri kaynakları ile dış veri kaynaklarının birleştirilmesi ve düzenlenmesi ile oluşturulmuş, üzerinde veri madenciliği
işlemlerinin gerçekleştirileceği veriyi sağlayan daha geniş ve özel veritabanlarına verilen isimdir.
işlemlerinin gerçekleştirileceği veriyi sağlayan daha geniş ve özel veritabanlarına verilen isimdir.
Soru 102
Aşağıdakilerden hangisi veri madenciliği kavramına ilişkin tanımlardan değildir?
Seçenekler
A
Veri madenciliği, büyük miktardaki veri yığınları üzerinde analiz yaparak veriler arasında var olan ve geleceğin tahmin edilmesine yardımcı olacak anlamlı ve yararlı ilişki ve kuralların bilgisayar yazılımları aracılığıyla aranması faaliyetleridir.
B
Veri madenciliği, çeşitli analiz araçlarını kullanarak veriler arasındaki örüntü (desen) ve ilişkileri keşfederek, bunları doğru tahminler yapmak için kullanan bir süreçtir.
C
Veri madenciliği sürecinde, işlemsel veritabanlarında depolanmış olan verinin sorgulama ve analiz için uygun hâle getirilmesi işlemleri yürütülür.
D
Veri madenciliği, veri analizi için, gelişmiş ve karmaşık araçlar kullanarak yığın veri kümeleri içinden daha önceden bilinmeyen olgu ve olayları keşfetmek ve veriler arasındaki mantıklı ilişkileri ve kalıpları ortaya çıkarmak amacıyla yapılan çalışmalardır.
E
Veri madenciliği, istatistiksel ve matematiksel tekniklerle birlikte örüntü tanıma teknolojilerini kullanarak çeşitli depolama ortamlarında kayıtlı bulunan veri yığınları üzerinde gerçekleştirilen elemeler sonucunda anlamlı yeni korelasyon, örüntü ve eğilimlerin keşfedilmesi sürecidir.
Açıklama:
Veri madenciliği kavramı için çeşitli tanımlar yapılmıştır. Bu tanımlardan bir kısmı aşağıda verildiği gibidir:
Veri madenciliği, büyük miktardaki veri yığınları üzerinde analiz yaparak veriler arasında var olan ve geleceğin tahmin edilmesine yardımcı olacak anlamlı ve yararlı ilişki ve kuralların bilgisayar yazılımları aracılığıyla aranması faaliyetleridir. Bu anlamda veri madenciliği, çok büyük miktardaki veriler arasındaki bağlantıları inceleyerek aralarındaki ilişkiyi ortaya çıkaran ve veritabanları içinde açıkça fark edilemeyen, gizli kalmış yararlı bilgilerin açığa çıkarılmasını sağlayan veri analizi tekniğidir.
Veri madenciliği, çeşitli analiz araçlarını kullanarak veriler arasındaki örüntü (desen) ve ilişkileri keşfederek, bunları doğru tahminler yapmak için kullanan bir süreçtir. Veri madenciliğinin amacı, geçmiş faaliyetleri analiz ederek bu analizleri geleceğe yönelik tahminlerde temel almak ve karar vermeye destek olacak modeller oluşturmada kullanmaktır. Buna göre veri madenciliği, büyük miktarda veri içinden, gizli kalmış, değeri olan, kullanılabilir bilgileri açığa çıkarmak ve bu bilgileri özellikle stratejik kararlarda destek sağlayacak biçimde elde etmek amacıyla kullanılmaktadır.
Veri madenciliği, veri analizi için, gelişmiş ve karmaşık araçlar kullanarak yığın veri kümeleri içinden daha önceden bilinmeyen olgu ve olayları keşfetmek ve veriler arasındaki mantıklı ilişkileri ve kalıpları ortaya çıkarmak amacıyla yapılan çalışmalardır. Burada vurgulanması gereken önemli nokta, veri madenciliği ile elde edilecek bilginin daha önceden bilinmeyen yeni keşfedilen olmasıdır. Önceden bilinmeyen bilgi, önceden tahmin bile edilemeyen bilgi anlamındadır. Bu anlamda veri madenciliği, tahmin edilen ya da farklı teknikler yardımıyla daha önceden ulaşılmış sonuçların doğruluğunu ispatlamak amacıyla kullanılan bir araç değildir. Diğer tekniklerden temel farkı, daha önce düşünülmemiş hiç akla gelmemiş sonuçları ortaya çıkarmasıdır.
Veri madenciliği, istatistiksel ve matematiksel tekniklerle birlikte örüntü tanıma teknolojilerini kullanarak çeşitli depolama ortamlarında kayıtlı bulunan veri yığınları üzerinde gerçekleştirilen elemeler sonucunda anlamlı yeni korelasyon, örüntü ve eğilimlerin keşfedilmesi sürecidir.
C seçeneği Veritabanlarında Bilgi Keşfi sürecinden bahsetmektedir.
Veri madenciliği, büyük miktardaki veri yığınları üzerinde analiz yaparak veriler arasında var olan ve geleceğin tahmin edilmesine yardımcı olacak anlamlı ve yararlı ilişki ve kuralların bilgisayar yazılımları aracılığıyla aranması faaliyetleridir. Bu anlamda veri madenciliği, çok büyük miktardaki veriler arasındaki bağlantıları inceleyerek aralarındaki ilişkiyi ortaya çıkaran ve veritabanları içinde açıkça fark edilemeyen, gizli kalmış yararlı bilgilerin açığa çıkarılmasını sağlayan veri analizi tekniğidir.
Veri madenciliği, çeşitli analiz araçlarını kullanarak veriler arasındaki örüntü (desen) ve ilişkileri keşfederek, bunları doğru tahminler yapmak için kullanan bir süreçtir. Veri madenciliğinin amacı, geçmiş faaliyetleri analiz ederek bu analizleri geleceğe yönelik tahminlerde temel almak ve karar vermeye destek olacak modeller oluşturmada kullanmaktır. Buna göre veri madenciliği, büyük miktarda veri içinden, gizli kalmış, değeri olan, kullanılabilir bilgileri açığa çıkarmak ve bu bilgileri özellikle stratejik kararlarda destek sağlayacak biçimde elde etmek amacıyla kullanılmaktadır.
Veri madenciliği, veri analizi için, gelişmiş ve karmaşık araçlar kullanarak yığın veri kümeleri içinden daha önceden bilinmeyen olgu ve olayları keşfetmek ve veriler arasındaki mantıklı ilişkileri ve kalıpları ortaya çıkarmak amacıyla yapılan çalışmalardır. Burada vurgulanması gereken önemli nokta, veri madenciliği ile elde edilecek bilginin daha önceden bilinmeyen yeni keşfedilen olmasıdır. Önceden bilinmeyen bilgi, önceden tahmin bile edilemeyen bilgi anlamındadır. Bu anlamda veri madenciliği, tahmin edilen ya da farklı teknikler yardımıyla daha önceden ulaşılmış sonuçların doğruluğunu ispatlamak amacıyla kullanılan bir araç değildir. Diğer tekniklerden temel farkı, daha önce düşünülmemiş hiç akla gelmemiş sonuçları ortaya çıkarmasıdır.
Veri madenciliği, istatistiksel ve matematiksel tekniklerle birlikte örüntü tanıma teknolojilerini kullanarak çeşitli depolama ortamlarında kayıtlı bulunan veri yığınları üzerinde gerçekleştirilen elemeler sonucunda anlamlı yeni korelasyon, örüntü ve eğilimlerin keşfedilmesi sürecidir.
C seçeneği Veritabanlarında Bilgi Keşfi sürecinden bahsetmektedir.
Soru 103
- Amacın Tanımlanması
- Veriler Üzerinde Ön İşlemlerin Yapılması
- Modelin Kullanılması ve Yorumlanması
- Modelin Kurulması ve Değerlendirilmesi
- Modelin İzlenmesi
Seçenekler
A
1 - 2
B
2 - 3
C
3 - 4
D
4 - 5
E
1 - 5
Açıklama:
Veritabanlarında Bilgi Keşfi sürecinde izlenmesi gereken temel aşamalar aşağıdaki gibi sıralanabilir.
1. Amacın Tanımlanması
2. Veriler Üzerinde Ön İşlemlerin Yapılması
3. Modelin Kurulması ve Değerlendirilmesi
4. Modelin Kullanılması ve Yorumlanması
5. Modelin İzlenmesi
1. Amacın Tanımlanması
2. Veriler Üzerinde Ön İşlemlerin Yapılması
3. Modelin Kurulması ve Değerlendirilmesi
4. Modelin Kullanılması ve Yorumlanması
5. Modelin İzlenmesi
Soru 104
- Verilerin toplanması
- Verilerin birleştirilmesi
- Verilerin temizlenmesi
- Verilerin yeniden yapılandırılması
Seçenekler
A
Yalnız I
B
Yalnız II
C
II - III
D
II - III - IV
E
I - II - III - IV
Açıklama:
Veriler üzerindeki ön işlemler genel olarak;
• Verilerin toplanması ve birleştirilmesi,
• Verilerin temizlenmesi,
• Verilerin yeniden yapılandırılması biçiminde sınıflandırılabilir.
• Verilerin toplanması ve birleştirilmesi,
• Verilerin temizlenmesi,
• Verilerin yeniden yapılandırılması biçiminde sınıflandırılabilir.
Soru 105
"......................., veritabanlarındaki kayıtlarda eksik olan verilerdir. Çeşitli nedenlerden kaynaklanabilir; veri toplamada yanlış araçların kullanılması,
veri girişinde hata yapılması ya da veri toplama aşamasında sorulara eksik cevap verilmesi bu nedenlerden bazılarıdır."
Metinde verilen boşluğa aşağıdaki seçeneklerden hangisi getirilmelidir?
veri girişinde hata yapılması ya da veri toplama aşamasında sorulara eksik cevap verilmesi bu nedenlerden bazılarıdır."
Metinde verilen boşluğa aşağıdaki seçeneklerden hangisi getirilmelidir?
Seçenekler
A
Gürültülü veri
B
Kayıp veri
C
Ayrışık veri
D
Birleşik veri
E
Toplam veri
Açıklama:
Kayıp veri, veritabanlarındaki kayıtlarda eksik olan verilerdir. Kayıp veriler çeşitli nedenlerden kaynaklanabilir; veri toplamada yanlış araçların kullanılması, veri girişinde hata yapılması ya da veri toplama aşamasında
sorulara eksik cevap verilmesi bu nedenlerden bazılarıdır.
sorulara eksik cevap verilmesi bu nedenlerden bazılarıdır.
Soru 106
- Bölümleme yöntemiyle
- Sınır değerleri kullanılarak
- Kümeleme yöntemiyle
- Kolerasyon yöntemiyle
- T testi kullanılarak
Seçenekler
A
Yalnız V
B
IV - V
C
II - IV
D
I - II - III
E
I - II - IV - V
Açıklama:
Verilerdeki gürültünün temizlenmesi amacıyla kullanılan yaklaşımlar ise aşağıdaki gibidir:
a. Bölümleme yöntemiyle gürültünün temizlenmesi: Bu yöntemde üzerinde analiz yapılacak veriler önce küçükten büyüğe doğru sıralanır. Daha sonra veriler eşit sayıda eleman içeren gruplara bölünür. Her grupta bulunan verilerin ortalama değeri ya da medyan değeri bulunarak grupta yer alan tüm veriler ortalama ya da medyan değeri ile değiştirilerek düzeltme yapılır.
b. Sınır değerleri kullanılarak gürültünün temizlenmesi: Bu yöntemde de veriler önceki yöntemde olduğu gibi küçükten büyüğe doğru sıralanarak eşit bölümlere ayrılır. Daha sonra, her bölümün en küçük ve en büyük değerli verileri sınır değerleri olmak üzere bölüm içindeki her bir değer üst sınır ya da alt sınır değerlerinden hangisine yakınsa o sınır değeri ile değiştirilir.
c. Kümeleme yöntemiyle düzeltme yapılması ve gürültünün temizlenmesi: Bu yaklaşım aykırı değerlerin ortaya çıkarılması ve düzeltilmesinde kullanılır. Buna göre, veri setinde yer alan veriler birbirlerine olan benzerlik ve yakınlıklarına göre kümelere ayrılır. Bu kümeleme işlemi sırasında uç değer olarak kabul edilen bazı veriler hiçbir küme içinde yer alamayacaktır. Bu şekilde belirlenen her bir aykırı değere, en yakın olduğu kümenin ortalama değeri veya en küçük ya da en büyük değeri atanarak aykırı veriler temizlenmiş olur.
d. Regresyon yöntemiyle düzeltme yapılması ve gürültünün temizlenmesi: Verilerde gürültünün temizlenmesi amacıyla kullanılabilecek diğer bir yöntem, değişken değerlerini bir fonksiyon yardımıyla ilişkilendiren regresyon yönteminin kullanılmasıdır. Doğrusal regresyon iki nitelik ya da iki değişken arasındaki en uygun doğruyu bulmayı içerir. Bu nedenle bir nitelik (ya da değer) diğerinin tahmin edilmesinde kullanılabilir. Çoklu doğrusal regresyon doğrusal regresyonun genişletilmiş biçimi olup ikiden fazla nitelik (değişken) söz konusu olduğunda kullanılır ve analiz çok boyutlu düzlemde gerçekleştirilir.
a. Bölümleme yöntemiyle gürültünün temizlenmesi: Bu yöntemde üzerinde analiz yapılacak veriler önce küçükten büyüğe doğru sıralanır. Daha sonra veriler eşit sayıda eleman içeren gruplara bölünür. Her grupta bulunan verilerin ortalama değeri ya da medyan değeri bulunarak grupta yer alan tüm veriler ortalama ya da medyan değeri ile değiştirilerek düzeltme yapılır.
b. Sınır değerleri kullanılarak gürültünün temizlenmesi: Bu yöntemde de veriler önceki yöntemde olduğu gibi küçükten büyüğe doğru sıralanarak eşit bölümlere ayrılır. Daha sonra, her bölümün en küçük ve en büyük değerli verileri sınır değerleri olmak üzere bölüm içindeki her bir değer üst sınır ya da alt sınır değerlerinden hangisine yakınsa o sınır değeri ile değiştirilir.
c. Kümeleme yöntemiyle düzeltme yapılması ve gürültünün temizlenmesi: Bu yaklaşım aykırı değerlerin ortaya çıkarılması ve düzeltilmesinde kullanılır. Buna göre, veri setinde yer alan veriler birbirlerine olan benzerlik ve yakınlıklarına göre kümelere ayrılır. Bu kümeleme işlemi sırasında uç değer olarak kabul edilen bazı veriler hiçbir küme içinde yer alamayacaktır. Bu şekilde belirlenen her bir aykırı değere, en yakın olduğu kümenin ortalama değeri veya en küçük ya da en büyük değeri atanarak aykırı veriler temizlenmiş olur.
d. Regresyon yöntemiyle düzeltme yapılması ve gürültünün temizlenmesi: Verilerde gürültünün temizlenmesi amacıyla kullanılabilecek diğer bir yöntem, değişken değerlerini bir fonksiyon yardımıyla ilişkilendiren regresyon yönteminin kullanılmasıdır. Doğrusal regresyon iki nitelik ya da iki değişken arasındaki en uygun doğruyu bulmayı içerir. Bu nedenle bir nitelik (ya da değer) diğerinin tahmin edilmesinde kullanılabilir. Çoklu doğrusal regresyon doğrusal regresyonun genişletilmiş biçimi olup ikiden fazla nitelik (değişken) söz konusu olduğunda kullanılır ve analiz çok boyutlu düzlemde gerçekleştirilir.
Soru 107
- Zaman serisi analizi
- Kümeleme
- Özetleme
- Birliktelik kuralları
- Sıra örüntü analizi
Seçenekler
A
Yalnız I
B
II - III
C
I - III - IV
D
II - III - IV - V
E
I - II - III - IV - V
Açıklama:
En yaygın kullanılan tanımlayıcı modeller; kümeleme, birliktelik kuralları,
sıra örüntü analizi ve özetleme biçiminde sıralanabilir.
1. Kümeleme: Kümeleme, verileri birbirlerine olan benzerliklerine göre anlamlı ve/ veya kullanışlı gruplara ayırmaktır. Eğer amaç anlamlı kümeler oluşturmaksa o zaman kümeler verilerin doğal yapısını yansıtmalıdır. Bazı durumlarda ise kümeleme veri özetleme gibi farklı amaçlar için kullanışlı bir başlangıç noktası oluşturmaktadır. Kümeleme analizi bir hedef değişken içermediğinden, diğer bir ifade ile veriler bağımlı bir değişkene göre değil öznitelik değerlerine göre gruplandırıldığından, daha önce sözü edilen sınıflama analizinden farklı bir yaklaşımdır.
2. Birliktelik kuralları: Birliktelik kuralları veriler arasındaki güçlü birliktelik özelliklerini tanımlayan örüntüleri keşfetmek için kullanılan analiz yöntemidir. Birliktelik kuralı, belirli türdeki veri ilişkilerini tanımladığı için tanımlayıcı modeller içinde yer almaktadır.
3. Sıra örüntü analizi: Sıra örüntü analizi birliktelik kurallarına benzer bir yapıda olup aynı zamanda olayların zaman sıralarıyla ilgilenir. Birliktelik kurallarında sözü edilen pazar sepeti analizinde, ürünlerin müşteri tarafından aynı anda alınmasıyla ilgilenilirken sıra örüntüleri analizinde belirli bir zaman aralığında satın alınan ürünler arasındaki ilişkilerle ilgilenilir.
4. Özetleme: Karakterizasyon veya genelleştirme olarak da adlandırılan özetleme, verileri basit tanımları yapılmış alt gruplar içine yerleştirme işlemidir. Özetleme veritabanı hakkında betimleyici bilgileri ortaya çıkarır ve verilerden elde edilen ortalama veya standart sapma gibi tüm veriyi temsil eden göstergelerin hesaplanmasını ifade eder. Özet bilgiler, veritabanı fonksiyonları ve tanımlayıcı veri madenciliği teknikleri kullanılarak elde edilebilir.
sıra örüntü analizi ve özetleme biçiminde sıralanabilir.
1. Kümeleme: Kümeleme, verileri birbirlerine olan benzerliklerine göre anlamlı ve/ veya kullanışlı gruplara ayırmaktır. Eğer amaç anlamlı kümeler oluşturmaksa o zaman kümeler verilerin doğal yapısını yansıtmalıdır. Bazı durumlarda ise kümeleme veri özetleme gibi farklı amaçlar için kullanışlı bir başlangıç noktası oluşturmaktadır. Kümeleme analizi bir hedef değişken içermediğinden, diğer bir ifade ile veriler bağımlı bir değişkene göre değil öznitelik değerlerine göre gruplandırıldığından, daha önce sözü edilen sınıflama analizinden farklı bir yaklaşımdır.
2. Birliktelik kuralları: Birliktelik kuralları veriler arasındaki güçlü birliktelik özelliklerini tanımlayan örüntüleri keşfetmek için kullanılan analiz yöntemidir. Birliktelik kuralı, belirli türdeki veri ilişkilerini tanımladığı için tanımlayıcı modeller içinde yer almaktadır.
3. Sıra örüntü analizi: Sıra örüntü analizi birliktelik kurallarına benzer bir yapıda olup aynı zamanda olayların zaman sıralarıyla ilgilenir. Birliktelik kurallarında sözü edilen pazar sepeti analizinde, ürünlerin müşteri tarafından aynı anda alınmasıyla ilgilenilirken sıra örüntüleri analizinde belirli bir zaman aralığında satın alınan ürünler arasındaki ilişkilerle ilgilenilir.
4. Özetleme: Karakterizasyon veya genelleştirme olarak da adlandırılan özetleme, verileri basit tanımları yapılmış alt gruplar içine yerleştirme işlemidir. Özetleme veritabanı hakkında betimleyici bilgileri ortaya çıkarır ve verilerden elde edilen ortalama veya standart sapma gibi tüm veriyi temsil eden göstergelerin hesaplanmasını ifade eder. Özet bilgiler, veritabanı fonksiyonları ve tanımlayıcı veri madenciliği teknikleri kullanılarak elde edilebilir.
Soru 108
Veri madenciliğinin ortaya çıkışı hangi ihtiyaçtan ortaya çıkmıştır?
Seçenekler
A
Büyük miktarda veriyi analiz edebilme ve işleyebilme ihtiyacı
B
Büyük miktarda veriyi saklayabilme ve yayınlayabilme ihtiyacı
C
Veriyi analiz edebilme ve paylaşma ihtiyacı
D
Veriyi organize edebilme ihtiyacı
E
Sanal veri üretme ihtiyacı
Açıklama:
Anlamlı bilgilere ulaşabilmek amacıyla geçmişten beri kullanılan farklı yöntemler bulunmaktadır. Bununla birlikte verilerin analiz edilmesinde kullanılan geleneksel yöntemler veri miktarında meydana gelen büyük artış karşısında yetersiz kalmaya başlamıştır. Veri madenciliğinin ortaya çıkışı da büyük miktarda veriyi analiz edebilme ve işleyebilme ihtiyacından kaynaklanmıştır.
Soru 109
Veri mdenciliğinin tarihsel gelişimi göz önünde bulundurulduğunda hangi yılın karşısındaki bilgi yanlış verilmiştir?
Seçenekler
A
1950’ler • İlk bilgisayarlar (sayım ve hesaplama amaçlı)
B
1960’lar • İlişkisel Veritabanı Yönetim Sistemleri
C
1970’ler • Basit kurallara dayanan uzman sistemler ve makine öğrenimi
D
1980’ler • Büyük miktarda veri içeren veri tabanları
E
1990’lar • Veritabanlarında Bilgi Keşfi Çalışma Grubu ve Sonuç Bildirgesi
Açıklama:
1950’ler • İlk bilgisayarlar (sayım ve hesaplama amaçlı)
1960’lar • Verilerin depolanması ve veritabanları
• Perseptronlar
1970’ler • İlişkisel Veritabanı Yönetim Sistemleri
• Basit kurallara dayanan uzman sistemler ve makine öğrenimi
1980’ler • Büyük miktarda veri içeren veri tabanları
• SQL sorgu dili
1990’lar • Veritabanlarında Bilgi Keşfi Çalışma Grubu ve Sonuç Bildirgesi
• Veri madenciliği için ilk yazılım
2000’ler • Tüm alanlar için veri madenciliği uygulamaları
1960’lar • Verilerin depolanması ve veritabanları
• Perseptronlar
1970’ler • İlişkisel Veritabanı Yönetim Sistemleri
• Basit kurallara dayanan uzman sistemler ve makine öğrenimi
1980’ler • Büyük miktarda veri içeren veri tabanları
• SQL sorgu dili
1990’lar • Veritabanlarında Bilgi Keşfi Çalışma Grubu ve Sonuç Bildirgesi
• Veri madenciliği için ilk yazılım
2000’ler • Tüm alanlar için veri madenciliği uygulamaları
Soru 110
Veri madenciliğinin etkileşimde olduğu disiplinler düşünüldüğünde hangi seçenekte yer alan disiplin bu sınıflamanın dışında kalmaktadır?
Seçenekler
A
İstatistik
B
Görselleştirme
C
Temalandırma
D
Makina öğrenimi
E
Örüntü tanıma
Açıklama:
Veri Madenciliğinin
Etkileşimde Olduğu
Disiplinler:
Makine Öğrenimi
İstatistik Veritabanı Sistemleri
Görselleştirme
Örüntü Tanıma Diğer
Disiplinler
Etkileşimde Olduğu
Disiplinler:
Makine Öğrenimi
İstatistik Veritabanı Sistemleri
Görselleştirme
Örüntü Tanıma Diğer
Disiplinler
Soru 111
Ham gözlemler, işlenmemiş gerçekler ya da izlenimlerin genel ismi aşağıdakilerden hangisidir?
Seçenekler
A
Veri
B
İstatistik
C
İşletim sistemi
D
Analiz
E
İşlemleme
Açıklama:
Veri madenciliği kavramını tanımlamadan önce veri, enformasyon ve bilgi kavramlarını hatırlatmak faydalı olacaktır. Veri, ham gözlemler, işlenmemiş gerçekler ya da izlenimlerdir.
Soru 112
Veri madenciliği ismi verilerin işlenmesi ile analoji kurularak adlandırılmıştır. Veri madenciliğinin adının nerden geldiğini açıklamak isteyen bir uzman aşağıdaki benzetmelerden hangisini kullanırsa doğru olur?
Seçenekler
A
Kuyumcuların vitrininde ürünlerini sergilemesi ile verinin görselleştirilmesi
B
Muhasebe şirketinin hesaplamaları ile istatistik
C
Öğretmenin ders anlatımı ile görselliştirme
D
Yer altında duran madenin işlenmedikçe değerli olmayışı ile veri madenciliği
E
Mühendisin çalışma şekli ile makine öğrenimi
Açıklama:
Bilindiği gibi ekonomik yönden değer taşıyan maddelerin (altın, gümüş, elmas, bor,
kömür vb.) bulundukları yerlere maden, bu maddelerin çıkarılıp işlenmesi ile ilgili olarak gerçekleştirilen faaliyetlere de madencilik denir. Bu maddeler bulundukları yerden
çıkarılıp işlenmedikleri sürece bir değer taşımazlar. Benzer durum veritabanlarında yığınlar biçiminde bulunan veriler için de geçerlidir. Veritabanlarında kayıtlı olan veriler
de madenlerden çıkarılıp işlenmeyi bekleyen değerli maddelere benzetilebilir. Bu nedenle büyük miktarda yığın veri içinden bilgiye ulaşmak amacıyla kullanılan teknikler bütünü de veri madenciliği adı altında ele alınmaktadır.
kömür vb.) bulundukları yerlere maden, bu maddelerin çıkarılıp işlenmesi ile ilgili olarak gerçekleştirilen faaliyetlere de madencilik denir. Bu maddeler bulundukları yerden
çıkarılıp işlenmedikleri sürece bir değer taşımazlar. Benzer durum veritabanlarında yığınlar biçiminde bulunan veriler için de geçerlidir. Veritabanlarında kayıtlı olan veriler
de madenlerden çıkarılıp işlenmeyi bekleyen değerli maddelere benzetilebilir. Bu nedenle büyük miktarda yığın veri içinden bilgiye ulaşmak amacıyla kullanılan teknikler bütünü de veri madenciliği adı altında ele alınmaktadır.
Soru 113
Veri madenciliği, büyük miktardaki veri yığınları üzerinde analiz yaparak veriler ........ var olan ve geleceğin tahmin edilmesine yardımcı olacak anlamlı ve .......... ilişki ve kuralların bilgisayar yazılımları aracılığıyla aranması faaliyetleridir, tanımında boş bırakılan yerlere sırasıyla hangi kelimeler gelmelidir?
Seçenekler
A
arasında, kurallı
B
içerisinde, oranlı
C
içerisinde, kurallı
D
ortasında, yararlı
E
arasında, yararlı
Açıklama:
Veri madenciliği, büyük miktardaki veri yığınları üzerinde analiz yaparak veriler arasında var olan ve geleceğin tahmin edilmesine yardımcı olacak anlamlı ve yararlı ilişki ve kuralların bilgisayar yazılımları aracılığıyla aranması faaliyetleridir
Soru 114
Veritabanlarında Bilgi Keşfi sürecinde izlenmesi gereken temel aşamalar hangi sıralama ile yapılmalıdır?
I. Veriler Üzerinde Ön İşlemlerin Yapılması
II. Amacın Tanımlanması
III. Modelin Kurulması ve Değerlendirilmesi
IV. Modelin İzlenmesi
V. Modelin Kullanılması ve Yorumlanması
I. Veriler Üzerinde Ön İşlemlerin Yapılması
II. Amacın Tanımlanması
III. Modelin Kurulması ve Değerlendirilmesi
IV. Modelin İzlenmesi
V. Modelin Kullanılması ve Yorumlanması
Seçenekler
A
I-II-II-IV-V
B
I-III-II-V-IV
C
II-I-III-V-IV
D
II-III-I-V-VI
E
II-I-III-IV-V
Açıklama:
Veritabanlarında Bilgi Keşfi sürecinde, işlemsel veritabanlarında depolanmış olan verinin sorgulama ve analiz için uygun hâle getirilmesi işlemleri yürütülür. Veritabanlarında
Bilgi Keşfi sürecinde izlenmesi gereken temel aşamalar aşağıdaki gibi sıralanabilir.
1. Amacın Tanımlanması
2. Veriler Üzerinde Ön İşlemlerin Yapılması
3. Modelin Kurulması ve Değerlendirilmesi
4. Modelin Kullanılması ve Yorumlanması
5. Modelin İzlenmesi
Bilgi Keşfi sürecinde izlenmesi gereken temel aşamalar aşağıdaki gibi sıralanabilir.
1. Amacın Tanımlanması
2. Veriler Üzerinde Ön İşlemlerin Yapılması
3. Modelin Kurulması ve Değerlendirilmesi
4. Modelin Kullanılması ve Yorumlanması
5. Modelin İzlenmesi
Soru 115
Min-maks , sıfır-ortalama ve ondalıklı biçiminde sıralanan yöntemler hangi terimin alt öğeleridir?
Seçenekler
A
Regresyon
B
Kümeleme
C
Dönüştürme
D
Normalizasyon
E
Standardizasyon
Açıklama:
Farklı değerlerdeki verilerin 0,0-1,0 gibi aralıklardaki değerlerle temsil edilmesi işlemine normalizasyon denir. Normalizasyon işlemi için kullanılabilen yöntemlerden bir kısmı; min-maks normalizasyonu, sıfır-ortalama normalizasyonu ve ondalıklı normalizasyon biçiminde sıralanabilir.
Soru 116
Aşağıdaki seçeneklerden hangisinde geleneksel istatistik ve veri madenciliği arasındaki farklardan biri yanlış belirtilmiştir?
Seçenekler
A
İstatistiksel analizde, analize genellikle bir hipotez kurularak başlanırken veri madenciliği ile analizde herhangi bir hipoteze gerek duyulmaz.
B
İstatistikçiler hipotezlerini eşleştirmek için kendi eşitliklerini geliştirmek zorunda
oldukları hâlde, veri madenciliği algoritmaları eşitlikleri otomatik olarak geliştirir.
oldukları hâlde, veri madenciliği algoritmaları eşitlikleri otomatik olarak geliştirir.
C
İstatistiksel analiz sonuçları bilimselken, veri madenciliği sonuçları gündelik bilgiyi oluşturur.
D
İstatistiksel analizler genellikle sayısal veriler üzerinde gerçekleştirilirken veri madenciliği sayısal verilere ek olarak metin, ses vb. gibi farklı veri türleri üzerinde de
işlem yapabilir.
işlem yapabilir.
E
İstatistiksel analizde, kirli veri analiz sırasında bulunur ve filtre edilirken veri madenciliği temizlenmiş veri üzerinde gerçekleştirilir.
Açıklama:
Geleneksel istatistiksel analiz ile veri madenciliği arasındaki temel farklar aşağıdaki
gibi sıralanabilir:
• İstatistiksel analizde, analize genellikle bir hipotez kurularak başlanırken veri madenciliği ile analizde herhangi bir hipoteze gerek duyulmaz.
• İstatistikçiler hipotezlerini eşleştirmek için kendi eşitliklerini geliştirmek zorunda
oldukları hâlde, veri madenciliği algoritmaları eşitlikleri otomatik olarak geliştirir.
• İstatistiksel analizler genellikle sayısal veriler üzerinde gerçekleştirilirken veri madenciliği sayısal verilere ek olarak metin, ses vb. gibi farklı veri türleri üzerinde de
işlem yapabilir.
• İstatistiksel analizde, kirli veri analiz sırasında bulunur ve filtre edilirken veri madenciliği temizlenmiş veri üzerinde gerçekleştirilir.
gibi sıralanabilir:
• İstatistiksel analizde, analize genellikle bir hipotez kurularak başlanırken veri madenciliği ile analizde herhangi bir hipoteze gerek duyulmaz.
• İstatistikçiler hipotezlerini eşleştirmek için kendi eşitliklerini geliştirmek zorunda
oldukları hâlde, veri madenciliği algoritmaları eşitlikleri otomatik olarak geliştirir.
• İstatistiksel analizler genellikle sayısal veriler üzerinde gerçekleştirilirken veri madenciliği sayısal verilere ek olarak metin, ses vb. gibi farklı veri türleri üzerinde de
işlem yapabilir.
• İstatistiksel analizde, kirli veri analiz sırasında bulunur ve filtre edilirken veri madenciliği temizlenmiş veri üzerinde gerçekleştirilir.
Soru 117
• Müşterilerin satın alma örüntülerinin belirlenmesi
• Benzer özellikler gösteren müşterilerin bulunması
• Müşterilerin demografik özellikleri arasındaki bağlantıların belirlenmesi
• Benzer gelir grupları, ilgi alanları, harcama alışkanlıklarının ortaya çıkarılması gibi uygulamalar veri madenciliğinin uygulandığı hangi alana örnektir?
• Benzer özellikler gösteren müşterilerin bulunması
• Müşterilerin demografik özellikleri arasındaki bağlantıların belirlenmesi
• Benzer gelir grupları, ilgi alanları, harcama alışkanlıklarının ortaya çıkarılması gibi uygulamalar veri madenciliğinin uygulandığı hangi alana örnektir?
Seçenekler
A
Finans alanındaki uygulamalar
B
Pazarlama alanındaki uygulamalar
C
Sağlık alanındaki uygulamalar
D
Eğitim alanındaki uygulamalar
E
Endüstri ve mühendislik alanındaki uygulamalar
Açıklama:
Veri madenciliğinin en çok kullanıldığı alanların başında pazarlama alanının geldiği söylenebilir. Yapılan çalışmalar incelendiğinde, pazarlama alanında yapılan veri madenciliği uygulama konuları izleyen biçimde sıralanabilir.
• Müşterilerin satın alma örüntülerinin belirlenmesi
• Benzer özellikler gösteren müşterilerin bulunması
• Müşterilerin demografik özellikleri arasındaki bağlantıların belirlenmesi
• Benzer gelir grupları, ilgi alanları, harcama alışkanlıklarının ortaya çıkarılması
• Benzer müşterileri otomatik olarak gruplayarak, pazar dilimlerinin tanımlanması
ve bu bilginin pazarlama kampanyalarında kullanılması
• Mevcut müşterilerin elde tutulması, yeni müşterilerin kazanılması
• Satış tahmini yapılması
• Müşteri ilişkileri yönetimi
• İnternet üzerinden satış yapan işletmeler için kullanıcı profillerinin belirlenmesi
• Web sayfalarının kullanıcı bilgilerine göre kişiselleştirilmesi
• Müşterilerin satın alma örüntülerinin belirlenmesi
• Benzer özellikler gösteren müşterilerin bulunması
• Müşterilerin demografik özellikleri arasındaki bağlantıların belirlenmesi
• Benzer gelir grupları, ilgi alanları, harcama alışkanlıklarının ortaya çıkarılması
• Benzer müşterileri otomatik olarak gruplayarak, pazar dilimlerinin tanımlanması
ve bu bilginin pazarlama kampanyalarında kullanılması
• Mevcut müşterilerin elde tutulması, yeni müşterilerin kazanılması
• Satış tahmini yapılması
• Müşteri ilişkileri yönetimi
• İnternet üzerinden satış yapan işletmeler için kullanıcı profillerinin belirlenmesi
• Web sayfalarının kullanıcı bilgilerine göre kişiselleştirilmesi
Soru 118
SQL sorgu dilinin ortaya çıkışı hangi döneme karşılık gelmektedir?
Seçenekler
A
1920'ler
B
1940'lar
C
1980'ler
D
2000'ler
E
2020 ve sonrası
Açıklama:

Soru 119
Sınır değerleri kullanılarak veride nasıl bir işlem yapılır?
Seçenekler
A
Grafik çizilir
B
örneklem birim sayısı arttırılır
C
Ana kütle parametresi en büyüklenir
D
Veride gürültü temizlenir
E
Zamana serisi yapılabilir
Açıklama:
Sınır değerleri kullanılarak gürültünün temizlenmesi: Bu yöntemde de veriler önce- ki yöntemde olduğu gibi küçükten büyüğe doğru sıralanarak eşit bölümlere ayrılır. Daha sonra, her bölümün en küçük ve en büyük değerli verileri sınır değerleri olmak üzere bölüm içindeki her bir değer üst sınır ya da alt sınır değerlerinden hangisine yakınsa o sınır değeri ile değiştirilir.
Ünite 2
Soru 1
R programında komutların girilmesi için kullanılan bölgeye ne ad verilmektedir?
Seçenekler
A
Download R for Windows
B
Value
C
Help
D
R Console
E
Generic Function
Açıklama:
Komutların girilmesi için kullanılan bölgeye “R Console” denir. Doğru cevap D'dir.
Soru 2
Aşağıdaki seçeneklerden hangisi yanlıştır?
Seçenekler
A
R yazılımının bir veri işleme ve grafik çizme programıdır.
B
Matematiksel bir ifadenin hesaplanması için meydana çıkan komutlar temel komutlardır.
C
R ile çalışırken herhangi bir fonksiyon hakkında yardım almak için value komutu kullanılır.
D
R console komut girrilmesi için kullanılan bölgedir.
E
Windows işletim sistemi için derlenmiş program Download R for Windows linkinde yer almaktadır.
Açıklama:
R ile çalışırken herhangi bir fonksiyon ya da kitaplık hakkında yardım almak için help komutunu kullanılır. Doğru cevap C'dir.
Soru 3
R yazılımı ile ilgili olarak aşağıda verilen İfadelerden hangisi veya hangileri doğrudur?
I-R yazılımı büyük ve küçük harfe duyarlıdır.
II-R yazılımında vektör oluşturmak için c() fonksiyonu kullanılır.
III-Önceden tanımlanmış bir vektörün birim sayısını öğrenmek için length () fonksiyonu kullanılır.
IV-c() fonksiyonu karakter değişkenleri oluşturmak için kullanılır.
I-R yazılımı büyük ve küçük harfe duyarlıdır.
II-R yazılımında vektör oluşturmak için c() fonksiyonu kullanılır.
III-Önceden tanımlanmış bir vektörün birim sayısını öğrenmek için length () fonksiyonu kullanılır.
IV-c() fonksiyonu karakter değişkenleri oluşturmak için kullanılır.
Seçenekler
A
I-II-III-IV
B
Yanlız IV
C
II-III
D
II-III-IV
E
Yanlız I
Açıklama:
R yazılımı büyük ve küçük harfe duyarlıdır.X ve x değişkenleri tamamen farklı değişkenlerdir. R yazılımında vektör oluşturmak için c() fonksiyonu kullanılır. Ayrıca c() fonksiyonu karakter değişkenleri oluşturmak içinde kullanılır. Önceden tanımlanmış bir vektörün birim sayısını öğrenmek için length () fonksiyonu kullanılır. Doğru cevap A'dır.
Soru 4
R yazılımında rep() fonksiyonu hangi işlev için kullanılmaktadır?
Seçenekler
A
Matris oluşturma
B
Bir değişkenin kareköküni hesaplama
C
Vektör oluşturmada
D
Belirli bir düzene sahip verilerin oluşturulmasında
E
Önceden tanımlanmış bir vektörün birim sayısını öğrenmek için
Açıklama:
Belirli bir düzene sahip verilerin oluşturulması için rep () fonksiyonu kullanılır.Doğru cevap D'dir.
Soru 5
Aşağıdaki seçeneklerin hangisinde, R yazılımında 1'den 4'e kadar herbirinden kendi sayısı kadar olacak biçimde rakamlardan oluşan vektörü oluşturmak için yapılacak işlem doğru bir şekilde verilmiştir?
Seçenekler
A
[1] 1 2 2 3 3 3 4 4 4 4 5 5 5 5 5 6 6 6 6 6 6
B
> rep(seq(4),c(1,2,3,4))
C
> rep(seq(5),rep(5,5))
D
> rep(1:5,4)
[1] 1 2 3 4 5 1 2 3 4 5 1 2 3 4 5 1 2 3 4 5
[1] 1 2 3 4 5 1 2 3 4 5 1 2 3 4 5 1 2 3 4 5
E
> rep(seq(1,6),2)
[1] 1 2 3 4 5 6 1 2 3 4 5 6
[1] 1 2 3 4 5 6 1 2 3 4 5 6
Açıklama:
R yazılımında 1'den 4'e kadar herbirinden kendi sayısı kadar olacak biçimde rakamlardan oluşan vektörü oluşturmak için > rep(seq(4),c(1,2,3,4)) işlemi gerçekleştirilmelidir. Doğru cevap B'dir.
Soru 6
R yazılımında matris oluşturmak için hangi fonksiyon kullanılmaktadır?
Seçenekler
A
matrix() fonksiyonu
B
Doğru (T) fonksiyonu
C
False(x) fonksiyonu
D
data.frame fonksiyonu
E
List Nesneleri
Açıklama:
R yazılımında matris oluşturmak için matrix () fonksiyonu kullanılmaktadır. Doğru cevap A'dır.
Soru 7
Mantık operatörleri ile ilgili olarak verilen ifadelerden hangisi veya hangileri doğrudur?
I-Doğru ve yanlış olmak üzere iki mantıksal değer vardır.
II-& operatörü "Ve" anlamına gelir.
III-Mantık fonksiyonları yardımı ile ilgilenilen değişkenin bir karakter değişkeni mi yoksa sayısal bir değişken mi olduğu anlaşılabilir.
IV-Mantık operatörleri, karşılaştırma yaparken ve vektörler ile matrislerin belirli elemanlarını belirlerken kullanılmaktadır.
V-">=" operatörü "büyüktür" anlamına gelir.
I-Doğru ve yanlış olmak üzere iki mantıksal değer vardır.
II-& operatörü "Ve" anlamına gelir.
III-Mantık fonksiyonları yardımı ile ilgilenilen değişkenin bir karakter değişkeni mi yoksa sayısal bir değişken mi olduğu anlaşılabilir.
IV-Mantık operatörleri, karşılaştırma yaparken ve vektörler ile matrislerin belirli elemanlarını belirlerken kullanılmaktadır.
V-">=" operatörü "büyüktür" anlamına gelir.
Seçenekler
A
I-II-III-IV-V
B
I-III-IV
C
I-IV-V
D
II-IV-V
E
I-II-III-IV
Açıklama:
">=" operatörü "büyük ya da eşittir " anlamına gelir. V. ifade dışında tüm ifadeler doğrudur. Doğru cevap E'dir.
Soru 8
R yazılımında function() komutu hngi komut ile sonlandırılır?
Seçenekler
A
boxplot()
B
return()
C
hist()
D
par(mfrow=c())
E
> ozetle()
Açıklama:
function() komutu, return() komutu ile sonlandırılır. Doğru cevap B'dir.
Soru 9
Dosyalardan formatlanmış data frame elde edilmesi için hangi fonksiyon kullanılabilir?
Seçenekler
A
scan()
B
read.fwf()
C
Install Package(s)
D
read.csv()
E
read.table()
Açıklama:
read.table() dosyalardan formatlanmış data frame elde edilmesi işlemi için kullanılan fonksiyondur. Doğru cevap E'dir.
Soru 10
I. Veri işleme
II. Müşteri analizi
III. Dizi ve matris hesaplamaları
IV. Şirket adına pazar araştıması
Yukarıdakilerden hangileri R yazılımının sunduğu olanaklardandır?
II. Müşteri analizi
III. Dizi ve matris hesaplamaları
IV. Şirket adına pazar araştıması
Yukarıdakilerden hangileri R yazılımının sunduğu olanaklardandır?
Seçenekler
A
Yalnız III
B
II ve IV
C
III ve IV
D
I ve III
E
Yalnız I
Açıklama:
R yazılımı çevre birimi kullanıcılara etkin bir veri işleme ve depolama olanağı, dizi ve matris hesaplamaları için komutlar grubu, veri analizi için ileri düzeyde teknikler topluluğu, verinin ekranda ya da basılı bir eserde görüntülenebilmesine olanak veren geniş grafiksel özellikler, kolay programlamaya uygun fakat karmaşık programlama dillerinin özelliklerine sahip bir programlama dilinin olanaklarını sunmaktadır.
Soru 11
Aşağıdakilerden hangisinde R yazılımın hangi görev için kullanıldığı doğru verilmiştir?
Seçenekler
A
R yazılımının bir veri işleme ve grafik çizme programıdır.
B
R yazılımının bir analiz programıdır.
C
R yazılımının bir sohbet programıdır.
D
R yazılımının bir sayfa tasarım programıdır.
E
R yazılımının bir fotoğraf düzenleme programıdır
Açıklama:
R yazılımının bir veri işleme ve grafik çizme programı olduğu unutulmamalıdır.
Soru 12
"Herhangi bir atama yapılması ya da matematiksel bir ifadenin hesaplanması için en basit komutlar olarak meydana çıkan komutlar grubuna .............. denir."
Aşağıdakilerden hangisi boş bırakılan yere uygun gelebilecek kavramdır?
Aşağıdakilerden hangisi boş bırakılan yere uygun gelebilecek kavramdır?
Seçenekler
A
Veri
B
Veri madenciliği
C
R yazılım
D
Kod
E
Temel komutlar
Açıklama:
Herhangi bir atama yapılması ya da matematiksel bir ifadenin hesaplanması için en basit komutlar olarak meydana çıkan komutlar grubuna temel komutlar denir.
Soru 13
Aşağıdakilerden hangisi bir vektörü en basit şekliyle yaratmak için kullanılan komuttur?
Seçenekler
A
D
B
X
C
C
D
B
E
S
Açıklama:
Bir vektörü en basit şekilde yaratmak için c () fonksiyonu kullanılır.
Soru 14
Aşağıdakilerden hangisi bir değişkenin karekökünü hesaplamada kullanılan komuttur?
Seçenekler
A
qwer
B
bhyt
C
sqrt
D
matrix
E
khgd
Açıklama:
Bir
değişkenin karekökü sqrt() fonksiyonu yardımıyla hesaplanabilir.
değişkenin karekökü sqrt() fonksiyonu yardımıyla hesaplanabilir.
Soru 15
"Çeşitli istatistiksel analizler için oluşturulan farklı nesnelerin bir araya getirilmesinde ........... faydalanılır."
Aşağıdakilerden hangisi boş bırakılan yere getirilmesi gereken uygun kavramdır?
Aşağıdakilerden hangisi boş bırakılan yere getirilmesi gereken uygun kavramdır?
Seçenekler
A
Matrix
B
Mantık fonksiyonları
C
List nesneleri
D
Temel komutlar
E
Length
Açıklama:
Çeşitli istatistiksel analizler için oluşturulan farklı nesnelerin bir araya getirilmesinde List Nesnelerinden faydalanılır.
Soru 16
"R yazılımında veri seti içerisindeki faktör listeleri ve gözlem birimleri .......... olarak bir araya getirilirler."
Aşağıdakilerden hangisi boş bırakılan yere gelmesi uygun olan kavramdır?
Aşağıdakilerden hangisi boş bırakılan yere gelmesi uygun olan kavramdır?
Seçenekler
A
Data frame
B
Matrix
C
List nesneler
D
sqrt
E
Mantıksal operatörler
Açıklama:
R yazılımında veri seti içerisindeki faktör listeleri ve gözlem birimleri data frame olarak bir araya getirilirler.
Soru 17
I. > (veya)
II. < (küçüktür)
III. & (ve)
IV. != (eşittir)
Yukarıdaki mantık operatörleri ve açıklamalarından hangileri doğru verilmiştir?
II. < (küçüktür)
III. & (ve)
IV. != (eşittir)
Yukarıdaki mantık operatörleri ve açıklamalarından hangileri doğru verilmiştir?
Seçenekler
A
I ve II
B
II ve III
C
III ve IV
D
Yalnız I
E
I ve IV
Açıklama:
| Operatör | Kullanımı |
| < | Küçüktür |
| > | Büyüktür |
| <= | Küçük ya da eşittir |
| >= | Büyük ya da eşittir |
| == | Eşittir |
| != | Eşit değildir |
| & | Ve |
| | | Veya |
| ! | Değil |
Soru 18
I. sqrt
II. matrix
III. read.fwf
IV. scan
Yukarıdakilerden hangileri hazır veri okuma fonksiyonlarındandır?
II. matrix
III. read.fwf
IV. scan
Yukarıdakilerden hangileri hazır veri okuma fonksiyonlarındandır?
Seçenekler
A
I ve II
B
II ve III
C
I ve III
D
Yalnız III
E
III ve IV
Açıklama:
Çoğunlukla veri setleri başka programlardan hazır olarak elde edilirler. Verinin R yazılımına okutulabilmesi için bir kaç farklı teknik bulunmaktadır. Bu işlem için kullanılabilecek fonksiyonlar sırasıyla; scan() düşük seviyeli veri okutma işlemi, read.table() dosyalardan formatlanmış data frame elde edilmesi işlemi, read.fwf() belirgin bir genişlik tanımlanmış veri dosyalarından okuma işlemi, read.csv() değişkenlerin virgülle ayrıldığı dosyalardan okuma işlemi olur.
Soru 19
Aşağıdaki seçeneklerden hangisinde kütüphanelerde meydana gelen değişimlerin güncellenmesi için kullanılan doğru kavram verilmiştir?
Seçenekler
A
matrix
B
update packages
C
scan
D
return
E
Install packages
Açıklama:
Zaman zaman bu kütüphanelerde meydana gelen değişimlerin güncellenmesi faydalı olacaktır. Bu işlemde yine “Packages” menüsü “update packages” seçeneği yardımıyla gerçekleştirilebilir.
Soru 20
R yazılımında
x<-c(1,3,(t+v),ist,%,3^5) olarak tanımlanan vektörde;
>lenght(x) fonksiyonu yazıldığında elde edilecek değer kaçtır?
x<-c(1,3,(t+v),ist,%,3^5) olarak tanımlanan vektörde;
>lenght(x) fonksiyonu yazıldığında elde edilecek değer kaçtır?
Seçenekler
A
5
B
6
C
7
D
8
E
9
Açıklama:
Önceden tanımlanmış bir vektörün birim sayısını öğrenmek için length () fonksiyonu kullanılır.
length (x)=6
Doğru cevap B şıkkıdır.
length (x)=6
Doğru cevap B şıkkıdır.
Soru 21
R yazılımında;
sayı<-c(3,7,12,4,9,17,2) vektör elemanları küçükten büyüğe doğru sıralanmak istendiğinde yazılacak fonksiyon aşağıdakilerden hangisidir?
sayı<-c(3,7,12,4,9,17,2) vektör elemanları küçükten büyüğe doğru sıralanmak istendiğinde yazılacak fonksiyon aşağıdakilerden hangisidir?
Seçenekler
A
sqrt(sayı)
B
sqrt(c)
C
rep(sayı)
D
seq(sayı)
E
sort(sayı)
Açıklama:
R yazılımında sayıların küçükten büyüğe doğru sıralanması için yazılacak olan fonksiyon sort() fonksiyonudur. Yukarıdaki örnekte bu vektöre atanan değişken ismi "sayı" olduğundan sort(sayı) yazılmalıdır.
Doğru cevap E şıkkıdır.
Doğru cevap E şıkkıdır.
Soru 22
R yazılımında "müdür müdür müdür" ifadesini bir fonksiyonla oluşturmak istediğimizde aşağıdaki fonksiyonların hangisini kullanabiliriz?
Seçenekler
A
sqrt(müdür,3)
B
sort(müdür,3)
C
rep(müdür,3)
D
seq(müdür,3)
E
matrix(müdür)
Açıklama:
Belirli bir düzene sahip verilerin oluşturulması için rep() fonksiyonu kullanılır.
rep(müdür) fonksiyonunun girilmesi durumunda;
"müdür müdür müdür" ifadesi oluşturulur.
Doğru cevap C şıkkıdır.
rep(müdür) fonksiyonunun girilmesi durumunda;
"müdür müdür müdür" ifadesi oluşturulur.
Doğru cevap C şıkkıdır.
Soru 23
R yazılımında;
a<-c(3,5,7,9,11,13,15,17) ifadesi ile elde edilen çıktıyı aşağıdaki fonksiyonlardan hangisi ile elde edebiliriz?
a<-c(3,5,7,9,11,13,15,17) ifadesi ile elde edilen çıktıyı aşağıdaki fonksiyonlardan hangisi ile elde edebiliriz?
Seçenekler
A
seq(3, 17, 2)
B
sqrt(3, 17,2)
C
rep(3, 17, 2)
D
lenght(3, 17, 2)
E
sort(3, 17, 2)
Açıklama:
Belirli bir düzene sahip olan vektörlerin oluşturulmasında seq() fonksiyonu kullanılır. Bu fonksiyonun genel yazılımı seq(altlimit, üstlimit, artış miktarı) şeklindedir.
a<-c(3,5,7,9,11,13,15,17), seq(3, 17, 2) şeklinde de yazılarak aynı çıktı elde edilebilir.
Doğru cevap A şıkkıdır.
a<-c(3,5,7,9,11,13,15,17), seq(3, 17, 2) şeklinde de yazılarak aynı çıktı elde edilebilir.
Doğru cevap A şıkkıdır.
Soru 24
R yazılımda;
x<-c(1,5,3,4)
y<-c(4,2,7,8)
z<-c(3,7,8,6)
vektörleri bir araya getirilmek istendiğinde aşağıdaki fonksiyonlardan hangisi kullanılmalıdır?
x<-c(1,5,3,4)
y<-c(4,2,7,8)
z<-c(3,7,8,6)
vektörleri bir araya getirilmek istendiğinde aşağıdaki fonksiyonlardan hangisi kullanılmalıdır?
Seçenekler
A
data.frame
B
seq.data
C
return
D
boxplot
E
scan
Açıklama:
R yazılımında veri seti içerisindeki faktör listeleri ve gözlem birimleri data frame olarak bir araya getirilirler.
Doğru cevap A şıkkıdır.
Doğru cevap A şıkkıdır.
Soru 25
R yazılımında;
matrix(c(2,3,4,3,2,7,1,2,9,8,7,4,5,6,8),x))
matrisinin 3 satırdan oluşması için x ile gösterilen ifadenin yerine ne yazılmalıdır?
matrix(c(2,3,4,3,2,7,1,2,9,8,7,4,5,6,8),x))
matrisinin 3 satırdan oluşması için x ile gösterilen ifadenin yerine ne yazılmalıdır?
Seçenekler
A
ncol=3
B
nrow=3
C
nrow=5
D
3
E
5
Açıklama:
R yazılımında matris oluşturmak için matrix() fonksiyonu kullanılır. Bu fonksiyonun genel
yazılımı;
matrix(veri, nrow(satırsayısı), ncol(sütünsayısı) şeklindedir. x yerine; nrow=3 veya ncol=5 yazılması durumunda 3 satırdan oluşan bir matris elde edilebilir.
Doğru cevap B şıkkıdır.
yazılımı;
matrix(veri, nrow(satırsayısı), ncol(sütünsayısı) şeklindedir. x yerine; nrow=3 veya ncol=5 yazılması durumunda 3 satırdan oluşan bir matris elde edilebilir.
Doğru cevap B şıkkıdır.
Soru 26
R yazılımda matematik dersinde alınan notlar x vektöründe tanımlanmıştır. Notları 45 üzerinde olan öğrenci sayıları belirlenmek istenmektedir. Bunun için ilgili satıra yazılması gereken fonksiyon aşağıdakilerden hangisidir?
Seçenekler
A
x[x>45]
B
x[x<45]
C
X[X>45]
D
lenght(x[x>45])
E
sort(x[x>45])
Açıklama:
R yazılımında ve genel olarak diğer yazılımlarda içten dışa doğru işlemler yapılır. lenght(x[x>45]) ifadesinde x[x>45] ile 45'ten büyük notlar belirlenir. length fonksiyonu ile de bu notların kaç tane olduğu bulunur. Ayrıca değişken isimleri küçük-büyük harflere duyarlıdır yani x, X eşit değildir.
Doğru cevap D şıkkıdır.
Doğru cevap D şıkkıdır.
Soru 27
Microsoft EXCEL programıyla hazırlanmış bir dosya, R yazılımı yardımıyla işlenmiş veri haline getirilerek gerekli sonuçlar elde edilmek istenmektedir. Bu EXCEL dosyasının R yazılımında çalışabilmesi için hangi uzantıya sahip olması gerekir?
Seçenekler
A
exe
B
pdf
C
csv
D
png
E
djvu
Açıklama:
Microsoft Excel dosyalarından okuma işlemleri gerçekleştirilirken, her bir çalışma sayfası “csv” dosyası olarak kaydedilerek daha sonra bunların her biri read.csv() fonksiyonu ile elde edilebilir.
Doğru cevap C şıkkıdır.
Doğru cevap C şıkkıdır.
Soru 28
3x3 tipinde x ve y gibi iki kare matris çarpımı yapabilmek için ilgili satıra aşağıdakilerden hangisi yazılmalıdır?
Seçenekler
A
x*y
B
x3**y3
C
x&*y
D
x%*%y
E
x.y
Açıklama:
x ve y gibi iki kare matris çarpımı yapabilmek için ilgili satıra x%*%y yazılmalıdır. Matris iç çarpımı yapabilmek için ise, x*y yazılmalıdır. Kısacası %*% işlemi matris çarpımı için kullanılır.
Doğru cevap D şıkkıdır.
Doğru cevap D şıkkıdır.
Soru 29
R yazılımında iki sayının toplamını (örneğin 72+45) hesaplamak için komut satırına yazılması gereken ifade aşağıdakilerden hangisidir?
Seçenekler
A
> 72 + 45
B
> 72 + 45 ?
C
> 72 + 45 = ?
D
> ? 72 + 45
E
> 72 + 45 > ?
Açıklama:
Herhangi bir atama yapılması ya da matematiksel bir ifadenin hesaplanması için en basit komutlar olarak meydana çıkan komutlar grubudur. Örneğin; R Console’da
> 72+45
komutu yazılarak Enter’a basıldığında
[1] 117
sonucu ekranda görüntülenecektir. Matematiksel işlemin hemen sonucunu elde etmek yerine sonuçlar herhangi bir değişkene de atanabilir. Bu atama işlemi için “değişken <- işlem” yapısı kurulmalıdır. Örneğin önceki toplam x gibi bir değişkene atanmak istenirse > x <- 72+45 komutunun verilmesi yeterli olacaktır. Yeni bir atama yapılmadığı sürece x değişkeni bu toplamın sonucundan oluşacaktır.
Bu nedenle doğru yanıt a) seçeneğidir.
> 72+45
komutu yazılarak Enter’a basıldığında
[1] 117
sonucu ekranda görüntülenecektir. Matematiksel işlemin hemen sonucunu elde etmek yerine sonuçlar herhangi bir değişkene de atanabilir. Bu atama işlemi için “değişken <- işlem” yapısı kurulmalıdır. Örneğin önceki toplam x gibi bir değişkene atanmak istenirse > x <- 72+45 komutunun verilmesi yeterli olacaktır. Yeni bir atama yapılmadığı sürece x değişkeni bu toplamın sonucundan oluşacaktır.
Bu nedenle doğru yanıt a) seçeneğidir.
Soru 30
R dilinde bir değişkene değer ataması yapılması (örneğin, 72 + 45 toplamının sonucunun x değişkenine atanması) için kullanılan söz dizimi aşağıdaki seçeneklerden hangisinde doğru uygulanmıştır?
Seçenekler
A
> x <- 72 + 45
B
> 72 + 45 -> x
C
> x = 72 + 45
D
> 72 + 45 = x
E
> x eşittir 72 + 45
Açıklama:
Matematiksel işlemin hemen sonucunu elde etmek yerine sonuçlar herhangi bir değişkene de atanabilir. Bu atama işlemi için “değişken <- işlem” yapısı kurulmalıdır. Örneğin önceki 72 + 45 toplamı x gibi bir değişkene atanmak istenirse
> x <- 72+45
komutunun verilmesi yeterli olacaktır. Yeni bir atama yapılmadığı sürece x değişkeni bu toplamın sonucundan oluşacaktır.
Bu nedenle doğru yanıt a) seçeneğidir.
> x <- 72+45
komutunun verilmesi yeterli olacaktır. Yeni bir atama yapılmadığı sürece x değişkeni bu toplamın sonucundan oluşacaktır.
Bu nedenle doğru yanıt a) seçeneğidir.
Soru 31
Aşağıdaki R komutları uygulandığında ekranda hangi sonuç görüntülenir? > isim <- c(“Defne”, “Kuzey”, “Alara”, “Miray”) > yenix <- c(isim, 17, 22, 45) > length(yenix)
Seçenekler
A
[1] 7
B
[1] 3
C
[1] 4
D
[1] 8
E
[1] 12
Açıklama:
R yazılımının en büyük özelliklerinden biri de değişkenler ile çalışılırken vektör ve matris kullanımına olanak tanımasıdır. En basit şekliyle bir vektörü oluşturabilmek için c() fonksiyonu kullanılmaktadır. Daha önce kullanılan x değişkenini 5 birimlik bir vektör hâline dönüştürme işlemi ve sonucu aşağıda verilmiştir.
> x <- c(1,2,3,4,5)
> x
[1] 1 2 3 4
5 Görüldüğü gibi burada ilk satırda x vektörüne 5 adet değer atanmakta ikinci satırda ise x’e ataması yapılan değerlerin görüntülenmesi komutu verilmektedir. Bu noktada önemli olan konu; R yazılımının büyük ve küçük harfe olan duyarlılığıdır. X ve x değişkenleri tamamen farklı değişkenlerdir. Önceden tanımlanmış bir vektörün birim sayısını öğrenmek için length() fonksiyonu kullanılır. Örnekteki birim sayısı aşağıdaki gibi öğrenilebilir.
> length(x)
[1] 5
c() fonksiyonu karakter değişkenleri yaratmak için de kullanılır. 4 isimden oluşan isim değişkenini c() fonksiyonunu kullanarak oluşturunuz. 4 isimden oluşan isim değişkeni aşağıdaki gibi oluşturulabilir.
> isim <- c(“Defne”, “Kuzey”, “Alara”, “Miray”)
> isim
[1] “Defne” “Kuzey” “Alara” “Miray”
Ayrıca, c() fonksiyonu birden fazla vektörün tek bir vektör olarak birleştirilmesinde ya da karakter değişkeninin sayılarla birleştirilmesinde de kullanılabilir. Yukarıdaki örnekteki isim değişkenine 17, 22, 45 rakamlarını ekleyerek yenix değişkenini oluşturmak için aşağıdaki işlemler yapılmalıdır.
> yenix <- c(isim, 17, 22, 45)
> yenix
[1] “Defne” “Kuzey” “Alara” “Miray” “17” “22” “45”
Elde edilen yenix dizisinin öğe sayısı 7 olmuştur.
> length(yenix)
Komutu ile
[1] 7
Sonucu elde edilecektir.
Bu nedenle doğru yanıt A seçeneğidir.
> x <- c(1,2,3,4,5)
> x
[1] 1 2 3 4
5 Görüldüğü gibi burada ilk satırda x vektörüne 5 adet değer atanmakta ikinci satırda ise x’e ataması yapılan değerlerin görüntülenmesi komutu verilmektedir. Bu noktada önemli olan konu; R yazılımının büyük ve küçük harfe olan duyarlılığıdır. X ve x değişkenleri tamamen farklı değişkenlerdir. Önceden tanımlanmış bir vektörün birim sayısını öğrenmek için length() fonksiyonu kullanılır. Örnekteki birim sayısı aşağıdaki gibi öğrenilebilir.
> length(x)
[1] 5
c() fonksiyonu karakter değişkenleri yaratmak için de kullanılır. 4 isimden oluşan isim değişkenini c() fonksiyonunu kullanarak oluşturunuz. 4 isimden oluşan isim değişkeni aşağıdaki gibi oluşturulabilir.
> isim <- c(“Defne”, “Kuzey”, “Alara”, “Miray”)
> isim
[1] “Defne” “Kuzey” “Alara” “Miray”
Ayrıca, c() fonksiyonu birden fazla vektörün tek bir vektör olarak birleştirilmesinde ya da karakter değişkeninin sayılarla birleştirilmesinde de kullanılabilir. Yukarıdaki örnekteki isim değişkenine 17, 22, 45 rakamlarını ekleyerek yenix değişkenini oluşturmak için aşağıdaki işlemler yapılmalıdır.
> yenix <- c(isim, 17, 22, 45)
> yenix
[1] “Defne” “Kuzey” “Alara” “Miray” “17” “22” “45”
Elde edilen yenix dizisinin öğe sayısı 7 olmuştur.
> length(yenix)
Komutu ile
[1] 7
Sonucu elde edilecektir.
Bu nedenle doğru yanıt A seçeneğidir.
Soru 32
R yazılımında sıfırdan sekize kadar 2’er artan rakamlardan oluşan vektörü oluşturmak için aşağıdaki komutlardan hangisi kullanılır?
Seçenekler
A
> seq(0, 8, 2)
B
> rep(0, 8, 2)
C
> c(0, 8, 2)
D
> sqrt(0, 8, 2)
E
> seq(rep(0, 8, 2))
Açıklama:
Sıfırdan sekize kadar 1’er artan rakamlardan oluşan vektör için aşağıdaki işlemler yapılır.
> seq(0, 8, 1)
[1] 0 1 2 3 4 5 6 7 8
Dörtten on altıya kadar 4’er artan rakamlardan oluşan vektör için aşağıdaki işlemler yapılır.
> seq(4, 16,4)
[1] 4 8 12 16
Bu nedenle doğru yanıt a) seçeneğidir.
> seq(0, 8, 1)
[1] 0 1 2 3 4 5 6 7 8
Dörtten on altıya kadar 4’er artan rakamlardan oluşan vektör için aşağıdaki işlemler yapılır.
> seq(4, 16,4)
[1] 4 8 12 16
Bu nedenle doğru yanıt a) seçeneğidir.
Soru 33
R yazılımında
> matrix(c(6,5,4,3,2,1,1,2,3,4,5,6),ncol=2)
Komutu ile oluşturulan matrisin görünümü aşağıdakilerden hangisi olacaktır?
> matrix(c(6,5,4,3,2,1,1,2,3,4,5,6),ncol=2)
Komutu ile oluşturulan matrisin görünümü aşağıdakilerden hangisi olacaktır?
Seçenekler
A
[,1] [,2]
[1,] 6 1
[2,] 5 2
[3,] 4 3
[4,] 3 4
[5,] 2 5
[6,] 1 6
[1,] 6 1
[2,] 5 2
[3,] 4 3
[4,] 3 4
[5,] 2 5
[6,] 1 6
B
[,1] [,2]
[1,] 1 1
[2,] 2 2
[3,] 3 3
[4,] 4 4
[5,] 5 5
[6,] 6 6
[1,] 1 1
[2,] 2 2
[3,] 3 3
[4,] 4 4
[5,] 5 5
[6,] 6 6
C
[,1] [,2]
[1,] 1 6
[2,] 2 5
[3,] 3 4
[4,] 4 3
[5,] 5 2
[6,] 6 1
[1,] 1 6
[2,] 2 5
[3,] 3 4
[4,] 4 3
[5,] 5 2
[6,] 6 1
D
[,1] [,2]
[1,] 6 6
[2,] 5 5
[3,] 4 4
[4,] 3 3
[5,] 2 2
[6,] 1 1
[1,] 6 6
[2,] 5 5
[3,] 4 4
[4,] 3 3
[5,] 2 2
[6,] 1 1
E
[,1] [,2]
[1,] 1 4
[2,] 2 5
[3,] 3 6
[4,] 3 6
[5,] 2 5
[6,] 1 4
[1,] 1 4
[2,] 2 5
[3,] 3 6
[4,] 3 6
[5,] 2 5
[6,] 1 4
Açıklama:
Birçok araştırmada, yapılan analizler sırasında matris oluşturulması gerekmektedir. R yazılımında matris oluşturmak için matrix() fonksiyonu kullanılır. Bu fonksiyonun genel yazılımı; matrix(veri, nrow(satırsayısı), ncol(sütünsayısı), byrow=F(veri sütun olarak girilsin)) şeklindedir. 2 değişken ve 6 gözlem değerinden oluşan veri seti için iki sütun ve altı satırlık bir matris oluşturalım. Veriyi hem matrix() komutu içerisinde hem de bir değişken kullanarak atayalım. Veri, matrix() komutu içinde aşağıdaki gibi oluşturulabilir.
> matrix(c(6,5,4,3,2,1,1,2,3,4,5,6),ncol=2)
[,1] [,2]
[1,] 6 1
[2,] 5 2
[3,] 4 3
[4,] 3 4
[5,] 2 5
[6,] 1 6
Bu nedenle doğru yanıt a) seçeneğidir.
> matrix(c(6,5,4,3,2,1,1,2,3,4,5,6),ncol=2)
[,1] [,2]
[1,] 6 1
[2,] 5 2
[3,] 4 3
[4,] 3 4
[5,] 2 5
[6,] 1 6
Bu nedenle doğru yanıt a) seçeneğidir.
Soru 34
R yazılımında bir matrisin (Örneğin, matris2 isimli bir matrisin) evriği ile matris çarpımı aşağıdaki komutlardan hangisi ile elde edilebilir?
Seçenekler
A
> matris2 %*% t(matris2)
B
> matris2 * t(matris2)
C
> matris2 %+% t(matris2)
D
> t(matris2) %*% matris2
E
> t(matris2) * matris2
Açıklama:
R dilinde matris çarpımı %*% operatörü ile yapılır. Matris çarpımında A%*%B ile B%*%A birbirine eşit değildir. Bir matrisin evriği t(matris) işlevi ile hesaplanır. Bu durumda matris2 isimli bir matrisi kendi evriği ile çarpmak
> matris2 %*% t(matris2)
İle gerçekleştirilir.
Bu nedenle doğru yanıt a) seçeneğidir.
> matris2 %*% t(matris2)
İle gerçekleştirilir.
Bu nedenle doğru yanıt a) seçeneğidir.
Soru 35
R yazılımında çeşitli istatistiksel analizler için oluşturulan farklı nesnelerin bir araya getirilmesinde aşağıdaki komutların hangisinden faydalanılır?
Seçenekler
A
list
B
data.frame
C
matris
D
c()
E
seq
Açıklama:
Çeşitli istatistiksel analizler için oluşturulan farklı nesnelerin bir araya getirilmesinde List Nesnelerinden faydalanılır. Örneğin; ilgilenilen veri kümesi ile bunlara ait korelasyon matrisi aynı nesne içerisinde görüntülenebilir (ya da hafızada birlikte saklanmaları sağlanabilir). Bu nedenle doğru yanıt a) seçeneğidir.
Soru 36
R yazılımında veri seti içerisindeki faktör listeleri ve gözlem birimlerini bir araya getirmek için aşağıdakilerden hangisi kullanılır?
Seçenekler
A
data.frame
B
list
C
matris
D
c()
E
seq
Açıklama:
Birçok araştırmada ilgilenilen değişkenin çeşitli seviyeleri ve bu seviyeler için gözlem değerleri bulunmaktadır. R yazılımında veri seti içerisindeki faktör listeleri ve gözlem birimleri data frame olarak bir araya getirilirler. “data.frame” fonksiyonunda her sütunda eşit sayıda birim yer almaktadır. Her satır bir gözlem birimini temsil etmektedir. Örneğin; 8 adet öğrencinin 4 farklı dersten aldıkları başarı puanları bir değişkende bir araya getirilebilir.
Soru 37
R dilinde yazılmış olan aşağıdaki kullanıcı tanımlı fonksiyon dikkate alındığından aşağıdaki seçeneklerden hangisindeki ifade doğru değildir?
> ozetle<-function(veri)
{ # BU FONKSİYON VERİNİN ÖZETLEYİCİ İSTATİSTİKLERİNİ HESAPLAR VE GÖRÜNTÜLER
+ozet<-summary(veri)
+sapma<-var(veri)
+return(ozet,sapma)
+}
> ozetle<-function(veri)
{ # BU FONKSİYON VERİNİN ÖZETLEYİCİ İSTATİSTİKLERİNİ HESAPLAR VE GÖRÜNTÜLER
+ozet<-summary(veri)
+sapma<-var(veri)
+return(ozet,sapma)
+}
Seçenekler
A
Fonksiyonun dışarıdan verilen parametresi “ozet” değişkeninde tutulmaktadır.
B
Fonksiyonun dışarıdan verilen parametresi “veri” değişkeninde tutulmaktadır.
C
Fonksiyon “ozet” ve “sapma” değerlerini döndürmektedir.
D
Fonksiyon “veri” değeri üzerinde “summary” ve “var” işlemlerini gerçekleştirmektedir.
E
Fonksiyonun adı “özetle” dir.
Açıklama:
R yazılımında hazır yazılmış fonksiyonlar bazen analizler için yeterli olmayabilir. Bu tür durumlar için kullanıcılar kendi fonksiyonlarını yazabilirler. R yazılımında bu işlem function (parametreler) komutu yardımıyla gerçekleştirilir. Yukarıdaki örnekte “özetle” fonksiyonunun parametresi “veri” değişkendir. Bu nedenle doğru yanıt a) seçeneğidir.
Soru 38
R yazılımında değişkenlerin virgülle birbirinden ayrıldığı veri dosyalarını okumak için aşağıdaki işlevlerden hangisi kullanılır?
Seçenekler
A
read.csv()
B
scan()
C
read.table()
D
read.fwf()
E
load
Açıklama:
Çoğunlukla veri setleri başka programlardan hazır olarak elde edilirler. Verinin R yazılımına okutulabilmesi için bir kaç farklı teknik bulunmaktadır. Bu işlem için kullanılabilecek fonksiyonlar sırasıyla; scan() düşük seviyeli veri okutma işlemi, read.table() dosyalardan formatlanmış data frame elde edilmesi işlemi, read.fwf() belirgin bir genişlik tanımlanmış veri dosyalarından okuma işlemi, read.csv() değişkenlerin virgülle ayrıldığı dosyalardan okuma işlemi olur. Özellikle Microsoft Excel dosyalarından okuma işlemleri gerçekleştirilirken, her bir çalışma sayfası “csv” dosyası olarak kaydedilerek daha sonra bunların her biri read.csv() fonksiyonu ile elde edilebilir. Bu nedenle doğru yanıt a) seçeneğidir.
Soru 39
R yazılımı ile ilgili olarak verilen ifadelerden hangisi veya hangileri doğrudur?
I-R yazılımı kullanılarak, istatistiksel analiz, grafik çizme ve veri işleme işlemleri yapılabilir.
II-R yazılımının kaynak kodu açık bir şekilde sunulmaktadır.
III-R yazılımı ücretli bir programdır.
IV-R yazılımın en büyük üstünlüklerinden biri de hemen hemen bütün işletim sistemlerinde çalışabilmektedir.
V-Temel olarak R, Becker and Chembers tarafından geliştirilen S dilinin bir çeşididir.
I-R yazılımı kullanılarak, istatistiksel analiz, grafik çizme ve veri işleme işlemleri yapılabilir.
II-R yazılımının kaynak kodu açık bir şekilde sunulmaktadır.
III-R yazılımı ücretli bir programdır.
IV-R yazılımın en büyük üstünlüklerinden biri de hemen hemen bütün işletim sistemlerinde çalışabilmektedir.
V-Temel olarak R, Becker and Chembers tarafından geliştirilen S dilinin bir çeşididir.
Seçenekler
A
I-II-IV-V
B
I-II-III-IV-V
C
I-II-III
D
II-III-V
E
I-III-IV
Açıklama:
R yazılımı İnternet aracılığı ile ücretsiz olarak dağıtılan genel lisanslı bir programdır. Yazılım, lisans kapsamında serbest bir şekilde dağıtılabilir ve kullanılabilir. Ayrıca yazılımı elde eden herkes asıl kaynağı belirterek dağıtma ve kullanma hakkına sahiptir. Yazılımın kaynak kodu da açık bir şekilde sunulmaktadır. Dolayısıyla herhangi bir programlama bilgisine sahip kişiler bu kod üzerinde değişiklikler ve geliştirmeler yapma hakkına sahiptir. Yazılımın en büyük üstünlüklerinden biri de hemen hemen bütün işletim sistemlerinde çalışabiliyor olmasıdır. R yazılımı kullanılarak, istatistiksel analiz, grafik çizme ve veri isleme işlemleri yapılabilir. Doğru cevap A'dır.
Soru 40
Windows işletim sistemi için derlenmiş programa hangi linkten ulaşılabilmektedir?
Seçenekler
A
R for office
B
Base
C
Download R for Windows
D
R Console
E
Temel komutlar
Açıklama:
Windows işletim sistemi için derlenmiş program “Download R for Windows” linkinde yer
almaktadır. Doğru cevap C'dir.
almaktadır. Doğru cevap C'dir.
Soru 41
R yazılımında komutların girilmesi için kullanılan bölgeye ne ad verilmektedir?
Seçenekler
A
Temel komutlar
B
R console
C
c () fonksiyonu
D
Arayüz
E
Define
Açıklama:
Komutların girilmesi için kullanılan bölgeye “R Console” denir. Doğru cevap B'dir.
Soru 42
R yazılımında bir vektör oluşturabilmek için aşağıdakilerden hangisi kullanılmaktadır?
Seçenekler
A
sqrt() fonksiyonu
B
rep() fonksiyonu
C
matrix() fonksiyonu
D
c() fonksiyonu
E
length() fonksiyonu
Açıklama:
R yazılımında bir vektör c() fonksiyonu ile oluşturulabilmektedir. Doğru cevap D'dir.
Soru 43
sqrt() fonksiyonu yardımı ile aşağıdaki ifadelerden hangisi gerçekleştirilebilmektedir?
Seçenekler
A
Belirli bir düzene sahip verileri oluşturma
B
Bir değişkenin karekökünü hesaplama
C
Önceden tanımlanmısş bir vektörün birim sayısını öğrenme
D
Matris oluşturma
E
Mantıksal fonksiyonlar
Açıklama:
Bir değişkenin karekökü sqrt() fonksiyonu yardımıyla hesaplanabilir. Doğru cevap B'dir.
Soru 44
R yazılımında read.csv() ile hangi işlem gerçekleştirilebilmektedir?
Seçenekler
A
Düşük seviyeli veri okutma işlemi,
B
belirgin bir genişlik tanımlanmış veri dosyalarından okuma işlemi
C
Değişkenlerin virgülle ayrıldığı dosyalardan okuma işlemi
D
veriseti.csv kayıt işlemi
E
Dosyalardan formatlanmış data frame elde edilmesi işlemi
Açıklama:
read.csv() fonksiyonu ile değişkenlerin virgülle ayrıldığı dosyalardan okuma işlemi gerçekleştirilir. Doğru cevap C'dir.
Soru 45
Başka kullanıcılar ya da R projesi ekibi tarafından oluşturulan ek kütüphanelere hangi seçenek ile ulaşılabilmektedir?
Seçenekler
A
Packages menüsündan Install Package(s) seçeneği ile
B
Cran ile
C
Html Help seçeneği ile
D
Update packages seçeneği ile
E
Edit menüsü ile
Açıklama:
Başka kullanıcılar ya da R projesi ekibi tarafından oluşturulan ek kütüphaneler “Packages” menüsündan “Install Package(s)” seçeneği yardımıyla yürütülebilir. Doğru cevap A'dır.
Soru 46
R yazılımında veri seti içerisindeki faktör listeleri ve gözlem birimleri nasıl bir araya getirilebilmektedir?
Seçenekler
A
Data frame
B
rep()
C
Length()
D
Packages
E
R Console
Açıklama:
R yazılımında veri seti içerisindeki faktör listeleri ve gözlem birimleri data frame olarak bir araya getirilirler. Doğru cevap A'dır.
Soru 47
Bir veri kümesi ile bunlara ait korelasyon matrisinin aynı nesne içerisinde görüntülenebilmesi aşağıdakilerin hangisi ile sağlanabilmektedir?
Seçenekler
A
$korelasyon<<
B
TRUE
C
List nesneleri
D
Mantık operatörü
E
Data frame
Açıklama:
Çeşitli istatistiksel analizler için oluşturulan farklı nesnelerin bir araya getirilmesinde
List Nesnelerinden faydalanılır. Örneğin; ilgilenilen veri kümesi ile bunlara ait korelasyon
matrisi aynı nesne içerisinde görüntülenebilir. Doğru cevap C'dir.
List Nesnelerinden faydalanılır. Örneğin; ilgilenilen veri kümesi ile bunlara ait korelasyon
matrisi aynı nesne içerisinde görüntülenebilir. Doğru cevap C'dir.
Soru 48
R yazılımı ile sıfırdan ona kadar ikişer artan rakamlardan oluşan bir vektör nasıl oluşturulabilir?
Seçenekler
A
>length (8,8,2)
B
0 1 2 3 4 5 6 7 8
C
[2] 0 1 2 3 4 5 6 7
D
[2] 2 - 8
E
> seq (0, 10, 2)
[2] 0 2 4 6 8 10
[2] 0 2 4 6 8 10
Açıklama:
Belirli bir düzene sahip olan vektörlerin oluşturulmasında da seq() fonksiyonu kullanılır.
Bu fonksiyonun genel yazılımı seq(altlimit, üstlimit, artışmiktarı) şeklindedir. Doğru cevap E'dir.
>seq (0, 10, 2)
[2] 0 2 4 6 8 10
Bu fonksiyonun genel yazılımı seq(altlimit, üstlimit, artışmiktarı) şeklindedir. Doğru cevap E'dir.
>seq (0, 10, 2)
[2] 0 2 4 6 8 10
Soru 49
R yazılım aşağıda yer alan hangi adres yardımıyla temin edilebilir?
Seçenekler
A
www.cran.com
B
www.rpr.com
C
www.r-project.org
D
www.rinwindows.com
E
www.rformac.org
Açıklama:
www.r-project.org üzerinden ilgili işletim sistemine uygun sürüm elde edilebilir.
Soru 50
R yazılımı ne kadar bir ücret karşılığında temin edilir?
Seçenekler
A
Ücretsizdir, internet üzerinden indirilir
B
Üyelik ile 10 Dolar ücret karşılığı internet üzerinden indirilir
C
150 dolar ödenerek CDle temin edilir
D
250 Dolar karşılığı CD veya internet üzerinden indirilir
E
1500 dolar yıllık üyelik aidatı vardır.
Açıklama:
R istatistiksel bilgisayar yazılımı İnternet aracılığı ile dağıtılmaktadır. İsteyen kullanıcılar programın ana sitesini kullanarak ücreti karşılığında CD üzerinden de programı elde edebilmektedirler. Programın lisansı, genel kullanıcı lisansı türündendir. Bu lisans, kullanıcılara ellerinde bulundurdukları programı serbestçe dağıtma ve kullanma hakkını vermektedir. Sadece bu lisans kapsamında ürünü elde eden kişiler aynı hakka sahip olabilmektedir. Ayrıca kullanıcılar kaynak kodun kendisini de ücretsiz olarak elde edebilmektedirler. Microsoft Windows, Linux ve Unix sistemleri ve Apple MacOS işletim sistemleri için çeşitli sürümler elde edilebilmektedir.
Soru 51
Standart R yazılımında komutların girilmesi için ayrılan bölgeye ne ad verilir?
Seçenekler
A
R Help
B
Rcmdr
C
R Console
D
R Graph
E
R data
Açıklama:
Komutların girilmesi için kullanılan bölgeye “R Console” denir.
Soru 52
R yazılımında console üzerinden >85+15 komutu işletildiğinde karşımıza çıkan sonuç görüntüsü seçeneklerden hangisinde yer almaktadır?
Seçenekler
A
> 100
B
--> 100
C
<- 100
D
[1] 100
E
[3,4] 100
Açıklama:
Herhangi bir atama yapılması ya da matematiksel bir ifadenin hesaplanması için en basit komutlar olarak meydana çıkan komutlar grubudur. Örneğin; R Console’da
> 85+15
komutu yazılarak Enter’a basıldığında
[1] 100
sonucu ekranda görüntülenecektir.
> 85+15
komutu yazılarak Enter’a basıldığında
[1] 100
sonucu ekranda görüntülenecektir.
Soru 53
Herhangi bir komut için yardım istendiğinde (örneğin mean) seçeneklerden hangisi ilgili komutun yardım bilgisini getirir?
Seçenekler
A
> Search(mean)
B
> search.help.mean()
C
> x<- mean(x)
D
> help(mean)
E
> help.base(mean)
Açıklama:
R ile çalışırken herhangi bir fonksiyon ya da kitaplık hakkında yardım almanın iki yolu vardır. Öncelikle aritmetik ortalama hesabında kullanılan mean() komutunu bildiğimizi varsayalım. Bu fonksiyonun hangi parametreleri aldığını ve diğer ayrıntıları görebilmek için
help(mean)
komutunun verilmesi yeterli olacaktır.
help(mean)
komutunun verilmesi yeterli olacaktır.
Soru 54
R'de oluşturulmuş bir vektörün birim sayısı hangi komut ile bulunur?
Seçenekler
A
mean()
B
length()
C
dist()
D
area()
E
ort()
Açıklama:
Önceden tanımlanmış bir vektörün birim sayısını öğrenmek için length() fonksiyonu kullanılır.
Soru 55
aşağıda verilen komutta 6 isimlik bir öğrenci isim listesi oluşturulmak istenmektedir. Burada yapılan hata nedir?
> isim<-c("Ayşe","Fatma","Mualla","Kezban,"Şahika","Betül")
> isim<-c("Ayşe","Fatma","Mualla","Kezban,"Şahika","Betül")
Seçenekler
A
isim değişkeni önceden tanımlanmamış
B
isimler çok kısa
C
isimler çok uzun
D
atama komut işareti hatalı
E
İsimlerden birinde tırnak işareti unutulmuş
Açıklama:
4 isimden oluşan isim değişkenini c() fonksiyonunu kullanarak oluşturunuz.
4 isimden oluşan isim değişkeni aşağıdaki gibi oluşturulabilir.
> isim <- c(“Defne”, “Kuzey”, “Alara”, “Miray”)
> isim
[1] “Defne” “Kuzey” “Alara” “Miray”
Ayrıca, c() fonksiyonu birden fazla vektörün tek bir vektör olarak birleştirilmesinde ya da karakter değişkeninin sayılarla birleştirilmesinde de kullanılabilir.
4 isimden oluşan isim değişkeni aşağıdaki gibi oluşturulabilir.
> isim <- c(“Defne”, “Kuzey”, “Alara”, “Miray”)
> isim
[1] “Defne” “Kuzey” “Alara” “Miray”
Ayrıca, c() fonksiyonu birden fazla vektörün tek bir vektör olarak birleştirilmesinde ya da karakter değişkeninin sayılarla birleştirilmesinde de kullanılabilir.
Soru 56
Verilen komut sonucu ortaya çıkan seri seçeneklerden hangisinde yer almaktadır?
seq(0, 8, 1)
seq(0, 8, 1)
Seçenekler
A
[] 1,2,3,4,5,6,7,8
B
[2] 1,2,3,4,5,6,7,8
C
[1] 0,1,2,3,4,5,6,7,8
D
[] 0,1,2,3,4,5,6,8
E
[3,4] 1,2,3,4,5
Açıklama:
Sıfırdan sekize kadar 1’er artan rakamlardan oluşan vektörü oluşturunuz.
Sıfırdan sekize kadar 1’er artan rakamlardan oluşan vektör için aşağıdaki işlemler yapılır.
> seq(0, 8, 1)
[1] 0 1 2 3 4 5 6 7 8
Sıfırdan sekize kadar 1’er artan rakamlardan oluşan vektör için aşağıdaki işlemler yapılır.
> seq(0, 8, 1)
[1] 0 1 2 3 4 5 6 7 8
Soru 57
Aşağıda verilen komut sonucunda seride elde edilecek en büyük sayı nedir?
rep(seq(1,6),2)
rep(seq(1,6),2)
Seçenekler
A
1
B
2
C
4
D
6
E
8
Açıklama:
1’den 6’ya kadar olan rakamları 2 tekrar olacak biçimde içeren vektör aşağıdaki işlem- ler yardımıyla oluşturulur.
> rep(seq(1,6),2)
[1] 1 2 3 4 5 6 1 2 3 4 5 6
> rep(seq(1,6),2)
[1] 1 2 3 4 5 6 1 2 3 4 5 6
Soru 58
"!=" mantık operatörü ne anlama gelir?
Seçenekler
A
Eşittir
B
Büyük yada eşittir
C
Veya
D
Ve
E
Eşit değildir
Açıklama:
| != | Eşit değildir |
Soru 59
R, temel olarak hangi programlama dilinin bir çeşididir?
Seçenekler
A
S
B
C+
C
Python
D
Javascript
E
Ruby
Açıklama:
R, S programla dili temelinde geliştirilmiştir.
Soru 60
Bir vektörü en basit biçimiyle yaratmak için aşağıdaki komutlardan hangisine ihtiyaç duyulur?
Seçenekler
A
length()
B
help()
C
head()
D
c()
E
seq()
Açıklama:
doğru yanıt c()'dir.
Soru 61
2'den 8'e kadar olan rakamlardan ikişerli artacak biçimde bir vektör oluşturmak için aşağıdaki kodlardan hangisi kullanılmalıdır?
Seçenekler
A
seq(2, 8)
B
seq(2, 8, 2)
C
rep(2, 8)
D
rep(2, 8, 2)
E
head(2-8)
Açıklama:
Belirli bir düzene sahip vektör yaratmak için seq() komutu kullanılır. İlk önce başlangıç rakamı, sonra ulaşılacak rakam ve en son da düzenli artış miktarı yazılmalıdır.
Soru 62
xy ismiyle kaydettiğimiz matrisimizin ikinci satırının dördüncü sütunun yer alan değer görmek için hangi komut kullanılmalıdır?
Seçenekler
A
xy[,3]
B
xy[ , 4, 2]
C
xy[2, 4]
D
xy[4, 2]
E
xy[]
Açıklama:
cevap C seçeneğidir. İlk önce satır no, sonrasında ise sütun no yazılmalıdır.
Soru 63
Özlem, Veri Madenciliği dersini alan öğrencilerin isimlerini, yaşlarını, cinsiyetlerini, ara ve final notlarını bir arada görmek istemektedir. Bu amaçla verileri hangi formatta kadetmesi uygun olur?
Seçenekler
A
Data Frame
B
Vektör
C
Matris
D
Liste
E
Mantık Operatörü
Açıklama:
Sütunlarda bir çok nitel ve nicel değişken, satırlarda ise birey ya da objelerin yer aldığı ve satır ve sütunların kesişim noktasında bu birey ve objeler için her bir değişkenin değerinin yer aldığı dosya türü data frame'dir. Bu örnekteki veri, bu nedenle data frame olarak kaydedilmelidir.
Soru 64
Belirli bir düzene sahip verilerin oluşturulması amacıyla kullanılan fonksiyon nedir?
Seçenekler
A
head()
B
kmeans()
C
rep()
D
sqrt()
E
matrix()
Açıklama:
Bu amaçla rep() fonksiyonunun kullanımı uygundur.
Soru 65
1'den 10'a kadar olan sayıları, iki satır ve beş sütundan oluşacak bir matris olarak yaratmak için aşağıdaki kodlardan hangisi kullanılmalıdır?
Seçenekler
A
x <- matrix(1:10, 2, 5)
B
x <- matrix(1:10, 5, 2)
C
x <- (1:10, 2, 5)
D
x <- matrix(1:10, nrow=5, ncol=2)
E
x <- matrix[1:10, 2, 5]
Açıklama:
Bu matrisi oluşturmak için "matrix" komutuyla ilk önce sayılar oluşturulmalı, ikinci adımda satır son adımda ise sütun sayısı yazılmalıdır.
Soru 66
Aşağıdaki mantıksal operatörlerden hangisi, bir değerin diğerine eşit olduğu yönünde bir varsayım için kullanılır?
Seçenekler
A
==
B
=?
C
=!
D
!=
E
>=
Açıklama:
== operatörünün iki yanına yazılan nesnelerin karşılaştırılmasında, iki değerin birbirine eşit olduğu yönündeki soruya cevap vermek için kullanılır. Eğer eşit değiller FALSE dönütü alınacaktır.
Soru 67
Bir excel dosyasından R ortamına veri aktarmak için hangi komut kullanılır?
Seçenekler
A
read.table
B
read.csv()
C
scan()
D
read.file(excel)
E
excel.read.file()
Açıklama:
Doğru yanıt B seçeneğidir.
Soru 68
R'ye ilişkin aşağıda yer alan bilgilerin hangisi yanlıştır?
Seçenekler
A
Açık kaynak kodludur.
B
Ücretli bir yazılımdır.
C
Komutların yazılması için kullanılan bölgeye R Console adı verilir.
D
S dili temel alınarak geliştirilmiştir.
E
Geliştirilmesindeki çekirdek grup, 17 kişiden oluşmaktadır.
Açıklama:
R, açık kaynak kodlu, ücretsiz bir yazılımdır.
Ünite 3
Soru 1
- En büyük özelliği yokluk anlamına gelen belirli bir sıfır değerini barındırıyor olmasıdır.
- Sıfır başlangıç noktası tüm ölçüm araçları için aynı anlamı taşır.
Seçenekler
A
İkili (Binary) Değişkenler
B
İsimsel (Nominal) Değişkenler
C
Sıra Gösteren (Ordinal) Değişkenler
D
Aralıklı Ölçümlendirilmiş (Interval-Scaled) Değişkenler
E
Oranlı Ölçümlendirilmiş (Ratio-Scaled) Değişkenler
Açıklama:
Oranlı Ölçümlendirilmiş (Ratio-Scaled) Değişkenler soruda belirtilen özellikleri taşıyan değişkenlerdir.
Soru 2
Aşağıdakilerden hangisi veri hazırlama süreçlerinden değildir?
Seçenekler
A
Veri toplama
B
Veri temizleme
C
Veri dönüştürme
D
Veri birleştirme
E
Veri indirgeme
Açıklama:
Veri toplama, veri hazırlama süreçlerinden değildir.
Soru 3
Aşağıdakilerden hangisi veri indirgeme yöntemlerinden değildir?
Seçenekler
A
Veri küpü birleştirme
B
Boyut indirgeme
C
Gürültü indirgeme
D
Büyük sayıların indirgenmesi
E
Veri sıkıştırma
Açıklama:
Gürültü indirgeme, veri indirgeme yöntemlerinden değildir.
Soru 4
- Sıkıştırma
- Düzeltme
- Bir araya getirme
- İndirgeme
- Normalleştirme
Seçenekler
A
I, II ve III
B
I, III ve IV
C
II, III ve V
D
II, IV ve V
E
III, IV ve V
Açıklama:
Düzeltme, bir araya getirme, normalleştirme ve özellik oluşturma verilerin veri madenciliği için uygun formlara dönüştürülmesi için kullanılan işlemlerdendir.
Soru 5
Minimum değeri 120 maksimum değeri 440 olan bir değişkenin, 200 değerinin enk-enb normalleştirme yöntemine göre dönüşümü sonucu kaçtır?
Seçenekler
A
-0,1
B
-0,40
C
0,25
D
0,50
E
0,75
Açıklama:
X veri değeri ise; (X-Xmin)/(Xmax-Xmin)=(200-120)/(440-120)=80/320=0,25
Soru 6
Minimum değeri 100 olan bir değişkenin 300 değerinin enk-enb normalleştirme yöntemine göre dönüşümü sonucu 0,5 ise değişkenin maksimum değeri kaçtır?
Seçenekler
A
400
B
500
C
600
D
800
E
1000
Açıklama:
(X-Xenk)/(Xenb-Xenk)=0,50 ise (300-100)/(Xenb-100)=0,5 Xenb yani maksimum değeri 500'dür.
Soru 7
X=[120,150,180,190] gözlem değerleri verilen değişkende 150 değeri için z-skor normalleştirme yöntemine göre dönüşüm değeri kaçtır?
Seçenekler
A
0,255
B
0,478
C
-0,505
D
-0,316
E
-0,229
Açıklama:
X*=(X-Xaort)/s Xaort: değişken değerlerin aritmetik ortalaması, s: standart sapma)
Xaort=(120+150+180+190)/4 =160 ve s=[((120-160)²+(150-160)²+(180-160)²+(190-160)²)/3]1/2
s=31,62
150 değeri için; (150-160)/31,62=-0,316
Xaort=(120+150+180+190)/4 =160 ve s=[((120-160)²+(150-160)²+(180-160)²+(190-160)²)/3]1/2
s=31,62
150 değeri için; (150-160)/31,62=-0,316
Soru 8
X=[199,211,359] değişkeninde gözlem değeri X1=199 için, ondalık ölçekleme normalleştirme yöntemi j=3 olacak şekilde dönüşümü aşağıdakilerden hangisidir?
Seçenekler
A
-0,199
B
-1,99
C
0,0199
D
0,199
E
1,99
Açıklama:
X1=199 için, ondalık ölçekleme normalleştirme yöntemi j=3 olacak şekilde dönüşümü: 199/10j =0,199 'dur.
Soru 9
Aşağıdakilerden hangisi temel değişken tiplerinden değildir?
Seçenekler
A
İkili Değişkenler
B
Sıra Gösteren Değişkenler
C
Normalleştirilmiş Değişkenler
D
İsimsel Değişkenler
E
Aralıklı Ölçümlendirilmiş Değişkenler
Açıklama:
Normalleştirilmiş değişkenler temel değişken tiplerinden değildir.
Soru 10
- Veri kalitesi probleminin farkına varılması ve doğrulanması ........... olarak adlandırılır.
- ..........., veri madenciliği tekniği ile analiz edilmek istenilen verilerdeki beklenen değerlerden sapan aykırı değerler veya hatalardır.
Seçenekler
A
A:Veri hazırlama
B:Normalleştirme
B:Normalleştirme
B
A: Veri temizleme
B: Gürültü
B: Gürültü
C
A: Veri dönüştürme
B: Eksik veri
B: Eksik veri
D
A: Veri birleştirme
B: Kirlilik
B: Kirlilik
E
A:Veri sıkıştırma
B:Tutarsızlık
B:Tutarsızlık
Açıklama:
Veri kalitesi probleminin farkına varılması ve doğrulanması veri temizleme olarak adlandırılır.
Gürültü, veri madenciliği tekniği ile analiz edilmek istenilen verilerdeki beklenen değerlerden sapan aykırı değerler veya hatalardır.
Gürültü, veri madenciliği tekniği ile analiz edilmek istenilen verilerdeki beklenen değerlerden sapan aykırı değerler veya hatalardır.
Soru 11
Birimler arasında özellik farklarının matematiksel olarak belirlendiği değişken türüne ne ad verilir?
Seçenekler
A
Tam sayılı değişken
B
Aralıklı ölçümlendirilmiş değişken
C
Sıra gösteren değişken
D
İkili değişken
E
Nominal değişken
Açıklama:
Birimler arasında özellik farklarının matematiksel olarak belirlendiği değişken türüne aralıklı ölçümlendirilmiş değişken denir. Bu nedenle doğru cevap B seçeneğidir.
Soru 12
Sıfır başlangıç noktasının tüm ölçüm araçlarında aynı anlamı taşıdığı değişken türüne ne ad verilir?
Seçenekler
A
İkili değişken
B
Sıra gösteren değişken
C
Tam sayılı değişken
D
Oranlı ölçümlendirilmiş değişken
E
Aralıklı ölçümlendirilmiş değişken
Açıklama:
Sıfır başlangıç noktasının tüm ölçüm araçlarında aynı anlamı taşıdığı değişken türüne oranlı ölçümlendirilmiş değişken denir. Bu nedenle doğru cevap D olmaktadır.
Soru 13
Bir okuldaki erkek öğretmenlerin sayısı ne tür değişkene örnek olarak verilebilir?
Seçenekler
A
Tam sayılı değişken
B
İkili değişken
C
Nominal değişken
D
Ordinal değişkeni
E
Aralıklı ölçümlendirilmiş değişken
Açıklama:
Bir ouldaki erkek öğretmenlerin sayısı tam sayılı değişkene örnek olarak verilebilir. Bu yüzden doğru cevap A seçeneğidir.
Soru 14
Aşağıdakilerden hangisi eksik verinin tahmin edilmesinde kullanılan stratejilerden birisi değildir?
Seçenekler
A
El ile doldurma
B
Genel sabitin kullanılması
C
Göz ardı etme
D
Özelliğin diğer veriler dikkate alınarak tamamlanması
E
En uygun değerin kullanılması
Açıklama:
Eksik verinin tahmin edilmesinde kullanılan stratejiler şu şekilde verilebilir:
a)Eksik verinin el ile doldurulması
b)Eksik verinin tamamlanmasında genel bir sabitin kullanılması
c)Eksik verinin özelliğin diğer veriler dikkate alınarak tamamlanması
d)Kendi sınıfında yer alan değerlerin ortalaması ile tamamlanması
e)En uygun değerin kullanılması.
a)Eksik verinin el ile doldurulması
b)Eksik verinin tamamlanmasında genel bir sabitin kullanılması
c)Eksik verinin özelliğin diğer veriler dikkate alınarak tamamlanması
d)Kendi sınıfında yer alan değerlerin ortalaması ile tamamlanması
e)En uygun değerin kullanılması.
Soru 15
Aşağıdakilerden hangisi veri indirgeme yöntemlerinden birisi değildir?
Seçenekler
A
Boyut indirgeme
B
Veri sıkıştırma
C
Büyük sayıların indirgenmesi
D
Veri küpü birleştirme
E
Normalizasyon
Açıklama:
Veri indirgeme yöntemleri şu şekilde sıralanmaktadır: veri küpü birleştirme, boyut indirgeme, veri sıkıştırma ve büyük sayıların indirgenmesi. Bu nedenle doğru cevap E seçeneğidir.
Soru 16
Aşağıdakilerden hangisi veri dönüştürme işlemlerinden birisi değildir?
Seçenekler
A
Düzeltme
B
Bir araya getirme
C
Genelleme
D
Özellik oluşturma
E
Veri küpü birleştirme
Açıklama:
Veri dönüştürme işlemleri düzeltme, bir araya getirme, genelleme, normalleştirme ve özellik oluşturma biçiminde sıralanır. Bu yüzden doğru cevap E olmaktadır.
Soru 17
Aylık temelde bulunan bir veri özelliğinin yıllık temele dönüştürülmesi işlemine ne ad verilir?
Seçenekler
A
Düzeltme
B
Genelleme
C
Normalleştirme
D
Bir araya getirme
E
Özellik oluşturma
Açıklama:
Aylık temelde bulunan bir veri özelliğinin yıllık temele dönüştürülmesi işlemi bir araya getirmeye örnektir. Bu nedenle doğru cevap D seçeneğidir.
Soru 18
Düşük düzeydeki verinin kavram hiyerarşisi kullanılarak daha yüksek seviyeye dönüştürülmesi işlemine ne ad verilir?
Seçenekler
A
Düzeltme
B
Bir araya getirme
C
Genelleme
D
Özellik oluşturma
E
Standartlaştırma
Açıklama:
Düşük düzeydeki verinin kavram hiyerarşisi kullanılarak daha yüksek seviyeye dönüştürülmesi işlemine genelleme denilir. Bu nedenle doğru cevap C olmaktadır.
Soru 19
Minimum değeri 140, maksimum değeri 350 olan bir değişkenin, 230 değerini enk-enb normalleştirme yöntemine göre dönüşüm sonucu kaçtır?
Seçenekler
A
0,43
B
0,27
C
0,15
D
-0,27
E
-0,43
Açıklama:
enk-enb normalleştirmesi şu şekilde hesaplanır:(x-enk değer)/(enb değer- enk değer)
Buna göre 230 değeri için normalleştirme sonucu bulunan değer= (230-140)/(350-140)=0,43
Bu nedenle doğru cevap A olmaktadır.
Buna göre 230 değeri için normalleştirme sonucu bulunan değer= (230-140)/(350-140)=0,43
Bu nedenle doğru cevap A olmaktadır.
Soru 20
Aşağıdakilerden hangisi R yazılımında gözlem değerlerinin aritmetik ortalamadan olan farklarının değişkene ilişkin standart sapmaya bölünmesini yapan işlevi tanımlar?
Seçenekler
A
n0
B
n1
C
n2
D
n3
E
n4
Açıklama:
R yazılımında gözlem değerlerinin aritmetik ortalamadan olan farklarının değişkene ilişkin standart sapmaya bölünmesini yapan işlev n1'dir. Bu nedenle doğru cevap B seçeneğidir.
Soru 21
Toplanan ham veri diğer bir deyişle işlenmemiş verinin veri madenciliğinde analize hazır duruma getirilmesi amacıyla yapılan işlemler bütününe aşağıdakilerden hangi ad verilir?
Seçenekler
A
Veri Derleme
B
Veri Oluşturma
C
Veri Toplama
D
Veri Hazırlama
E
Veri Depolama
Açıklama:
Toplanan ham veri diğer bir deyişle işlenmemiş verinin veri madenciliğinde analize hazır duruma getirilmesi amacıyla yapılan işlemler bütününe veri hazırlama denir.
Soru 22
Verinin hazırlanmasındaki amaç aşağıdakilerden hangisidir?
Seçenekler
A
Ham verinin yapısında bulunan ve onu değersizleştiren hataları ve sorunları ortadan kaldırmak
B
Verinin formatını veritabanı formatına uyarlamak.
C
Verinin veritabanında daha az yer kaplamasını sağlamak.
D
Verinin aranılabilirliğini ve erişilebilirliğini artırmak
E
Ham verinin içerisindeki önemli bilgileri çıkarmak
Açıklama:
Verinin hazırlanmasındaki amaç, ham verinin yapısında bulunan ve onu değersizleştiren hataları ve sorunları ortadan kaldırmaktır.
Soru 23
Aşağıdakilerden hangisi veri hazırlama işleminde yapılabilen bir işlem değildir?
Seçenekler
A
Verinin temizlenmesi
B
Verinin birleştirilmesi/bütünleştirilmesi
C
Verinin indirgenmesi
D
Verinin dönüştürülmesi(normalleştirme)
E
Verinin şeffaflaştırılması/özgünleştirilmesi
Açıklama:
Veri hazırlamada verinin temizlenmesi, birleştirilmesi/bütünleştirilmesi, indirgenmesi, dönüştürülmesi (normalleştirme) kullanılır.
Soru 24
Aşağıdakilerden hangisi veri madenciliğinde temel değişken tipleri arasında değildir?
Seçenekler
A
İsimsel(Nominal)
B
İkili(Binary)
C
Komplex (Complex)
D
Sıra Gösteren(Ordinal)
E
Tamsayılı(Integer)
Açıklama:
Veri madenciliğinde temel değişken tipleri; İsimsel (Nominal), İkili (Binary), Sıra Gösteren (Ordinal), Tamsayılı (Integer), Aralıklı Ölçümlendirilmiş (IntervalScaled), Oranlı Ölçümlendirilmiş (Ratio-Scaled) değişkenler olmak üzere gruplandırılabilir.
Soru 25
Veri madenciliği tekniği ile analiz edilmek istenilen verilerdeki beklenen değerlerden sapan aykırı değerlere veya hatalara aşağıdakilerden hangi ad verilir?
Seçenekler
A
Eksik Veri
B
Gürültü
C
Tutarsız
D
Boş veri
E
Tutarsız Veri
Açıklama:
Gürültü, veri madenciliği tekniği ile analiz edilmek istenilen verilerdeki beklenen değerlerden sapan aykırı değerler veya hatalardır.
Soru 26
Aşağıdakilerden hangisi veri indirgeme yöntemlerinden biri değildir?
Seçenekler
A
Ölçeklendirme
B
Veri küpü birleştirme
C
Boyut indirgeme
D
Veri sıkıştırma
E
Büyük sayıların indirgenmesi
Açıklama:
Veri indirgeme yöntemleri olarak veri küpü birleştirme, boyut indirgeme, veri sıkıştırma ve büyük sayıların indirgenmesi yöntemleri ortaya çıkar.
Soru 27
Aşağıdakilerden hangisi veri dönüşümünde verilerin veri madenciliği için uygun formlara dönüştürülmesi işlemleri arasında değildir?
Seçenekler
A
Özellik oluşturma
B
Sıkıştırma
C
Genelleme
D
Bir araya getirme
E
Normalleştirme
Açıklama:
Veri dönüşümünde verilerin veri madenciliği için uygun formlara dönüştürülmesi düzeltme, bir araya getirme, genelleme, normalleştirme ve özellik oluşturma işlemleriyle gerçekleştirilir.
Soru 28
Aşağıdakilerden hangisi en çok kullanılan veri dönüştürme işlemidir?
Seçenekler
A
Düzeltme
B
Bir araya getirme
C
Genelleme
D
Normalleştirme
E
Özellik oluşturma
Açıklama:
Normalleştirme veya standartlaştırma en çok kullanılan veri dönüştürme işlemidir.
Soru 29
Aşağıdakilerden hangisinde normalleştirmede kullanılan yöntemlerin hepsi verilmiştir?
Seçenekler
A
Enk-enb normalleştirme, z-skor normalleştirme
B
Sayısal ölçekleme, enk-enb normalleştirme
C
Enk-enb normalleştirme ve ondalık ölçekleme
D
Z-skor normalleştirme, sayısal ölçekleme, enk-enb normalleştirme
E
Enk-enb normalleştirme, z-skor normalleştirme ve ondalık ölçekleme
Açıklama:
Normalleştirmede enk-enb normalleştirme, z-skor normalleştirme ve ondalık ölçekleme yöntemleri kullanılır.
Soru 30
Aşağıdakilerden hangisi dönüştürme yöntemleri içinde uygulamada en çok kullanılan dönüştürme yöntemidir?
Seçenekler
A
Enk-enb normalleştirme
B
Sayısal ölçekleme
C
Z-skor normalleştirme,
D
Ondalık ölçekleme
E
Rastsal normalleştirme
Açıklama:
Z-skor normalleştirme dönüştürme yöntemleri içinde uygulamada en çok kullanılan dönüştürme yöntemidir.
Soru 31
Veri madenciliğinde işlenmemiş ham verinin yapısında bulunan ve onu değersizleştiren hataları ve sorunları ortadan kaldırarak analize hazır duruma getirilmesi amacıyla yapılan işlemler bütününe verilen isim aşağıdakilerden hangisidir?
Seçenekler
A
Veri hazırlama
B
Veri şekillendirme
C
Veri ölçekleme
D
Veri düzenleme
E
Veri işleme
Açıklama:
Toplanan ham veri diğer bir deyişle işlenmemiş verinin veri madenciliğinde analize hazır duruma getirilmesi amacıyla yapılan işlemler bütününe veri hazırlama adı verilir. Literatürde veri hazırlamayla ilgili izlenmesi gereken aşamalar araştırmacıdan araştırmacıya göre farklı isimler ve farklı sayıda aşamalar olarak verilse de sonuçta amaç hepsinde aynıdır. Verinin hazırlanmasındaki amaç ham verinin yapısında bulunan ve onu değersizleştiren hataları ve sorunları ortadan kaldırmaktır.
Bu nedenle doğru yanıt a) seçeneğidir.
Bu nedenle doğru yanıt a) seçeneğidir.
Soru 32
Bir veri setinde birimlerin sahip olduğu özelliklerin derecesinin belirlenerek sonuçların sayısal olarak ifade edilmesine ne ad verilir?
Seçenekler
A
Ölçme
B
Ölçeklendirme
C
Normalizasyon
D
Derecelendirme
E
Sayısallaştırma
Açıklama:
Hakkında bilgi edinilmek istenen canlı, cansız varlıklar veya olayların sahip oldukları ve birbirinden ayırt edilmesine yardımcı olan değişkenler veri madenciliğinde bir veri setinin sunumunda kullanılan tablo gösteriminde sütunlarda yer alır ve özellik olarak adlandırılır. Aynı tablo gösteriminde satırlarda ise nesne olarak adlandırılan gözlemler yer alır.
Birimlerin sahip olduğu özelliklerin derecesinin belirlenerek sonuçların sayısal olarak ifade edilmesine ölçme adı verilir. Diğer bir deyişle gözlem ya da deney sonucunda elde edilen verilerin nicel olarak belirtilebilmesi amacıyla ölçmeye başvurulur. Sonuç olarak ölçmede bir tanımlama söz konusudur ve ölçmenin hangi ölçek ile yapılarak değerlendirildiği önemlidir. Örnek olarak bir markette satılan ürünlerin türlerine göre sınıflanması, market çalışanlarının yönetim katından en alt çalışanına kadar sıralanması, market alışverişinde satın alınacak bir ürünün ağırlığının ölçülmesi ve çalışanların aylık performanslarına göre değerlendirilerek ölçülmesi işlemlerinin tamamında bir ölçme işlemi vardır. Bu ölçme işlemleri arasındaki fark, her birinde kullanılan ölçeklerin farklı olmasıdır. Burada ölçek kavramı ölçmeye konu olan özelliklerin sınıflanması, sıralanması, derecelenmesi ya da miktar ve derecelerinin belirlenebilmesi için uyulması gereken kurallarla kısıtlamaları belirleyen ölçme aracı olarak tanımlanır
Bu nedenle doğru yanıt a) seçeneğidir.
Birimlerin sahip olduğu özelliklerin derecesinin belirlenerek sonuçların sayısal olarak ifade edilmesine ölçme adı verilir. Diğer bir deyişle gözlem ya da deney sonucunda elde edilen verilerin nicel olarak belirtilebilmesi amacıyla ölçmeye başvurulur. Sonuç olarak ölçmede bir tanımlama söz konusudur ve ölçmenin hangi ölçek ile yapılarak değerlendirildiği önemlidir. Örnek olarak bir markette satılan ürünlerin türlerine göre sınıflanması, market çalışanlarının yönetim katından en alt çalışanına kadar sıralanması, market alışverişinde satın alınacak bir ürünün ağırlığının ölçülmesi ve çalışanların aylık performanslarına göre değerlendirilerek ölçülmesi işlemlerinin tamamında bir ölçme işlemi vardır. Bu ölçme işlemleri arasındaki fark, her birinde kullanılan ölçeklerin farklı olmasıdır. Burada ölçek kavramı ölçmeye konu olan özelliklerin sınıflanması, sıralanması, derecelenmesi ya da miktar ve derecelerinin belirlenebilmesi için uyulması gereken kurallarla kısıtlamaları belirleyen ölçme aracı olarak tanımlanır
Bu nedenle doğru yanıt a) seçeneğidir.
Soru 33
Aşağıdakilerden hangisi veri madenciliğinde kullanılan temel değişken tiplerinden biri değildir?
Seçenekler
A
Ölçümlendirilmemiş
B
Oranlı Ölçümlendirilmiş
C
Aralıklı Ölçümlendirilmiş
D
Sıra Gösteren
E
İsimsel
Açıklama:
Veri madenciliğinde temel değişken tipleri İsimsel (Nominal), İkili (Binary), Sıra Gösteren (Ordinal), Tamsayılı (Integer), Aralıklı Ölçümlendirilmiş (IntervalScaled), Oranlı Ölçümlendirilmiş (Ratio-Scaled) değişkenler olmak üzere gruplandırılabilir.
Bu nedenle doğru yanıt a) seçeneğidir.
Bu nedenle doğru yanıt a) seçeneğidir.
Soru 34
Aşağıdakilerden hangisi bir veri temizleme temel yöntemlerinden biridir?
Seçenekler
A
Gürültülü veri
B
Kirli veri
C
Aşırı veri
D
Anlamsız veri
E
Karışık veri
Açıklama:
Veri temizleme için temel yöntemler eksik veri, gürültülü veri ve tutarsızlık olmak üzere üç temel başlıkta gruplanabilir.
Bu nedenle doğru yanıt a) seçeneğidir.
Bu nedenle doğru yanıt a) seçeneğidir.
Soru 35
Farklı kaynaktan gelen verilerin eşleştirilmesi için aynı varlıkların belirlenmesi, fazla veri sorunları ve veri değer karmaşalarının belirlenmesi ve çözümlenmesi konularının ön plana çıktığı işlem aşağıdakilerden hangisidir?
Seçenekler
A
Veri birleştirme
B
Veri indirgeme
C
Veri dönüştürme
D
Veri temizleme
E
Veri sıkıştırma
Açıklama:
Veri birleştirme çoklu kaynaklardan gelen verinin uygun bir veri ambarına birleştirilmesidir. Çoklu veri kaynakları veritabanları, veri küpleri veya dış dosyalardan oluşabilir. Veri birleştirmede şema birleştirmesi, fazla veri sorunları ve veri değer karmaşalarının belirlenmesi ve çözümlenmesi olmak üzere üç temel konu ön plana çıkar. Şema birleştirme iki farklı kaynaktan gelen verilerin eşleştirilmesi için aynı varlıklar belirlenerek veriler şemalar yardımıyla birleştirilir. Şema birleştirme işleminde hataları engellemek için meta veri kullanılabilir. Veritabanları ve veri ambarlarında yer alan meta veri kavramı veri hakkında depolanan veri olarak tanımlanır. Veri birleştirmede ikinci önemli konu olan veri fazlalığı, bir varlığın özelliklerinin birden fazla kaynaktan toplanması durumunda ortaya çıkar. Bazı veri fazlalığı korelasyon analizi ile ortaya çıkarılabilir. Korelasyon analizi iki değişken arasındaki ilişkinin yönünün, büyüklüğünün ve önemini gösteren istatistiksel bir yöntemdir. Veri birleştirmede üçüncü önemli konu veri değer karmaşıklığının belirlenmesi ve çözümlenmesidir. Farklı veri kaynaklarından gelen özellik değerleri ölçekleme, birim sistemi veya gösterimdeki farklılıklar yüzünden birbirlerinden farklı olabilirler. Örneğin ağırlık özelliği farklı kaynaklarda farklı birim sistemiyle depolanmış olabilir. Veri bütünleştirme işlemlerinde verinin bu tür heterojenliği dikkate alınmalıdır.
Bu nedenle doğru yanıt a) seçeneğidir.
Bu nedenle doğru yanıt a) seçeneğidir.
Soru 36
Aşağıdakilerden hangisi veri indirgemede kullanılan yöntemlerden biri değildir?
Seçenekler
A
Ondalık ölçekleme
B
Veri küpü birleştirme
C
Boyut İndirgeme
D
Veri Sıkıştırma
E
Büyük Sayıların İndirgenmesi
Açıklama:
Veri İndirgeme
Oldukça karmaşık olan ve çok büyük veri kümelerinin madenciliğinin yapılması çok uzun zaman aldığından bu tür verilerin olduğu gibi alınarak analiz edilmesi uygulanabilir ve pratik olmamaktadır. Bu nedenle veri indirgeme yöntemleri çok daha küçük hacimde indirgenmiş veri kümelerinin oluşturulması için kullanılır. Veri indirgeme işlemi sonrası elde edilen veri seti üzerinde uygulanan madencilik sonucu verinin tamamından elde edilen sonuçtan çok farklı olmamalıdır. Veri indirgeme yöntemleri aşağıdaki bölümlerde açıklanmıştır.
Veri Küpü Birleştirme
Veri madenciliğinin veri kaynağının bir Online Analitik Süreç (OLAP:On Line Analytical Processing) sistemi olması durumunda ihtiyaç duyulan verilerin ön hesaplama ve özetlenmesi daha hızlı gerçekleştirilebilir. Veri küpleri çok boyutlu birleştirilmiş verileri saklar. Bazı durumlarda tüm verinin veri madenciliği algoritmalarında işlenmesi yerine özet bilgilerin kullanılması gerekebilir. Bu durumda OLAP küplerinin sağladığı özetleme fonksiyonlarından faydalanılabilir. Aylık satış fiyatlarının yıllık temelde daha küçük veri seti haline dönüştürülmesi örnek olarak verilebilir. Boyut İndirgeme Veri kümeleri analizle ilgisi olmayan veya gereksiz yüzlerce özellik içerebilir. Gereksiz olan özelliklerin indirgenmesi bir başka deyişle boyut indirgeme pek çok veri madenciliği algoritmasının daha verimli çalışmasını, daha anlaşılabilir bir modelin oluşturulmasını, verilerin daha kolay görselleştirilmesini ve veri madenciliği algoritmaları için gerekli olan işlemci süresi ve hafızasını azaltır.
Veri Sıkıştırma
Veri sıkıştırmada veri kodlama veya dönüşümleri asıl verinin indirgenmiş veya sıkıştırılmış gösterimini elde etmek için uygulanır. Asıl veri herhangi bir enformasyon kaybı olmaksızın sıkıştırılmış veriden tekrar elde edilebiliyorsa o zaman veri sıkıştırma işlemi “kayıpsız” (lossless) olarak nitelendirilir. Bundan başka asıl verinin gerçeğe yakın bir değeri oluşturulabilirse o zaman veri sıkıştırma kayıplı (lossy) olarak nitelendirilir. Metin verilerin sıkıştırılmasında kullanılan algoritmalar kayıpsız sıkıştırma yöntemleri olmalarına rağmen verinin sınırlı olarak işlenmesine neden olurlar. Bu nedenle daha yaygın ve etkili olan kayıplı yöntemler tercih edilir.
Büyük Sayıların İndirgenmesi
Verilerde yer alan büyük sayların daha küçük şekilleri seçilerek veri hacminin indirgenmesi için uygulanan yöntemlerdir. Veri hacmi parametrik veya parametrik olmayan yöntemler kullanılarak indirgenir. Parametrik yöntemlerde gerçek veri yerine sadece veri parametreleri saklanır ve sıkıştırılan veriyi tahmin etmek için bir model kullanılır. Parametrik olmayan veri indirgeme yöntemlerine histogramlar, kümeleme ve örnekleme gösterilebilir
Bu nedenle doğru yanıt a) seçeneğidir.
Oldukça karmaşık olan ve çok büyük veri kümelerinin madenciliğinin yapılması çok uzun zaman aldığından bu tür verilerin olduğu gibi alınarak analiz edilmesi uygulanabilir ve pratik olmamaktadır. Bu nedenle veri indirgeme yöntemleri çok daha küçük hacimde indirgenmiş veri kümelerinin oluşturulması için kullanılır. Veri indirgeme işlemi sonrası elde edilen veri seti üzerinde uygulanan madencilik sonucu verinin tamamından elde edilen sonuçtan çok farklı olmamalıdır. Veri indirgeme yöntemleri aşağıdaki bölümlerde açıklanmıştır.
Veri Küpü Birleştirme
Veri madenciliğinin veri kaynağının bir Online Analitik Süreç (OLAP:On Line Analytical Processing) sistemi olması durumunda ihtiyaç duyulan verilerin ön hesaplama ve özetlenmesi daha hızlı gerçekleştirilebilir. Veri küpleri çok boyutlu birleştirilmiş verileri saklar. Bazı durumlarda tüm verinin veri madenciliği algoritmalarında işlenmesi yerine özet bilgilerin kullanılması gerekebilir. Bu durumda OLAP küplerinin sağladığı özetleme fonksiyonlarından faydalanılabilir. Aylık satış fiyatlarının yıllık temelde daha küçük veri seti haline dönüştürülmesi örnek olarak verilebilir. Boyut İndirgeme Veri kümeleri analizle ilgisi olmayan veya gereksiz yüzlerce özellik içerebilir. Gereksiz olan özelliklerin indirgenmesi bir başka deyişle boyut indirgeme pek çok veri madenciliği algoritmasının daha verimli çalışmasını, daha anlaşılabilir bir modelin oluşturulmasını, verilerin daha kolay görselleştirilmesini ve veri madenciliği algoritmaları için gerekli olan işlemci süresi ve hafızasını azaltır.
Veri Sıkıştırma
Veri sıkıştırmada veri kodlama veya dönüşümleri asıl verinin indirgenmiş veya sıkıştırılmış gösterimini elde etmek için uygulanır. Asıl veri herhangi bir enformasyon kaybı olmaksızın sıkıştırılmış veriden tekrar elde edilebiliyorsa o zaman veri sıkıştırma işlemi “kayıpsız” (lossless) olarak nitelendirilir. Bundan başka asıl verinin gerçeğe yakın bir değeri oluşturulabilirse o zaman veri sıkıştırma kayıplı (lossy) olarak nitelendirilir. Metin verilerin sıkıştırılmasında kullanılan algoritmalar kayıpsız sıkıştırma yöntemleri olmalarına rağmen verinin sınırlı olarak işlenmesine neden olurlar. Bu nedenle daha yaygın ve etkili olan kayıplı yöntemler tercih edilir.
Büyük Sayıların İndirgenmesi
Verilerde yer alan büyük sayların daha küçük şekilleri seçilerek veri hacminin indirgenmesi için uygulanan yöntemlerdir. Veri hacmi parametrik veya parametrik olmayan yöntemler kullanılarak indirgenir. Parametrik yöntemlerde gerçek veri yerine sadece veri parametreleri saklanır ve sıkıştırılan veriyi tahmin etmek için bir model kullanılır. Parametrik olmayan veri indirgeme yöntemlerine histogramlar, kümeleme ve örnekleme gösterilebilir
Bu nedenle doğru yanıt a) seçeneğidir.
Soru 37
Aşağıdakilerden hangisi bir veri dönüştürme işlemi değildir?
Seçenekler
A
Ölçek oluşturma
B
Düzeltme
C
Bir araya getirme
D
Genelleme
E
Normalleştirme
Açıklama:
Bazı durumlarda orijinal veri kümelerindeki özellikler gerekli enformasyonu içerdiği halde veri madenciliği algoritmaları için uygun yapıda olmayabilirler. Bu durumda orijinal özelliklerinden oluşturulan bir veya daha fazla yeni özellik orijinal özelliklerden daha faydalı olabilir. Veri dönüşümünde verilerin veri madenciliği için uygun formlara dönüştürülmesi düzeltme, bir araya getirme, genelleme, normalleştirme ve özellik oluşturma işlemleriyle gerçekleştirilir.
Bu nedenle doğru yanıt a) seçeneğidir.
Bu nedenle doğru yanıt a) seçeneğidir.
Soru 38
Bölmeleme, kümeleme ve regresyon gibi teknikler kullanılarak verilerdeki gürültünün temizlenmesi süreci aşağıdaki veri dönüştürme işlemlerinden hangisine aittir?
Seçenekler
A
Düzeltme
B
Bir araya getirme
C
Genelleme
D
Normalleştirme
E
Özellik oluşturma
Açıklama:
Bazı durumlarda orijinal veri kümelerindeki özellikler gerekli enformasyonu içerdiği halde veri madenciliği algoritmaları için uygun yapıda olmayabilirler. Bu durumda orijinal özelliklerinden oluşturulan bir veya daha fazla yeni özellik orijinal özelliklerden daha faydalı olabilir. Veri dönüşümünde verilerin veri madenciliği için uygun formlara dönüştürülmesi düzeltme, bir araya getirme, genelleme, normalleştirme ve özellik oluşturma işlemleriyle gerçekleştirilir.
- Düzeltme; bölmeleme, kümeleme ve regresyon gibi teknikler kullanılarak verilerdeki gürültünün temizlenmesidir.
- Bir araya getirme; veriler bir araya getiren gruplama fonksiyonları kullanılarak gerçekleştirilir. Günlük temelde bulunan bir veri özelliğinin aylık temele dönüştürülmesi örnek verilebilir.
- Genelleme; düşük düzeydeki verinin kavram hiyerarşisi kullanılarak daha yüksek seviyeye dönüştürülmesidir. Örneğin; yaş gibi sayısal verilerin kategorik olan genç, orta yaşlı veya yaşlı gibi değerlere dönüştürülmesi ya da cadde isimlerinden oluşan kategorik verilerin şehir veya ülke şeklinde daha yüksek kavramlara dönüştürülmesidir.
- Normalleştirme veya standartlaştırma; bir değişkenin standartlaştırılması veya normalleştirilmesi yaygın olarak kullanılan veri dönüşüm tekniğidir. Veri madenciliği terminolojisinde her iki terim birbiri yerine kullanılmaktadır. Ancak buradaki normalleştirme terimi, istatistikte kullanılan bir değişkenin normal dağılmış bir değişkene dönüştürülmesi ile karıştırılmamalıdır. Standartlaştırma veya normalleştirmenin amacı sayısal veri değerlerinin küçük bir bölgede yer alması için ölçeklenmesidir. Normalleştirilmiş veriler sınıflama için kullanılan yapay sinir ağları algoritmalarının öğrenme aşamasının hızlanmasına yardım edecektir. Kümeleme gibi mesafe ölçümlerine dayalı algoritmalarda normalleştirilmiş verilerin kullanılması faydalı olacaktır.
- Özellik oluşturma; yeni özellikler madencilik sürecine yardımcı olmak için verilen özellikler kümesinden oluşturulur ve düzenlenir. Özellik oluşturma karar ağacı algoritmaları sınıflama için kullanıldığında bölümleme problemini azaltmaya yardımcı olabilir. Yükseklik ve genişlik özelliklerinden alan özelliğinin oluşturulması bu duruma bir örnek olarak verilebilir
Soru 39
X* : Dönüştürülmüş değeri, X: Gözlem değerini, Xenk: Verideki en küçük gözlem değeri ve Xenb: Verideki en büyük değeri ifade ettiğine göre Enk-Enb Normalleştirme dönüşümü için aşağıdaki formüllerden hangisi kullanılır?
Seçenekler
A
X - Xenk
X*= -----------------
Xenb - Xenk
X*= -----------------
Xenb - Xenk
B
X - Xenk
X*= -----------------
Xenk - Xenb
X*= -----------------
Xenk - Xenb
C
X - Xenb
X*= -----------------
Xenb - Xenk
X*= -----------------
Xenb - Xenk
D
Xenk - X
X*= -----------------
Xenb - Xenk
X*= -----------------
Xenb - Xenk
E
Xenb - X
X*= -----------------
Xenb - Xenk
X*= -----------------
Xenb - Xenk
Açıklama:
Orijinal veri üzerinde doğrusal bir dönüşüm yapan bu yöntem veri içindeki en büyük ve en küçük sayısal değerin belirlenerek diğer değerleri buna uygun bir şekilde dönüştürülmesiyle yapılır. Enk-Enb normalleştirme sonucunda veri sıfır (en küçük değer) ile bir (en büyük değer) arasında sayısal bir değere dönüşür. Dönüştürme için aşağıdaki eşitlikten yararlanılır.
X - Xenk
X*= -----------------
Xenb - Xenk
Bu eşitlikte; X* : Dönüştürülmüş değeri X: Gözlem değerini Xenk: Verideki en küçük gözlem değeri Xenb: Verideki en büyük değeri ifade eder.
Bu nedenle doğru yanıt a) seçeneğidir.
X - Xenk
X*= -----------------
Xenb - Xenk
Bu eşitlikte; X* : Dönüştürülmüş değeri X: Gözlem değerini Xenk: Verideki en küçük gözlem değeri Xenb: Verideki en büyük değeri ifade eder.
Bu nedenle doğru yanıt a) seçeneğidir.
Soru 40
X = {251, 148, 166, 244, 472, 356, 379} kümesi verilsin. Enk-Enb Normalleştirme dönüşümü uygulandığında 472 değerinin dönüşmüş biçimi aşağıdakilerden hangisidir?
Seçenekler
A
1
B
0
C
0,056
D
0,296
E
0,318
Açıklama:
X = {251, 148, 166, 244, 472, 356, 379} kümesinde 472 değerini dönüştürmek için Enk-Enb Normalleştirme dönüşümünün aşağıdaki formülü uygulandığında;
X - Xenk 472 - 148
X*= ----------------- = ------------ = 1
Xenb - Xenk 472 - 148
Elde edilir. Bu nedenle doğru yanıt A seçeneğidir.
X - Xenk 472 - 148
X*= ----------------- = ------------ = 1
Xenb - Xenk 472 - 148
Elde edilir. Bu nedenle doğru yanıt A seçeneğidir.
Soru 41
Cinsiyet değişkeni için seçeneklerde yer alan hangi değişken tipi doğrudur?
Seçenekler
A
İsimsel değişken
B
Sıra gösteren değişken
C
Oransal değişken
D
Eksik değişken
E
Aralıklı değişken
Açıklama:
Sınıflayıcı ölçek, gözlem değerlerinin tek tek nitel kategori ya da sınıflara atanması so- nucu oluşan ölçektir. Daha önce verilen bir markette satılan ürünlerin türlerine göre sınıflanması örneğinde sınıflayıcı ölçek kullanılır. Cinsiyet sınıflaması veya hastaneye başvuran hastaların rahatsızlıklarına göre sınıflandırılması sınıflayıcı ölçeğe örnek ola- rak verilebilir.
Soru 42
Birimlerin sahip olduğu özelliklerin derecesinin belirlenerek sonuçların sayısal olarak ifade edilmesine ne adı verilir?
Seçenekler
A
Ölçek
B
Ölçen
C
Veri
D
Ölçme
E
Ortalama
Açıklama:
Birimlerin sahip olduğu özelliklerin derecesinin belirlenerek sonuçların sayısal olarak ifade edilmesine ölçme adı verilir.
Soru 43
Seçeneklerden hangisi eksik verinin tahmin edilmesi için kullanılan başlıca stratejilerden değildir?
Seçenekler
A
El ile doldurma
B
Genel sabit kullanma
C
Özellik ve diğer veri uyumu ile doldurma
D
Ortalama ile tamamlama
E
Hipotez testi ile sonuç oluşturma
Açıklama:
Eksik verinin tahmin edilmesi için kullanılan başlıca stratejiler aşağıda verilmiştir.
- Eksik verinin el ile doldurulması; bu strateji zaman alıcıdır ve eksik verinin fazla
olduğu büyük veri kümelerinde kullanılması uygun değildir. - Eksik verinin tamamlanmasında genel bir sabitin kullanılması; tüm eksik verinin belirlenecek bir sabit değer ile değiştirilmesidir. Bu değişiklik uygulandığında veri madenciliği algoritmalarını olumsuz etkileyebilir. Bu nedenle basit bir strateji olmasına rağmen tercih edilmez.
- Eksik verinin verinin özelliğin diğer veriler dikkate alınarak tamamlanması; bu stratejide eksik veri, aynı özelliğin eksik olmayan kayıtları göz önüne alınarak ortalama, medyan, mod gibi verinin tamamını temsil eden tek bir değer ile değiştirilir.
- Eksik verinin kendi sınıfında yer alan değerlerin ortalaması ile tamamlanması; eksik verinin tamamlanması öncesinde veri üzerinde bir sınıflama çalışması yapılarak eksik verinin ait olduğu sınıflar belirlenir. Her eksik verinin bulunduğu sınıf eksik olmayan özellik verilerinin ortalaması ile tamamlanır.
- Eksik verinin tamamlanmasında en uygun değerin kullanılması; eksik verinin bulunduğu özelliğin en uygun değeri regresyon yönteminin kullanıldığı sonuç çıkarmaya dayalı araçlar veya karar ağaçları kullanılarak belirlenebilir. Diğer stra- tejilere kıyasla bu strateji eksik veriyi tahmin etmede mevcut enformasyondan en fazla faydalanan yöntemdir. Bu nedenle en sık kullanılan stratejidir.
Soru 44
Ölçülen bir değerdeki hata veya hatalı veri toplama, veri girişi problemleri, teknolojik kısıtlar gibi yanlış nitelik değerleri ne tür verinin olası nedenleridir?
Seçenekler
A
Sıralayıcı verinin
B
İkili verinin
C
Gürültülü verinin
D
Bağlamsal verinin
E
Görsel verinin
Açıklama:
Ölçülen bir değerdeki hata veya hatalı veri toplama, veri girişi problemleri, teknolojik kısıtlar gibi yanlış nitelik değerleri gürültülü verinin olası nedenleridir.
Soru 45
Bölmeleme yöntemlerinde öncelikle veriler __________ sıralanır.
Seçenekler
A
artan sırada
B
kümelere göre
C
renge göre
D
şekile göre
E
bölgeye göre
Açıklama:
Bölmeleme yöntemlerinde öncelikle veriler artan sırada sıralanır.
Soru 46
Aykırı değerler ___________ analizi ile ortaya çıkarılabilir?
Seçenekler
A
ortalama
B
kümeleme
C
toplama
D
bölme
E
varyans
Açıklama:
Aykırı değerler kümeleme analizi ile ortaya çıkarılabilir.
Soru 47
___________ iki farklı kaynaktan gelen verilerin eşleştirilmesi için aynı varlıklar belirlenerek veriler __________ yardımıyla birleştirilir?
Seçenekler
A
OLAP ; gözlemler ile
B
Eksik bulma; varyanslar ile
C
Eksik tamamlamam; rassal gözlemlerle
D
Toplam birleştirme; ortalamalarla
E
Şema birleştirme; şemalar
Açıklama:
Şema birleştirme iki farklı kaynaktan gelen verilerin eşleştirilmesi için aynı varlıklar belirlenerek veriler şemalar yardımıyla birleştirilir.
Soru 48
Bir değişken için 20 adet gözlem elde edilmiştir. Bu değişkene ait en büyük değer 25 ve en küçük değer 5 olarak bulunmuştur. herhangi bir gözlemin değeri 10 a eşit ise enk-enb normalleştirmesine göre bu gözlem değerinin normalleştirilmiş değeri ne olur?
Seçenekler
A
0.15
B
0.20
C
0.25
D
0.30
E
0.50
Açıklama:
X(norm)= (10-5)/(25-5)=0.25 olur
Soru 49
Bir değişkenin ortalaması 10 standart sapması 4 ise 12 değerine sahip bir gözlem birimi için z-skor değeri nedir?
Seçenekler
A
0.05
B
0.20
C
0.35
D
0.50
E
0.80
Açıklama:
X(zskor)= (12-10)/4=2/4=0.50
Soru 50
İşlenmemiş verinin, analize hazır duruma getirilmesi amacıyla yapılan tüm işlemlere ne ad verilir?
Seçenekler
A
Veri Hazırlama
B
Veri Dönüştürme
C
Veri Analizi
D
Veri Temizleme
E
Veri Manipülasyonu
Açıklama:
Söz konusu amaçla yapılan bir çok işlem, bir bütün olarak veri hazırlama adını alır.
Soru 51
Bir sınıftaki öğrenciler, kızlar ve erkekler olarak cinsiyetlerine göre iki gruba ayrılmıştır. Söz konusu durumda cinsiyet, ne tür bir değişkendir?
Seçenekler
A
Ordinal
B
Nominal
C
Aralıklı Ölçümlendirilmiş
D
Sürekli
E
Bağımlı
Açıklama:
Cinsiyet, kategorik-nominal bir değişken türüdür.
Soru 52
Bir okul yöneticisi, öğrencilerin kişisel bilgilerine yönelik oluşturduğu veri tabanına kardeş sayılarını da kaydetmiştir. Kardeş sayısı, hangi tür değişkendir?
Seçenekler
A
Aralıklı
B
Eşit oranlı
C
Kesikli değişken
D
Binary
E
Sınıflayıcı
Açıklama:
Sınıf düzeyi tam sayılar alabileceğinden, integer bir değişken türüdür. Sayma sayıları biçimde sonuçlar ortaya çıkacağı için kesikli bir değişken olacaktır.
Soru 53
Eksik verinin tamamlanması sürecinde çok zaman alan ve eksik verinin çok olması durumunda veri setinde yanlılığa neden olabilecek yöntem nedir?
Seçenekler
A
El ile doldurma
B
Ortalama değer atama
C
Regresyon
D
Diğer verilere göre atama
E
Silme
Açıklama:
Veri setinde eksik verilerin el ile doldurulması, eğer veri setinde çok fazla kayıp veri var ise hemen çok zaman alıcı olacaktır, hem de yanlılığa, yanlış sonuçlara ulaşılmasına neden olabilecektir.
Soru 54
Aykırı - aşırı uç değerlerin veri setinde yer alması, veri temizleme işlemini gerektiren hangi durumla ilgilidir?
Seçenekler
A
Kayıp
B
Tutarsız
C
Eksik
D
Gürültü
E
Sıkıştırma
Açıklama:
Veri setinde analiz sonuçlarını etkileyebilecek aykırı değerlerin olması, "gürültü" olarak adlandırılır.
Soru 55
Bir çok farklı kaynaktan gelen verinin, bir arada kullanılmak amacıyla bir yerde toplanmasına ne ad verilir?
Seçenekler
A
İndirgeme
B
Sıkıştırma
C
Bölme
D
Dönüştürme
E
Birleştirme
Açıklama:
Veri birleştirme işlemiyle farklı yerlerde olan veri setleri bir araya getirilerek, aynı amaçla kullanılmaya hazır hale getirilmiş olur.
Soru 56
Kümeleme, veri dönüştürmede kullanılan hangi işleme yönelik tekniklerden biridir?
Seçenekler
A
Düzeltme
B
Bir araya getirme
C
Normalleştirme
D
Özellik oluşturma
E
Ölçekleme
Açıklama:
Kümeleme, düzeltme işlemlerinde kullanılan bir metottur.
Soru 57
Verilerin, veri kümesinde yer alan minimum ve maksimum değerlere göre normalleştirilmesine ne ad verilir?
Seçenekler
A
Z-Skor
B
Ondalık Ölçekleme
C
Enk-Enb
D
Standart Sapma
E
Aritmetik Ortalama
Açıklama:
Veri setindeki en büyük ve en küçük sayılara dayalı olarak kullanılan yöntem ENK-ENB yöntemidir.
Soru 58
Normalleştirme işleminde ilgili değişkenin standart sapması ve aritmetik ortalamasına dayalı işleme ne ad verilir?
Seçenekler
A
Z-Skor
B
Enk-Enb
C
Ondalık Ölçekleme
D
Ranj
E
Sınıflama
Açıklama:
Değişkenlerin -3, +3 aralığındaki değerlere doğrusal dönüşüm işlemi, standart sapma ve artimetik ortalama ile yapılan Z-skor işlemidir.
Soru 59
Aşağıdakilerden hangisinin verinin uygun formlara dönüştürülmesinde yapılan işlemlerden biri değildir?
Seçenekler
A
Düzeltme
B
Bir araya getirme
C
Genelleme
D
Sıkıştırma
E
Normalleştirme
Açıklama:
Sıkıştırma, veri indirgeme yöntemlerinden biridir.
Soru 60
Veri madenciliğinde bir veri kavramı ile ilgili seçeneklerden hangisi söylenebilir?
Seçenekler
A
Sabit bir yapısı ya da boyutu yoktur?
B
Hataya müsaade etmez.
C
Kaynak çeşitliliği yoktur.
D
Değişime kapalıdır.
E
En önemli veri kaynağı insandır.
Açıklama:
Veri madeninde bulunan veri insan tarafından oluşturulmuş bir bilgisayar dosyasından, verileri tasarlamak ve yönetmek için kullanılan bir işletme veri tabanı yönetim sisteminden, standart bir veri tabanı sisteminden, otomatik bilgi kaydı oluşturan bir araçtan, uydu üzerinden ve bunlara benzer şekilde kaynaklardan gelmiş olabilir. Farklı kaynaklardan gelen veri geliş kaynağının özelliğine göre çok çeşitli yapılarda, şekillerde ve tiplerde bulunabilir. Bu yapıdaki veri büyük olmasının yanı sıra çeşitli hatalar, kayıp değerler veya aykırı değerler içeriyor olabilir. Bir madenden çıkarılmayı bekleyen değerli taşlar gibi bu veri de çeşitli analizlerde kullanılmak üzere veritabanında bekler.
Soru 61
Değişkenin sayı ile ifade edilebildiği ancak bu sayının aritmetik olarak bir anlam ifade etmediği değişken türü hangisidir?
Seçenekler
A
İkili değişkenler
B
Sıra gösteren değişkenler
C
İsimsel değişkenler
D
Tam sayılı değişkenler
E
Aralıklı ölçümlendirilmiş değişkenler
Açıklama:
İsimsel (Nominal) Değişkenler
Sınıflayıcı ölçek, gözlem değerlerinin tek tek nitel kategori ya da sınıflara atanması sonucu oluşan ölçektir. Daha önce verilen bir markette satılan ürünlerin türlerine göre
sınıflanması örneğinde sınıflayıcı ölçek kullanılır. Cinsiyet sınıflaması veya hastaneye
başvuran hastaların rahatsızlıklarına göre sınıflandırılması sınıflayıcı ölçeğe örnek olarak verilebilir.
İsimsel değişken sayısal bir formda olabilir. Ancak bu sayısal değer matematiksel bir
hesaplama ya da işlem yapmak için uygun değildir. Örneğin; 5 kişi 1, 2, 3, 4, 5 olarak
sayılarla ifade edilebilir. Buradaki sayılar üzerinde aritmetik bir işlem yapmak anlamlı
olmayacaktır. Örnekteki sayılar sadece bir etiket görevi görecektir.
Sınıflayıcı ölçek, gözlem değerlerinin tek tek nitel kategori ya da sınıflara atanması sonucu oluşan ölçektir. Daha önce verilen bir markette satılan ürünlerin türlerine göre
sınıflanması örneğinde sınıflayıcı ölçek kullanılır. Cinsiyet sınıflaması veya hastaneye
başvuran hastaların rahatsızlıklarına göre sınıflandırılması sınıflayıcı ölçeğe örnek olarak verilebilir.
İsimsel değişken sayısal bir formda olabilir. Ancak bu sayısal değer matematiksel bir
hesaplama ya da işlem yapmak için uygun değildir. Örneğin; 5 kişi 1, 2, 3, 4, 5 olarak
sayılarla ifade edilebilir. Buradaki sayılar üzerinde aritmetik bir işlem yapmak anlamlı
olmayacaktır. Örnekteki sayılar sadece bir etiket görevi görecektir.
Soru 62
Seçeneklerde verilen değişken tiplerinden hangisi diğerlerinin bütün özelliklerini taşımaktadır?
Seçenekler
A
Sıra gösteren değişkenler
B
Tam sayılı değişkenler
C
Aralıkl ölçümlendirilmiş değişkenler
D
İkili değişkenler
E
Oranlı ölçümlendirilmiş değişkenler
Açıklama:
Oranlı ölçümlendirilmiş (ratio-scaled) değişkenler aralıklı ölçümlendirilmiş (interval-scaled) değişkenlere benzer olmakla beraber bu değişkende sıfır başlangıç noktası tüm ölçüm
araçlarında aynı anlamı taşır. Örneğin; bir varlığın ağırlığı için “sıfır” ifadesi kullanıldığında ölçüm metrik türüne bakılmadan bu varlığın ağırlığının olmadığı anlamı çıkarılır.
Diğer bir deyişle sıfır kilogram ve sıfır gram aynı anlamı taşır. Oranlı ölçümlendirilmiş
(ratio-scaled) değişkenler daha önce ele alınan değişken tiplerinin tüm özelliklerini içerir.
En büyük özelliği yokluk anlamına gelen belirli bir sıfır değerini barındırıyor olması bu nedenle ölçme düzeyleri arasında oransal analizler yapılabilmesine olanak tanıyor olmasıdır.
araçlarında aynı anlamı taşır. Örneğin; bir varlığın ağırlığı için “sıfır” ifadesi kullanıldığında ölçüm metrik türüne bakılmadan bu varlığın ağırlığının olmadığı anlamı çıkarılır.
Diğer bir deyişle sıfır kilogram ve sıfır gram aynı anlamı taşır. Oranlı ölçümlendirilmiş
(ratio-scaled) değişkenler daha önce ele alınan değişken tiplerinin tüm özelliklerini içerir.
En büyük özelliği yokluk anlamına gelen belirli bir sıfır değerini barındırıyor olması bu nedenle ölçme düzeyleri arasında oransal analizler yapılabilmesine olanak tanıyor olmasıdır.
Soru 63
Veri hazırlama sürecinin ilk aşaması seçeneklerden hangisinde verilmiştir?
Seçenekler
A
Veri toplama
B
Veri temizleme
C
Veri dönüşürme
D
Veri birleştirme
E
Veri indirgeme
Açıklama:
.
Veri hazırlama süreçlerinden biri olan veri temizleme verideki tutarsızlıkların giderilmesi ve verideki gürültünün giderilmesi için uygulanır. Veri dönüştürme olarak normalleştirme kullanılabilir. Veri birleştirme farklı kaynaktan gelen veriyi uygun bir veri tabanında birleştirir. Veri indirgeme ise fazla olan bazı değişkenlerin çıkarılması, birleştirilmesi veya kümeleme yaparak veri büyüklüğünün azaltılması amaçlanır. Veri yapısına uygun olacak şekilde bu süreçlerden biri veya birkaçı veri madenciliğinden önce uygulanarak elde edilen sonuçların kalitesi, güvenilirliği ve veri madenciliği aşamasında harcanacak zaman arttırılabilir.
Veri hazırlama süreçlerinden biri olan veri temizleme verideki tutarsızlıkların giderilmesi ve verideki gürültünün giderilmesi için uygulanır. Veri dönüştürme olarak normalleştirme kullanılabilir. Veri birleştirme farklı kaynaktan gelen veriyi uygun bir veri tabanında birleştirir. Veri indirgeme ise fazla olan bazı değişkenlerin çıkarılması, birleştirilmesi veya kümeleme yaparak veri büyüklüğünün azaltılması amaçlanır. Veri yapısına uygun olacak şekilde bu süreçlerden biri veya birkaçı veri madenciliğinden önce uygulanarak elde edilen sonuçların kalitesi, güvenilirliği ve veri madenciliği aşamasında harcanacak zaman arttırılabilir.
Soru 64
Seçeneklerden hangisi eksik verinin tahmin edilmesinde kullanılan stratjilerden biri değildir?
Seçenekler
A
Eksik verinin kendi sınıfında yer alan değerlerin ortalaması ile tamamlanması
B
Eksik verinin verinin özelliğin diğer veriler dikkate alınarak tamamlanması
C
Eksik verinin tamamlanmasında genel bir sabitin kullanılması
D
Eksik verinin gözardı edilmesi
E
Eksik verinin el ile doldurulması
Açıklama:
Eksik verinin tahmin edilmesi için kullanılan başlıca stratejiler aşağıda verilmiştir.
• Eksik verinin el ile doldurulması; bu strateji zaman alıcıdır ve eksik verinin fazla
olduğu büyük veri kümelerinde kullanılması uygun değildir.
• Eksik verinin tamamlanmasında genel bir sabitin kullanılması; tüm eksik verinin
belirlenecek bir sabit değer ile değiştirilmesidir. Bu değişiklik uygulandığında veri
madenciliği algoritmalarını olumsuz etkileyebilir. Bu nedenle basit bir strateji olmasına rağmen tercih edilmez.
• Eksik verinin verinin özelliğin diğer veriler dikkate alınarak tamamlanması; bu
stratejide eksik veri, aynı özelliğin eksik olmayan kayıtları göz önüne alınarak ortalama, medyan, mod gibi verinin tamamını temsil eden tek bir değer ile değiştirilir.
• Eksik verinin kendi sınıfında yer alan değerlerin ortalaması ile tamamlanması; eksik verinin tamamlanması öncesinde veri üzerinde bir sınıflama çalışması yapılarak eksik verinin ait olduğu sınıflar belirlenir. Her eksik verinin bulunduğu sınıf
eksik olmayan özellik verilerinin ortalaması ile tamamlanır.
• Eksik verinin tamamlanmasında en uygun değerin kullanılması; eksik verinin
bulunduğu özelliğin en uygun değeri regresyon yönteminin kullanıldığı sonuç
çıkarmaya dayalı araçlar veya karar ağaçları kullanılarak belirlenebilir. Diğer stratejilere kıyasla bu strateji eksik veriyi tahmin etmede mevcut enformasyondan en
fazla faydalanan yöntemdir. Bu nedenle en sık kullanılan stratejidir.
• Eksik verinin el ile doldurulması; bu strateji zaman alıcıdır ve eksik verinin fazla
olduğu büyük veri kümelerinde kullanılması uygun değildir.
• Eksik verinin tamamlanmasında genel bir sabitin kullanılması; tüm eksik verinin
belirlenecek bir sabit değer ile değiştirilmesidir. Bu değişiklik uygulandığında veri
madenciliği algoritmalarını olumsuz etkileyebilir. Bu nedenle basit bir strateji olmasına rağmen tercih edilmez.
• Eksik verinin verinin özelliğin diğer veriler dikkate alınarak tamamlanması; bu
stratejide eksik veri, aynı özelliğin eksik olmayan kayıtları göz önüne alınarak ortalama, medyan, mod gibi verinin tamamını temsil eden tek bir değer ile değiştirilir.
• Eksik verinin kendi sınıfında yer alan değerlerin ortalaması ile tamamlanması; eksik verinin tamamlanması öncesinde veri üzerinde bir sınıflama çalışması yapılarak eksik verinin ait olduğu sınıflar belirlenir. Her eksik verinin bulunduğu sınıf
eksik olmayan özellik verilerinin ortalaması ile tamamlanır.
• Eksik verinin tamamlanmasında en uygun değerin kullanılması; eksik verinin
bulunduğu özelliğin en uygun değeri regresyon yönteminin kullanıldığı sonuç
çıkarmaya dayalı araçlar veya karar ağaçları kullanılarak belirlenebilir. Diğer stratejilere kıyasla bu strateji eksik veriyi tahmin etmede mevcut enformasyondan en
fazla faydalanan yöntemdir. Bu nedenle en sık kullanılan stratejidir.
Soru 65
Verideki gürültünün belirlenip giderilebilmesi için seçeneklerdeki yöntemlerden hangiis kullanılabilir?
Seçenekler
A
Kümeleme
B
Göz ardı etme
C
Veri eksiltme
D
Aritmetik ortalama alma
E
Standart sapma uygulama
Açıklama:
Gürültü, veri madenciliği tekniği ile analiz edilmek istenilen verilerdeki beklenen
değerlerden sapan aykırı değerler veya hatalardır. Gürültülü veri büyük veritabanları ve
veri ambarlarında karşılaşılan yaygın problemlerdendir. Ölçülen bir değerdeki hata veya
hatalı veri toplama, veri girişi problemleri, teknolojik kısıtlar gibi yanlış nitelik değerleri
gürültülü verinin olası nedenleridir. Veri madenciliği uygulanmadan önce bu değerlerin
neden olduğu gürültü düzeltilmelidir. Verideki gürültünün belirlenip giderilmesi için
bölmeleme, kümeleme, bilgisayar ve insan denetiminin birleştirilmesi ve regresyon
yöntemleri kullanılabilir.
değerlerden sapan aykırı değerler veya hatalardır. Gürültülü veri büyük veritabanları ve
veri ambarlarında karşılaşılan yaygın problemlerdendir. Ölçülen bir değerdeki hata veya
hatalı veri toplama, veri girişi problemleri, teknolojik kısıtlar gibi yanlış nitelik değerleri
gürültülü verinin olası nedenleridir. Veri madenciliği uygulanmadan önce bu değerlerin
neden olduğu gürültü düzeltilmelidir. Verideki gürültünün belirlenip giderilmesi için
bölmeleme, kümeleme, bilgisayar ve insan denetiminin birleştirilmesi ve regresyon
yöntemleri kullanılabilir.
Soru 66
Veri kümesi içerisindeki gereksiz özelliklerin çıkarılmasına ne ad verilmektedir?
Seçenekler
A
Veri birleştirme
B
Veri küpü
C
Boyut indirgeme
D
Veri sıkıştırma
E
Veri dönüştürme
Açıklama:
Veri kümeleri analizle ilgisi olmayan veya gereksiz yüzlerce özellik içerebilir. Gereksiz
olan özelliklerin indirgenmesi bir başka deyişle boyut indirgeme pek çok veri madenciliği
algoritmasının daha verimli çalışmasını, daha anlaşılabilir bir modelin oluşturulmasını,
verilerin daha kolay görselleştirilmesini ve veri madenciliği algoritmaları için gerekli
olan işlemci süresi ve hafızasını azaltır. İyi bir özellik alt kümesi asıl özelliklerden seçilir.
olan özelliklerin indirgenmesi bir başka deyişle boyut indirgeme pek çok veri madenciliği
algoritmasının daha verimli çalışmasını, daha anlaşılabilir bir modelin oluşturulmasını,
verilerin daha kolay görselleştirilmesini ve veri madenciliği algoritmaları için gerekli
olan işlemci süresi ve hafızasını azaltır. İyi bir özellik alt kümesi asıl özelliklerden seçilir.
Soru 67
Veri dönüştürmede düşük düzeydeki verinin kavram hiyerarşisi kullanılarak daha yüksek
seviyeye dönüştürülmesine ne ad verilmektedir?
seviyeye dönüştürülmesine ne ad verilmektedir?
Seçenekler
A
Düzeltme
B
Genelleme
C
Bir araya getirme
D
Normalleştirme
E
Özellik oluşturma
Açıklama:
Genelleme; düşük düzeydeki verinin kavram hiyerarşisi kullanılarak daha yüksek
seviyeye dönüştürülmesidir. Örneğin; yaş gibi sayısal verilerin kategorik olan
genç, orta yaşlı veya yaşlı gibi değerlere dönüştürülmesi ya da cadde isimlerinden oluşan kategorik verilerin şehir veya ülke şeklinde daha yüksek kavramlara
dönüştürülmesidir
seviyeye dönüştürülmesidir. Örneğin; yaş gibi sayısal verilerin kategorik olan
genç, orta yaşlı veya yaşlı gibi değerlere dönüştürülmesi ya da cadde isimlerinden oluşan kategorik verilerin şehir veya ülke şeklinde daha yüksek kavramlara
dönüştürülmesidir
Soru 68
En çok kullanılan veri dönüştürme işlemi hangisidir?
Seçenekler
A
Özellik oluşturma
B
Genelleme
C
Düzeltme
D
Bir araya getirme
E
Normalleştirme
Açıklama:
Normalleştirme veya standartlaştırma en çok kullanılan veri dönüştürme işlemidir.
Normalleştirmede enk-enb normalleştirme, z skor normalleştirme ve ondalık ölçekleme
yöntemleri kullanılır.
Normalleştirmede enk-enb normalleştirme, z skor normalleştirme ve ondalık ölçekleme
yöntemleri kullanılır.
Soru 69
Seçeneklerden hangisi z-skor normalleştirmenin bir özelliğidir?
Seçenekler
A
En büyük ve en küçük değerlerin belirlenmesi
B
Standart sapmanın kullanılması
C
Ortancanın kullanılması
D
Eşitsizliklerin temel alınması
E
Eksi değerlerin işleme alınması
Açıklama:
z-skor normalleştirme diğer dönüştürme yöntemleri içinde uygulamada en çok kullanılan dönüştürme yöntemidir. Bir değişkene (özellik) ilişkin aritmetik ortalama ve standart
sapma hesaplamasından sonra elde edilir. z-skor normalleştirme sonucunda veri sıfır ile
bir arasında sayısal bir değere dönüşür. Dönüştürme için aşağıdaki eşitlikten yararlanılır.
sapma hesaplamasından sonra elde edilir. z-skor normalleştirme sonucunda veri sıfır ile
bir arasında sayısal bir değere dönüşür. Dönüştürme için aşağıdaki eşitlikten yararlanılır.
Soru 70
"..................., hakkında bilgi edinilmek istenen canlı, cansız varlıklar veya olayların sahip oldukları ve birbirinden ayırt edilmesine yardımcı olan değişkenler veri madenciliğinde bir veri setinin sunumunda kullanılan tablo
gösteriminde sütunlarda yer alır."
gösteriminde sütunlarda yer alır."
Seçenekler
A
Deney
B
Analiz
C
Özellik
D
Ölçme
E
Nesne
Açıklama:
Özellik, hakkında bilgi edinilmek istenen canlı, cansız varlıklar veya olayların sahip oldukları ve birbirinden ayırt edilmesine yardımcı olan değişkenler veri madenciliğinde bir veri setinin sunumunda kullanılan tablo
gösteriminde sütunlarda yer alır.
gösteriminde sütunlarda yer alır.
Soru 71
"Birimlerin sahip olduğu özelliklerin derecesinin belirlenerek sonuçların sayısal olarak ifade edilmesine .................. adı verilir. Diğer bir deyişle gözlem ya da deney sonucunda elde edilen verilerin nicel olarak belirtilebilmesidir."
Metinde boş bırakılan yere aşağıdaki seçeneklerden hangisi getirilmelidir?
Metinde boş bırakılan yere aşağıdaki seçeneklerden hangisi getirilmelidir?
Seçenekler
A
ölçme
B
veri
C
nesne
D
özellik
E
değişken
Açıklama:
Birimlerin sahip olduğu özelliklerin derecesinin belirlenerek sonuçların sayısal olarak ifade edilmesine ölçme adı verilir. Diğer bir deyişle gözlem ya da deney sonucunda elde edilen verilerin nicel olarak belirtilebilmesi amacıyla ölçmeye başvurulur
Soru 72
Bir nesnenin özelliklerinin ölçme şekline göre bir çok değişken tipi tanımlanabilir.
- İsimsel (Nominal) Değişkenler
- İkili (Binary) Değişkenler
- Sıra Gösteren (Ordinal) Değişkenler
- Tam sayılı (Integer) Değişkenler
- Çıktı kaliteli değişkenler
Seçenekler
A
Yalnız V
B
I - II
C
III - IV
D
II - III - V
E
I - II - III - IV
Açıklama:
Bir nesnenin özelliklerinin ölçme şekline göre bir çok değişken tipi tanımlanabilir. Bu değişkenler şu şekilde sıralanabilir:
- İsimsel (Nominal) Değişkenler
- İkili (Binary) Değişkenler
- Sıra Gösteren (Ordinal) Değişkenler
- Tam sayılı (Integer) Değişkenler
- Aralıklı Ölçümlendirilmiş (Interval-Scaled) Değişkenler
- Oranlı Ölçümlendirilmiş (Ratio-Scaled) Değişkenler
Soru 73
"Bir varlığın ağırlığı için “sıfır” ifadesi kullanıldığında ölçüm metrik türüne bakılmadan bu varlığın ağırlığının olmadığı anlamı çıkarılır. Diğer bir deyişle sıfır kilogram ve sıfır gram aynı anlamı taşır."
Metinde verilen özellik aşağıdaki değişkenlerden hangisine aittir?
Metinde verilen özellik aşağıdaki değişkenlerden hangisine aittir?
Seçenekler
A
Oranlı Ölçümlendirilmiş (Ratio-Scaled) Değişkenler
B
İkili (Binary) Değişkenler
C
Sıra Gösteren (Ordinal) Değişkenler
D
Tam sayılı (Integer) Değişkenler
E
Aralıklı Ölçümlendirilmiş (Interval-Scaled) Değişkenler
Açıklama:
Oranlı ölçümlendirilmiş (ratio-scaled) değişkenler aralıklı ölçümlendirilmiş (interval-scaled) değişkenlere benzer olmakla beraber bu değişkende sıfır başlangıç noktası tüm ölçüm araçlarında aynı anlamı taşır. Örneğin; bir varlığın ağırlığı için “sıfır” ifadesi kullanıldığında ölçüm metrik türüne bakılmadan bu varlığın ağırlığının olmadığı anlamı çıkarılır. Diğer bir deyişle sıfır kilogram ve sıfır gram aynı anlamı taşır. Oranlı ölçümlendirilmiş (ratio-scaled) değişkenler daha önce ele alınan değişken tiplerinin tüm özelliklerini içerir. En büyük özelliği yokluk anlamına gelen belirli bir sıfır değerini barındırıyor olması bu nedenle ölçme düzeyleri arasında oransal analizler yapılabilmesine olanak tanıyor olmasıdır.
Soru 74
- eksik veri
- veri kümeleme
- gürültülü veri
- tutarsızlık
Seçenekler
A
Yalnız I
B
Yalnız II
C
III - IV
D
I - III - IV
E
I - II - III - IV
Açıklama:
Veri temizleme için temel yöntemler eksik veri, gürültülü veri ve tutarsızlık olmak üzere üç temel başlıkta gruplanabilir.
Soru 75
- veri küpü birleştirme
- boyut indirgeme
- tutarsız veri silme
- veri sıkıştırma
- büyük sayıların indirgenmesi
Seçenekler
A
Yalnız V
B
I - II
C
III - IV
D
I - II - III
E
I - II - IV - V
Açıklama:
Veri indirgeme yöntemleri olarak veri küpü birleştirme, boyut indirgeme, veri sıkıştırma ve büyük sayıların indirgenmesi yöntemleri ortaya çıkar.
Soru 76
Veri dönüştürme işlemlerine ilişkin aşağıda verilen bilgilerden hangisi yanlıştır?
Seçenekler
A
Düzeltme; bölmeleme, kümeleme ve regresyon gibi teknikler kullanılarak verilerdeki gürültü oluşturmaktır.
B
Bir araya getirme; veriler bir araya getiren gruplama fonksiyonları kullanılarak gerçekleştirilir.
C
Genelleme; düşük düzeydeki verinin kavram hiyerarşisi kullanılarak daha yüksek
seviyeye dönüştürülmesidir.
seviyeye dönüştürülmesidir.
D
Normalleştirme veya standartlaştırma; bir değişkenin standartlaştırılması
veya normalleştirilmesi yaygın olarak kullanılan veri dönüşüm tekniğidir.
veya normalleştirilmesi yaygın olarak kullanılan veri dönüşüm tekniğidir.
E
Özellik oluşturma; yeni özellikler madencilik sürecine yardımcı olmak için verilen özellikler kümesinden oluşturulur ve düzenlenir.
Açıklama:
Veri dönüşümünde verilerin veri madenciliği için uygun formlara dönüştürülmesi düzeltme, bir araya getirme, genelleme, normalleştirme ve özellik oluşturma işlemleriyle gerçekleştirilir.
- Düzeltme; bölmeleme, kümeleme ve regresyon gibi teknikler kullanılarak verilerdeki gürültünün temizlenmesidir.
- Bir araya getirme; veriler bir araya getiren gruplama fonksiyonları kullanılarak gerçekleştirilir. Günlük temelde bulunan bir veri özelliğinin aylık temele dönüştürülmesi örnek verilebilir.
- Genelleme; düşük düzeydeki verinin kavram hiyerarşisi kullanılarak daha yüksek seviyeye dönüştürülmesidir. Örneğin; yaş gibi sayısal verilerin kategorik olan genç, orta yaşlı veya yaşlı gibi değerlere dönüştürülmesi ya da cadde isimlerinden oluşan kategorik verilerin şehir veya ülke şeklinde daha yüksek kavramlara dönüştürülmesidir.
- Normalleştirme veya standartlaştırma; bir değişkenin standartlaştırılması
veya normalleştirilmesi yaygın olarak kullanılan veri dönüşüm tekniğidir. Veri madenciliği terminolojisinde her iki terim birbiri yerine kullanılmaktadır. - Özellik oluşturma; yeni özellikler madencilik sürecine yardımcı olmak için verilen özellikler kümesinden oluşturulur ve düzenlenir. Özellik oluşturma karar ağacı algoritmaları sınıflama için kullanıldığında bölümleme problemini azaltmaya yardımcı olabilir. Yükseklik ve genişlik özelliklerinden alan özelliğinin oluşturulması bu duruma bir örnek olarak verilebilir.
Soru 77
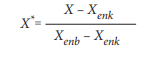 Enk-Enb normalleştirme formülüne ilişkin aşağıdaki seçeneklerden hangisi doğrudur?
Enk-Enb normalleştirme formülüne ilişkin aşağıdaki seçeneklerden hangisi doğrudur?Seçenekler
A
X: Dönüştürülmüş değer
B
X*: Gözlem değeri
C
Xenk: Verideki en küçük gözlem değeri
D
Xenb: Verideki en küçük değer
E
Xenb: Verideki gözlem değeri
Açıklama:

Soru 78
 z-Skor normalleştirme formülüdür.
z-Skor normalleştirme formülüdür.- X: Gözlem değeri
- X*: Dönüştürülmüş değer
- s: Değişkenin standart sapması
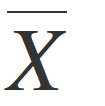 : Verideki en büyük değer
: Verideki en büyük değer
Formüle ilişkin yukarıdaki maddelerden hangileri doğrudur?
Seçenekler
A
Yalnız I
B
Yalnız II
C
III - IV
D
I - II - III
E
I - II - III - IV
Açıklama:

Soru 79
".......................... yönteminde değişkene (özellik) ilişkin gözlem değerlerinin ondalık bölümü hareket ettirilerek normalleştirme gerçekleştirilir. Hareket ettirilecek ondalık bölüm değişkenin maksimum mutlak değeri ile bağlantılıdır."
Metinde verilen boşluğa aşağıdaki seçeneklerden hangisi getirilmelidir?
Metinde verilen boşluğa aşağıdaki seçeneklerden hangisi getirilmelidir?
Seçenekler
A
Ondalık ölçekleme
B
Aritmetik ölçekleme
C
z-Skor normalleştirme
D
Enk normalleştirme
E
Enb normalleştirme
Açıklama:
Ondalık ölçekleme yönteminde değişkene (özellik) ilişkin gözlem değerlerinin ondalık bölümü hareket ettirilerek normalleştirme gerçekleştirilir. Hareket ettirilecek ondalık bölüm değişkenin maksimum mutlak değeri ile bağlantılıdır.
Soru 80
Market çalışanlarının yönetim katından en alt kademeye kadar sıralanması örneği aşağıdaki hangi değişkene örnek olarak verilebilir?
Seçenekler
A
İkili değişkenler
B
Sıra gösteren değişkenler
C
Tam sayılı değişkenler
D
Aralıklı ölçümlendirilmiş değişkenler
E
Oranlı ölçümlendirilmiş değişkenler
Açıklama:
Market çalışanlarının yönetim katından en alt kademeye kadar sıralanması örneği sıra gösteren değişkene örnek olarak verilebilir.
Soru 81
Markette bir gün içinde satılan ekmek sayısı, belli bir depodaki koli sayısı ya da palet sayısı, bir ailedeki çocuk sayısı aşağıdaki hangi değişken türüne örnektir?
Seçenekler
A
İsimsel Değişkenler
B
İkili Değişkenler
C
Sıra Gösteren Değişkenler
D
Tam Sayılı Değişkenler
E
Aralıklı Ölçümlendirilmiş Değişkenler
Açıklama:
Alacağı değerler 0, 1, 2, ... gibi tamsayılar olarak belirtilebilen değişkenlerdir. Bu nedenletam sayılı değişkenlerin ondalıklı değerler alması söz konusu değildir. Markette bir gün içinde satılan ekmek sayısı, belli bir depodaki koli sayısı ya da palet sayısı, bir ailedeki çocuk sayısı örnek olarak verilebilir. Tam sayılı değişkenlerle toplama, çıkarma ve çarpma işlemleri yapmak anlamlıdır.
Soru 82
Hava sıcaklığı nicel ölçme düzeyine sahiptir ve yokluk anlamına gelmeyen sıfır değeri bulunabilir. Buradaki sıfır ölçme düzeyi havada sıcaklığın olmadığı anlamına gelmez. Bu değişken için matematiksel işlemler uygun olmakla beraber oran hesaplamaları için uygun değildir. Bu hangi değişken türüne örnektir?
Seçenekler
A
Aralıklı Ölçümlendirilmiş Değişkenler
B
Oranlı Ölçümlendirilmiş Değişkenler
C
Sıra Gösteren Değişkenler
D
İkili Değişkenler
E
İsimsel Değişkenler
Açıklama:
Hava sıcaklığı nicel ölçme düzeyine sahiptir ve yokluk anlamına gelmeyen sıfır değeri bulunabilir. Buradaki sıfır ölçme düzeyi havada sıcaklığın olmadığı anlamına gelmez. Bu değişken için matematiksel işlemler uygun olmakla beraber oran hesaplamaları için uygun değildir.
Soru 83
Aşağıdakilerden hangisi sürekli değişkenler grubunda yer alır?
Seçenekler
A
İsimsel Değişkenler
B
İkili Değişkenler
C
Sıra Gösteren Değişkenler
D
Tam Sayılı Değişkenler
E
Hiçbiri
Açıklama:
Kategorik değişkenler grubunda isimsel (nominal), ikili (binary) ve sıra gösteren (ordinal) değişkenler girerken sürekli değişkenler grubuna tam sayılı (integer), aralıklı ölçümlendirilmiş (interval-scaled) ve oranlı ölçümlendirilmiş (ratio-scaled) değişkenler girer.
Soru 84
Aşağıdakilerden hangisi kategorik değişkenler grubunda yer alır?
Seçenekler
A
İkili Değişkenler
B
Tam sayılı Değişkenler
C
Aralıklı Ölçümlendirilmiş Değişkenler
D
Oranlı Ölçümlendirilmiş Değişkenler
E
Hepsi
Açıklama:
Kategorik değişkenler grubunda isimsel (nominal), ikili (binary) ve sıra gösteren (ordinal) değişkenler girerken sürekli değişkenler grubuna tam sayılı (integer), aralıklı ölçümlendirilmiş (interval-scaled) ve oranlı ölçümlendirilmiş (ratio-scaled) değişkenler girer.
Soru 85
Aşağıdakilerden hangisi gürültülü veri oluşmasına neden olmaz?
Seçenekler
A
Veri girişi problemleri
B
Veri iletimi problemleri
C
Son teknolojinin kullanımı
D
Özellik isimlerindeki tutarsızlık
E
Hatalı veri toplama gereçleri
Açıklama:
Ölçülen bir değerdeki hata ve yanlış özellik değerleri ki bunlar; hatalı veri toplama gereçlerinden, veri girişi problemlerinden, veri iletimi problemlerinden, teknolojik kısıtlardan ve özellik isimlerindeki tutarsızlıktan gürültülü veri olarak tanımlanan veri oluşmasına neden olur.
Soru 86
Gürültülü veri aşağıdakilerden hangi veri hazırlama sürecinde yer alır?
Seçenekler
A
Veri Temizleme
B
Veri Dönüştürme
C
Veri Birleştirme
D
Veri İndirgeme
E
Veri Küpü Birleştirme
Açıklama:
Veri temizleme için temel yöntemler eksik veri, gürültülü veri ve tutarsızlık olmak üzere üç temel başlıkta gruplanabilir.
Soru 87
Aylık satış fiyatlarının yıllık temelde daha küçük veri seti haline dönüştürülmesi aşağıdakilerden hangisine örnek olarak verilebilir?
Seçenekler
A
Veri sıkıştırma
B
Veri küpü birleştirme
C
Boyut indirgeme
D
Büyük sayıların indirgenmesi
E
Veri dönüştürme
Açıklama:
Veri indirgeme yöntemleri olarak; veri küpü birleştirme, boyut indirgeme, veri sıkıştırma ve büyük sayıların indirgenmesi yöntemleri ortaya çıkar. Aylık satış fiyatlarının yıllık temelde daha küçük veri seti haline dönüştürülmesi veri küpü birleştirmeye örnek olarak verilebilir.
Soru 88
R yazılımının “cluster.Sim” paketinde kaç tane veri normalleştirme yöntemi bulunmaktadır?
Seçenekler
A
4
B
10
C
12
D
16
E
20
Açıklama:
R yazılımının “cluster.Sim” paketinde 16 tane veri normalleştirme yöntemi bulunmaktadır. Normalleştirme işlemini gerçekleştirmek için “data.Normalization(x,type=”n0”,normalization=”column”)” komutu kullanılır.
Soru 89
Minimum değeri 148 maksimum değeri 472 olan bir değişkenin, 356 değerini enk-enb normalleştirme yöntemine göre dönşümü sonucu kaçtır?
Seçenekler
A
0
B
0,056
C
0,296
D
0,642
E
1
Açıklama:
Enk-Enb Normalleştirme
Orijinal veri üzerinde doğrusal bir dönüşüm yapan bu yöntem veri içindeki en büyük ve en küçük sayısal değerin belirlenerek diğer değerleri buna uygun bir şekilde dönüştürülmesiyle yapılır. Enk-Enb normalleştirme sonucunda veri sıfır (en küçük değer) ile bir (en büyük değer) arasında sayısal bir değere dönüşür.
356 - 148 / 472 - 148 = 0,642
Orijinal veri üzerinde doğrusal bir dönüşüm yapan bu yöntem veri içindeki en büyük ve en küçük sayısal değerin belirlenerek diğer değerleri buna uygun bir şekilde dönüştürülmesiyle yapılır. Enk-Enb normalleştirme sonucunda veri sıfır (en küçük değer) ile bir (en büyük değer) arasında sayısal bir değere dönüşür.
356 - 148 / 472 - 148 = 0,642
Ünite 4
Soru 1
Nesneler arasında 1 hiç benzerlik olmadığını, 100 ise tam benzerlik olduğunu göstermek üzere elde edilmiş olan 25 benzerlik değerinin [0,1] aralığına düşecek şekilde dönüşümü yapılmış karşılığı aşağıdakilerden hangisidir?
Seçenekler
A
0,17
B
0,24
C
0,33
D
0,45
E
0,49
Açıklama:
s=25 için
s'=(s-enk(s))/(enb(s)-enk(s))
s'=(25-1)/(100-1)=24/99=0,24
s'=(s-enk(s))/(enb(s)-enk(s))
s'=(25-1)/(100-1)=24/99=0,24
Soru 2
[30,200] kapalı aralığında hesaplanmış s = 100 benzerlik değerinin [0,1] aralığındaki karşılığını bulunuz?
Seçenekler
A
0,17
B
0,25
C
0,36
D
0,41
E
0,57
Açıklama:
s'=(s-enk(s))/(enb(s)-enk(s))
s'=(100-30)/(200-30)
=70/170
=0,41
s'=(100-30)/(200-30)
=70/170
=0,41
Soru 3
[0,∞) aralığında değerler alan ve d = 3 olarak elde edilmiş uzaklık değerinin [0,1] aralığına düşen karşılığı aşağıdakilerden hangisidir?
Seçenekler
A
0,10
B
0,25
C
0,50
D
0,75
E
0,99
Açıklama:
d'=d/(1+d)
d'=3/4
=0,75
d'=3/4
=0,75
Soru 4
Bir ürünle ilgili olarak; Çok kötü=0, Kötü=1, Orta=2, İyi=3, ve Çok iyi=4 olmak üzere değerlendirilme yapılmıştır ve sırasıyla Kötü ve Çok iyi olarak iki ürün tespit edilmiştir. Buna göre bu iki ürün arasındaki uzaklık değeri aşağıdakilerden hangisidir?
Seçenekler
A
0
B
1
C
2
D
3
E
4
Açıklama:
d(x,y)=|x-y|=|1-4|=3
Soru 5
Bir ürünle ilgili olarak; Çok kötü=0, Kötü=1, Orta=2, İyi=3, ve Çok iyi=4, Mükemmel=5 olmak üzere değerlendirilme yapılmıştır ve sırasıyla Orta ve Mükemmel olarak iki ürün tespit edilmiştir. Buna göre bu iki ürün arasındaki uzaklık değerinin [0,1] aralığındaki ifadesi aşağıdakilerden hangisidir?
Seçenekler
A
0,1
B
0,2
C
0,4
D
0,5
E
0,6
Açıklama:
d(x,y)=|x-y|=|2-5|=3
d(x,y)/(n-1) ise 3/5=0,6
d(x,y)/(n-1) ise 3/5=0,6
Soru 6
- Sınıflayıcı ölçek
- Sıralayıcı ölçek
- Aralıklı ve oransal ölçek
Seçenekler
A
Yalnız I
B
Yalnız II
C
Yalnız III
D
I ve II
E
I, II ve III
Açıklama:
Sınıflayıcı ve sıralayıcı ölçek ile ölçülebilen değişkenler nitel, aralıklı ve oransal ölçek ile ölçülebilen değişkenler ise nicel değişkenler olarak adlandırılırlar.
Soru 7
Aşağıdakilerden hangisi nicel değişkenlerden elde edilen gözlem değerleri arasındaki yakınlığın belirlenmesinde yararlanılan ölçülerden biri değildir?
Seçenekler
A
Karl Pearson Uzaklığı
B
Thales Uzaklığı
C
Öklid Uzaklığı
D
Manhattan Uzaklığı
E
Mahalanobis Uzaklığı
Açıklama:
Thales uzaklığı, nicel değişkenlerden elde edilen gözlem değerleri arasındaki yakınlığın belirlenmesinde yararlanılan ölçülerden biri değildir.
Soru 8
Öklid ve karesel öklid uzaklığı ile ilgili aşağıda verilen ifadelerden hangisi yanlıştır?
Seçenekler
A
Uzaklık ölçüleri arasında en yaygın kullanılan uzaklık ölçüleri Öklid ve Karesel Öklid
uzaklık ölçüleridir.
uzaklık ölçüleridir.
B
Öklid uzaklığı, i’inci ve j’inci nesnelerin p tane değişken için farklarının kareleri toplamının karekökü alınarak elde edilir.
C
Öklid uzaklık ölçüsü, değişkenlerin birbirinden bağımsız olduklarını varsayar.
D
Öklid uzaklığının hesaplanabilmesi için verilerin oransal ya da aralıklı ölçekle ölçülmüş olması gerekir.
E
Öklid uzaklığı "sıfır" ile "bir" arasında değerler alır yani tanım aralığı [0,1]’dir.
Açıklama:
Öklid uzaklığı “sıfır” ile “sonsuz” arasında değerler alır yani tanım aralığı [0,∞)’dur.
Soru 9
Uzaklık iki nesne arasındaki aşağıdakilerden hangi niteliğin bir ölçüsünü ifade etmektedir?
Seçenekler
A
Mantıksallığın
B
Nesnenin benzerliğinin
C
Özelliğinin
D
Düzensizliğin ve bozukluğun
E
Ayrışmanın
Açıklama:
İki nesne arasındaki düzensizliğin veya bozukluğun bir ölçüsü olan uzaklık, farklılığın özel bir sınıfı, alt kümesidir.
Soru 10
Benzerlik ve uzaklık değerleri ile ilgili olarak aşağıdakilerden hangisi doğrudur?
Seçenekler
A
İki nesne arasındaki yüksek benzerlik değeri nesnelerin benzer olduklarını, yüksek uzaklık değeri ise nesnelerin benzer olmadıklarını ifade eder.
B
İki nesne arasındaki yüksek benzerlik değeri nesnelerin ayrık olduklarını, yüksek uzaklık değeri ise nesnelerin benzer olduklarını ifade eder.
C
Niteliksel olarak benzer olduklarını niceliksel olarak ayrık olduklarını ifade eder.
D
İki nesne arasındaki yüksek benzerlik değeri nesnelerin benzer olmadıklarını, yüksek uzaklık değeri ise nesnelerin benzer olduklarını ifade eder.
E
Niceliksel olarak benzer olduklarını niteliksel olarak ayrık olduklarını ifade eder.
Açıklama:
ki nesne arasındaki yüksek benzerlik değeri nesnelerin benzer olduklarını, yüksek uzaklık değeri ise nesnelerin benzer olmadıklarını ifade eder.
Soru 11
Özellikle ekolojik araştırmalarda belirli bir nesnenin farklı bölgelerde var olup olmadığının belirlenmesinde kullanılan ölçü aşağıdakilerden hangisidir?
Seçenekler
A
Jaccard benzerlik katsayısı
B
Açısal benzerlik (cosine similarity)
C
Mahalanobis uzaklığı
D
Basit eşleştirme katsayısı
E
Binary Öklid uzaklığı
Açıklama:
Jaccard benzerlik katsayısı özellikle ekolojik araştırmalarda belirli bir nesnenin farklı bölgelerde var olup olmadığının belirlenmesinde kullanılmaktadır.
Soru 12
Nicel değişkenlerden elde edilen gözlem değerleri arasındaki yakınlığın belirlenmesinde aşağıdakilerden hangisinden yararlanılmaz?
Seçenekler
A
Öklid Uzaklığı
B
Manhattan Uzaklığı
C
Mahalanobis Uzaklığı
D
Korelasyon Uzaklığı
E
Büyüklük Farkı
Açıklama:
Nicel değişkenlerden elde edilen gözlem değerleri arasındaki yakınlığın belirlenmesinde Öklid uzaklığı, Karesel Öklid uzaklığı, Karl Pearson uzaklığı, Manhattan uzaklığı, Minkowski uzaklığı, Mahalanobis uzaklığı, Korelasyon uzaklığı ve Açısal benzerlik ölçülerinden yararlanılır.
Soru 13
En yaygın olarak kullanılan uzaklık ölçüleri aşağıdakilerden hangisidir?
Seçenekler
A
Lewinstein Uzaklık Ölçüsü
B
Öklid ve Karesel Öklid Uzaklık Ölçüleri
C
Manhattan Uzaklığk Ölçüsü
D
Mahalanobis Uzaklık Ölçüsü
E
Korelasyon Uzaklık Ölçüsü
Açıklama:
Uzaklık ölçüleri arasında en yaygın kullanılan uzaklık ölçüleri Öklid ve Karesel Öklid uzaklık ölçüleridir.
Soru 14
R ile Öklid uzaklığı hesaplayabilmek için R’nin temel paketlerinden stats paketinde yer alan aşağıdakilerden hangi fonksiyondan yararlanılır?
Seçenekler
A
Abs()
B
Log()
C
Dist()
D
Exp()
E
Sqrt()
Açıklama:
R ile Öklid uzaklığı hesaplayabilmek için R’nin temel paketlerinden stats paketinde yer alan dist() fonksiyonundan yararlanılır.
Soru 15
Aşağıdakilerden hangisi Karl Pearson uzaklık ölçüsünün tanımıdır?
Seçenekler
A
İki kareler toplamının farkıdır.
B
Minkowski Uzaklığının kare köküdür.
C
Karesel öklid uzaklığının varyansının değişkene oranıdır.
D
Öklid uzaklığının değişkenin varyansına oranlanması ile elde edilen bir uzaklıktır.
E
Kareler arasındaki farkın kare köküdür.
Açıklama:
Karl Pearson uzaklığı, Öklid uzaklığının değişkenin varyansına oranlanması ile elde edilen bir uzaklıktır.
Soru 16
n sayıda birim ve p sayıda değişken ile çalışılırken birimler yada değişkenler arasındaki uzaklıkları hesaplamak için kullanılan genel bir uzaklık ölçüsüdür.”
Yukarıda tanımı yapılan uzaklık ölçüsü aşağıdakilerden hangisidir?
Yukarıda tanımı yapılan uzaklık ölçüsü aşağıdakilerden hangisidir?
Seçenekler
A
Levinstein Uzaklığı
B
Öklid uzaklığı
C
Minkowski uzaklığı
D
Karl Pearson uzaklığı
E
kullback leibler uzaklığı
Açıklama:
Minkowski Uzaklığı , n sayıda birim ve p sayıda değişken ile çalışılırken birimler yada değişkenler arasındaki uzaklıkları hesaplamak için kullanılan genel bir uzaklık ölçüsüdür.
Soru 17
Açısal benzerlik özellikle aşağıdakilerden hangisinde kullanılmaktadır?
Seçenekler
A
Belge ve çoklu ortam nesnelerinin kıyaslanmasında ve metin madenciliğini uygulamalarında
B
Harita uzaklığının hesaplanmasında
C
Biçim farkınını içeren uygulamalarda
D
Büyüklük farkını içeren uygulamalarda
E
Resim işleme metodları ve yüz tanıma uygulamalarında
Açıklama:
Açısal benzerlik, özellikle belge ve çoklu ortam nesnelerinin kıyaslanmasında ve metin madenciliğinde kullanılmaktadır.
Soru 18
İki sonuçlu değişkenler içeren gözlem çiftleri arasındaki yakınlığın belirlenmesinde aşağıdakilerden hangisinden yararlanılmaz?
Seçenekler
A
Büyüklük Farkı (Size Difference)
B
Karl Pearson Uzaklık Ölçüsü
C
Biçim Farkı (Shape Difference)
D
Lance ve Williams Uzaklık Ölçüsü
E
Örüntü Farkı (Pattern Difference)
Açıklama:
İki sonuçlu değişkenler içeren gözlem çiftleri arasındaki yakınlığın belirlenmesinde Öklid, Karesel Öklid, Büyüklük Farkı (Size Difference), Örüntü Farkı (Pattern Difference), Lance ve Williams Uzaklık Ölçüsü, Biçim Farkı (Shape Difference) ve Jaccard Benzerliği (Jaccard Similarity) gibi birçok benzerlik ya da uzaklık ölçülerinden yararlanılmaktadır.
Soru 19
ki sonuçlu değişkenler içeren nesne çiftinin karşılıklı eşleşen değerlerinin tekrar sayılarından oluşan tablonun adı aşağıdakilerden hangisidir?
Seçenekler
A
T-Kare tablosu
B
Olasılık yoğunluk tablosu
C
Jaccard Benzerlik tablosu
D
Lawrance ve Williams Uzaklık tablosu
E
Kontenjans/Çapraz Sınıflama
Açıklama:
ki yönlü sınıflama tablosu olarak da adlandırılan kontenjans tablosu, iki sonuçlu değişkenler içeren nesne çiftinin karşılıklı eşleşen değerlerinin tekrar sayılarından oluşan tablodur.
Soru 20
- L1 norm olarak da bilinir
- Minkowski uzaklığının özel bir halidir.
- Aykırı değerlere karşı hassasiyeti düşüktür.
Seçenekler
A
Manhattan uzaklığı
B
Karl Pearson uzaklığı
C
Öklid uzaklığı
D
Mahalanobis uzaklığı
E
Jaccard uzaklığı
Açıklama:
Özellikleri verilen uzaklık ölçüsü Manhattan uzaklığıdır.
Soru 21
Benzerlik ve uzaklık ile ilgili aşağıdaki ifadelerden hangisi yanlıştır?
Seçenekler
A
Uzaklık [-1,1] aralığında değer alır
B
Uzaklık farklılığın bir alt kümesidir
C
Benzerlik iki nesnenin birbirine benzeme derecesinin sayısal bir ölçüsüdür
D
Benzerlik [-1,1] aralığında değer alır
E
Yüksek uzaklık değeri nesnelerin benzer olmadıklarını ifade eder
Açıklama:
Uzaklık kimi zaman [0,1] aralığına düşecek şekilde tanımlansa da genel olarak  aralığındadır. Bu nedenle doğru cevap A seçeneğidir.
aralığındadır. Bu nedenle doğru cevap A seçeneğidir.
Soru 22
Nesneler arasında 1 hiç benzerliğin olmadığını 100 ise tam benzerliğin olduğunu göstermek üzere elde edilmiş olan 65 benzerlik değerinin [0,1] aralığına düşen dönüşüm değeri nedir?
Seçenekler
A
0,29
B
0,65
C
0,44
D
0,69
E
0,73
Açıklama:
s=65 için s'=(65-1)/(100-1)=(64/99)=0,65 olur. Bu nedenle doğru cevap B'dir.
Soru 23
Seçenekler
A
0,92
B
0,95
C
0,98
D
0,89
E
0,94
Açıklama:
d=60 için d'=d/(1+d)=60/(60+1)=(60/61)=0,98 olur. Bu nedenle doğru cevap C seçeneğidir.
Soru 24
[30,60] kapalı aralığında hesaplanmış s=45 benzerlik değerinin [0,1] aralığındaki karşılığı nedir?
Seçenekler
A
0,35
B
0,4
C
0,45
D
0,5
E
0,55
Açıklama:
s=45 için s'=(45-30)/(60-30)=(15/30)=0,5 olur. Bu nedenle doğru yanıt D olmaktadır.
Soru 25
Ahmet'in yöneylem dersinden aldığı not 65 ve karar kuramı dersinden aldığı not 80 iken Mehmet'in aldığı notlar sırasıyla 50 ve 90'dır. Buna göre Ahmet ve Mehmet arasındaki öklid uzaklığı kaçtır?
Seçenekler
A
18,02
B
11,25
C
35,73
D
27,16
E
15,93
Açıklama:
Soru 26
Ahmet'in yöneylem dersinden aldığı not 65 ve karar kuramı dersinden aldığı not 80 iken Mehmet'in aldığı notlar sırasıyla 50 ve 90'dır. Ayrıca yöneylem dersi varyansı  ve karar kuramı dersi varyansı
ve karar kuramı dersi varyansı  olduğu varsayıldığında Ahmet ile Mehmet arasındaki Karl Pearson uzaklığı kaçtır?
olduğu varsayıldığında Ahmet ile Mehmet arasındaki Karl Pearson uzaklığı kaçtır?
Seçenekler
A
2,75
B
5,08
C
4,53
D
0,85
E
3,28
Açıklama:

Bu nedenle doğru cevap 5,08 olup B şıkkıdır.
Soru 27
Ahmet'in yöneylem dersinden aldığı not 65 ve karar kuramı dersinden aldığı not 80 iken Mehmet'in aldığı notlar sırasıyla 50 ve 90'dır. Buna göre Ahmet ve Mehmet arasındaki Manhattan uzaklığı kaçtır?
Seçenekler
A
15
B
35
C
25
D
45
E
40
Açıklama:
Soru 28
C ve D değişkenleri için [-1,+1] aralığında değerler alan ve -0,65 olarak bulunan korelasyon katsayısı dikkate alındığında elde edilecek korelasyon uzaklığı değeri ne olur?
Seçenekler
A
0,75
B
0,8
C
0,815
D
0,825
E
0,85
Açıklama:
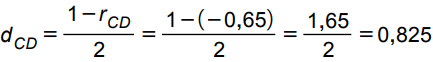 Bu nedenle doğru cevap D olmaktadır.
Bu nedenle doğru cevap D olmaktadır.Soru 29
R yazılımında lsa paketindeki cosine() fonksiyonu neyi elde etmede kullanılır?
Seçenekler
A
Karl Pearson uzaklığı
B
Jaccard uzaklığı
C
Korelasyon uzaklığı
D
Basit eşleştirme uzaklığı
E
Açısal benzerlik
Açıklama:
R ile Açısal benzerlik değerini hesaplayabilmek için lsa paketinde yer alan cosine() fonksiyonundan yararlanılır. Bu nedenle doğru cevap E olmaktadır.
Soru 30
Aşağıdakilerden hangisi iki sonuçlu değişkenler için kullanılan yakınlık ölçülerinden birisidir?
Seçenekler
A
Karl Pearson uzaklığı
B
Manhattan uzaklığı
C
Minkowski uzaklığı
D
Açısal benzerlik
E
Jaccard uzaklığı
Açıklama:
İki sonuçlu değişkenler için kullanılan yakınlık ölçüleri şu şekilde sıralanır: a)Basit eşleştirme katsayısı ve uzaklığı b)Binary öklid ve karesel öklid uzaklığı c)Jaccard benzerlik katsayısı ve uzaklığı. Bu nedenle doğru cevap E'dir.
Soru 31
İki nesne arasındaki yüksek uzaklık değeri bu iki nesne için neyi ifade eder?
Seçenekler
A
Benzer olduklarını
B
Benzer olmadıklarını
C
İlişkisiz olduklarını
D
d(x,y)=0 ifadesini sağladığını
E
s(x,y)=1 ifadesini sağladığını
Açıklama:
İki nesne arasındaki yüksek benzerlik değeri nesnelerin benzer olduklarını, yüksek uzaklık değeri ise nesnelerin benzer olmadıklarını ifade eder.
Doğru cevap B şıkkıdır.
Doğru cevap B şıkkıdır.
Soru 32
Minkowski uzaklığı, n sayıda birim ve p sayıda değişken ile çalışılırken birimler yada değişkenler arasındaki uzaklıkları hesaplamak için kullanılan genel bir uzaklık ölçüsüdür. Minkowski uzaklığıLλ norm olarak da bilinir. λ=1 olarak alınırsa hangi uzaklığa dönüşür?
Seçenekler
A
Öklid Uzaklığı
B
Karl Pearson Uzaklığı
C
Manhattan (City-Block) Uzaklığı
D
Jaccard Benzerlik Uzaklığı
E
Mahalanobis Uzaklığı
Açıklama:
Minkowski uzaklık formülünde λ=1 olarak alınırsa Manhattan (City-Block) Uzaklığına dönüşür.
Doğru cevap C şıkkıdır.
Doğru cevap C şıkkıdır.
Soru 33
Minkowski uzaklığı, n sayıda birim ve p sayıda değişken ile çalışılırken birimler yada değişkenler arasındaki uzaklıkları hesaplamak için kullanılan genel bir uzaklık ölçüsüdür. Minkowski uzaklığı Lλ norm olarak da bilinir. λ=1 olarak alınırsa hangi uzaklığa dönüşür?
Seçenekler
A
Manhattan Uzaklığı
B
Korelasyon Uzaklığı
C
Mahalanobis Uzaklığı
D
Jaccard Benzerlik Uzaklığı
E
Basit Eşleştirme Uzaklığı
Açıklama:
Minkowski uzaklık formülünde λ=1 olarak alınırsa Manhattan (City-Block) Uzaklığına dönüşür.
Doğru cevap A şıkkıdır.
Doğru cevap A şıkkıdır.
Soru 34
Veri matrisi olarak girilen x değişkenine ait nesneler arasındaki belirli uzaklık ölçüm değerlerini R ile hesaplamak için hangi fonksiyon kullanılmaktadır?
Seçenekler
A
stats
B
data.frame
C
sqrt
D
sim
E
dist
Açıklama:
dist() fonksiyonu yardımıyla veri matrisi olarak girilen x değişkenine ait nesneler arasındaki belirli uzaklık ölçüm değerleri hesaplanabilir.
Doğru cevap E şıkkıdır.
Doğru cevap E şıkkıdır.
Soru 35
Açısal benzerlik, iki vektör arasındaki açı farkının kosinüsünün bu iki vektör arasındaki uzaklık olarak alınması suretiyle değişkenler arasındaki benzerliğin belirlenmesine yönelik bir benzerlik ölçüsüdür. İki vektör arasındaki açı farkının sıfır olması iki vektör için neyi ifade eder?
Seçenekler
A
Benzer olduklarını
B
Farklı olduklarını
C
Bağımsız olduklarını
D
Birbirine dik olduklarını
E
Kesiştiklerini
Açıklama:
İki vektör arasındaki açı farkı sıfır olduğunda yani vektörler birbirlerine paralel olduklarında kosinüs değeri 1 olurken bu iki vektör arasındaki açı farkı 90° olduğunda yani vektörler birbirlerine dik olduklarında kosinüs değeri 0 olur.
Dolayısıyla açı farkının sıfır olması vektörlerin benzer olduğu anlamına gelir.
Dolayısıyla açı farkının sıfır olması vektörlerin benzer olduğu anlamına gelir.
Soru 36
İstatistik sınav notları ile değerlendirilen A ve B grupları arasındaki Pearson korelasyon katsayısı rAB = 0,4 olarak elde edilmiştir. Bu iki grup arasındaki korelasyon uzaklık değeri kaçtır?
Seçenekler
A
0.2
B
0.50
C
0.15
D
0.65
E
0.3
Açıklama:
dxy=(1-0.4)/2=0.3 olduğu görülür.
Soru 37
Tesadüfi olarak seçilen bir değişkende her iki nesnenin de aynı özelliğe
sahip olma olasılığını veren bir katsayı aşağıdakilerden hangisidir?
sahip olma olasılığını veren bir katsayı aşağıdakilerden hangisidir?
Seçenekler
A
Basit eşleştirme katsayısı
B
Alfa kesim noktası
C
Uzaklık katsayısı
D
Üyelik katsayısı
E
Referans katsayısı
Açıklama:
Basit eşleştirme katsayısı, p tane değişken açısından ilgilenilen nesnelerin her ikisinde de
olmama (0-0) ve olma (1-1) durum sayılarının oranını gösteren bir benzerlik ölçüsüdür.
Diğer bir anlatımla, tesadüfi olarak seçilen bir değişkende her iki nesnenin de aynı özelliğe sahip olma olasılığını veren bir katsayıdır.
Doğru cevap A şıkkıdır.
olmama (0-0) ve olma (1-1) durum sayılarının oranını gösteren bir benzerlik ölçüsüdür.
Diğer bir anlatımla, tesadüfi olarak seçilen bir değişkende her iki nesnenin de aynı özelliğe sahip olma olasılığını veren bir katsayıdır.
Doğru cevap A şıkkıdır.
Soru 38
[50,130] kapalı aralığında hesaplanmış s = 70 benzerlik değerinin [0,1] aralığındaki karşılığı kaçtır?
Seçenekler
A
0.35
B
0,60
C
0
D
0.75
E
0.25
Açıklama:
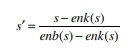 formülünde sınır değerlerini (en küçük ve en büyük değerleri) ve istenen değeri yerine yazdığımızda istenen sonuç elde edilecektir.
formülünde sınır değerlerini (en küçük ve en büyük değerleri) ve istenen değeri yerine yazdığımızda istenen sonuç elde edilecektir. s'=(70-50)/(130-50)=0.25
Doğru cevap E şıkkıdır.
Soru 39
[0,1] kapalı aralığında benzerlik değeri 0.60 olarak hesaplanmış bir nesnenin uzaklığı değeri kaçtır?
Seçenekler
A
0.60
B
0.50
C
1
D
0.40
E
0
Açıklama:
Benzerlik değerlerinin [0,1] sonlu aralığında olduğu ilk durumda, ilgili uzaklık değerleri,
d = 1 -s
eşitliği yardımıyla elde edilebilir.
d=1-0.60=0.40
Doğru cevap D şıkkıdır.
d = 1 -s
eşitliği yardımıyla elde edilebilir.
d=1-0.60=0.40
Doğru cevap D şıkkıdır.
Soru 40
Aşağıdakilerden hangisi benzerlik kavramıyla ilgili doğru değildir?
Seçenekler
A
Benzeyen nesne çiftleri için yüksektir.
B
Genelde [0,1] arasında ölçeklendirilir.
C
[-1,1] arasında sayısal ifade edilir.
D
0 değeri nesnelerin özdeşliğini gösterir.
E
Nesnelerin benzerlik uzaklığıdır.
Açıklama:
Genel bir tanımı olmamasına rağmen, iki nesne arasındaki benzerlik, iki nesnenin bir- birine benzeme derecesinin sayısal bir ölçüsü olarak tanımlanabilir. Veri madenciliği çerçevesinde ise benzerlik genellikle nesnelerin özelliklerini temsil eden boyutlara sahip bir uzaklık olarak tanımlanabilir. Dolayısıyla, benzerlikler birbirine daha çok benzeyen nesne çi leri için daha yüksektir. Benzerlikler temel olarak [-1,1] arasında bir sayısal değer ile ifade edilebilmelerine rağmen, genellikle normalleştirilerek [0,1] arasında ölçeklendirilirler. Bu durumda “0” nesneler arasında hiç benzerliğin olmadığını, “1” ise ilgili nesnelerin tam benzer olduklarını, bir diğer ifadeyle aynı (özdeş) nesneler olduklarını ifade eder.
Soru 41
İki nesnenin birbirinden farklılık derecesinin ölçüsü aşağıdakilerden hangisidir?
Seçenekler
A
Bozukluk
B
Benzerlik
C
Uzaklık
D
Düzensizlik
E
Ayrılık
Açıklama:
İki nesne arasındaki uzaklık ise iki nesnenin birbirinden farklılık derecesinin sayısal bir ölçüsüdür. Çoğunlukla, uzaklık kavramı farklılık kavramının yerine kullanılmasına rağmen aslında uzaklık, farklılıkların özel bir sınıfını ifade etmek için kullanılır. Farklılık, çeşitli özelliklere dayalı olarak iki nesne arasındaki zıtlık ya da uyumsuzlukların bir ölçümü olarak nitelendiğinde, uzaklık iki nesne arasındaki düzensizliğin veya bozukluğun bir ölçüsü olarak düşünülebilir.
Soru 42
Aşağıdakilerden hangisi uzaklık tanımını aktarmaktadır?
Seçenekler
A
s(x,y)
B
1 - s(x,y)
C
1 + s(x,y)
D
(x,y)<1
E
s(x,y) = 1
Açıklama:
İki nesne arasındaki benzerlik s(x, y) olarak tanımlandığın- da, ilgili iki nesne arasındaki uzaklık d(x, y) = 1 - s(x, y) olarak tanımlanır. Hesaplamalar sonucunda elde edilen benzerlik değeri arttıkça iki nesne arasındaki benzerliğin de arttığı anlaşılırken bunun tam tersine elde edilen uzaklık değeri azaldıkça bu iki nesne arasındaki benzerliğin arttığı anlaşılmaktadır.
Soru 43
Nesneler arasında 1 hiç benzerliğin olmadığını, 100 ise tam benzerliğin olduğunu göstermek üzere elde edilmiş olan 30 benzerlik değerinin [0,1] aralığına düşecek şekilde dönüşüm yapılmış karşılığı hangisidir?
Seçenekler
A
0,44
B
0,29
C
0,35
D
0,17
E
0,56
Açıklama:
Birçok veri madenciliği uygulamasında özellikle benzerlik ölçüm değerlerinin [0,1] aralığında tanımlanmış veya bu aralıktaki değerlere dönüştürülmüş olması beklenir. Sonlu bir aralıkta değerler alan benzerlik ölçüm değerleri [0,1] aralığına uyacak şekilde dönüştürülmek istendiğinde, şu eşitlikten yararlanılır:
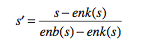
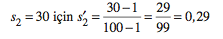
Soru 44
Aşağıdaki eşitliklerden hangisi sonlu aralıkta olmayan yakınlık ölçüm değerlerini dönüştürmek için kullanılır?
Seçenekler
A
B 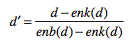
C 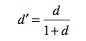
D 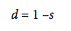
E 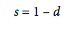
Açıklama:
Yakınlık ölçüm değerleri her zaman sonlu aralıkta olmayabilir. Yakınlık ölçüm değerleri genellikle matematiksel olarak [0,∞) aralığında değerler almaktadırlar. Bu durumda yakınlık ölçüm değerlerini [0,1] sonlu aralığında ifade etmek için doğrusal olmayan bir dönüşüm uygulanır. Örnek olarak [0,∞) aralığında değerler alan bir uzaklık ölçümü için, şu eşitlik yardımıyla ölçüm değerleri [0,1] sonlu aralığına dönüştürülmüş olur:
Soru 45
Belge ve metin madenciliğinde kullanılan benzerlik ölçüsü aşağıdakilerden hangisidir?
Seçenekler
A
Pearson Korelasyon
B
Minkowski uzaklığı
C
City-Block uzaklığı
D
Mahalanobis
E
Açısal benzerlik
Açıklama:
Açısal benzerlik, iki vektör arasındaki açı farkının kosinüsünün bu iki vektör arasındaki uzaklık olarak alınması suretiyle değişkenler arasındaki benzerliğin belirlenmesine yönelik bir benzerlik ölçüsüdür. İki vektör arasındaki açı farkı sıfır olduğunda yani vektörler birbirlerine paralel olduklarında kosinüs değeri 1 olurken bu iki vektör arasındaki açı farkı 90° olduğunda yani vektörler birbirlerine dik olduklarında kosinüs değeri 0 olur. Dolayısıyla elde edilen değerin 1 olması değişkenler arasında tam bir benzerliğin olduğunun, 0 olması ise değişkenlerin hiç benzerliğin olmadığının göstergesi olmaktadır.
Açısal benzerlik, özellikle belge ve çoklu ortam nesnelerinin kıyaslanmasında ve metin madenciliğinde kullanılmaktadır.
Açısal benzerlik, özellikle belge ve çoklu ortam nesnelerinin kıyaslanmasında ve metin madenciliğinde kullanılmaktadır.
Soru 46
Aşağıdakilerden hangisi iki sonuçlu değişkenler içeren gözlem çiftleri arasındaki yakınlığın belirlenmesinde kullanılan yakınlık ölçülerinden biri değildir?
Seçenekler
A
Öklid
B
Açısal benzerlik
C
Karesel Öklid
D
Büyüklük Farkı
E
Örüntü Farkı
Açıklama:
İki sonuçlu (binary) değişkenler, ölçüm değerleri sınıflama yoluyla elde edilen nitel değişkenlerdir. Bu değişkenler sadece evet/hayır, var/yok, erkek/kadın, doğru/yanlış gibi değerler alırlar. İki sonuçlu değişkenler için benzerlik veya uzaklık ölçüm değerlerin hesaplanabilmesi için her bir nesne incelenen değişkenlere ilişkin aldığı değerlerden oluşan bir vektör şeklinde ifade edilir. İki sonuçlu değişkenler içeren gözlem çi leri arasındaki yakınlığın belirlenmesinde Öklid, Karesel Öklid, Büyüklük Farkı (Size Difference), Örüntü Farkı (Pattern Difference), Lance ve Williams Uzaklık Ölçüsü, Biçim Farkı (Shape Difference) ve Jaccard Benzerliği (Jaccard Similarity) gibi birçok benzerlik ya da uzaklık ölçülerinden yararlanılmaktadır.
Soru 47
R yazılımında vegan paketi içerisinde vegdist() fonksiyonu hangi uzaklığı hesaplamak için kullanılmaktadır?
Seçenekler
A
Manhattan uzaklığı
B
Minkowski uzaklığı
C
Korelasyon uzaklığı
D
Jaccard uzaklığı
E
Karl Pearson uzaklığı
Açıklama:
R ile Jaccard uzaklığı değerini hesaplayabilmek için vegan paketi içerisinde yer alan vegdist() fonksiyonundan yararlanılır. Jaccard benzerlik katsayısı özellikle ekolojik araştırmalarda belirli bir nesnenin farklı bölgelerde var olup olmadığının belirlenmesinde kullanılmaktadır. İki nesnenin de araştırma bölgesi sınırları içerisinde var olmaması (0-0) durumu gözlem değeri sayısının (a’nın) göz ardı edildiği durumları dikkate alarak hesaplanan bir benzerlik ölçüsüdür.
Soru 48
Aşağıdakilerden hangisi Pearson korelasyon katsayısı ile ilgili doğru değildir?
Seçenekler
A
Değişken gözlem sayıları farklı olmalıdır.
B
Gözlem değerleri arasında benzerlik ölçüsüdür.
C
Doğrusal ilişki katsayısı olarak bilinir.
D
İlişki derecesini ve yönünü beliler.
E
r sembolü ile gösterilir.
Açıklama:
Doğrusal ilişki katsayısı olarak da bilinen Pearson korelasyon katsayısı, iki veya daha fazla ve en az aralıklı ölçeğe uygun şekilde ölçümlenmiş n adet gözlem içeren değişkenler arasındaki doğrusal ilişkinin yönünün ve derecesinin belirlenmesinde kullanılan bir katsayıdır ve r sembolü ile gösterilir. Aynı zamanda Pearson korelasyon katsayısı iki değişkenin gözlem değerleri arasındaki benzerliğin de bir ölçüsüdür. Korelasyon katsayısının hesaplanabilmesi için değişkenlerin gözlem sayılarının eşit olması gerekmektedir.
Soru 49
Lλ norm olarak bilinen uzaklık ölçüsü aşağıdakilerden hangisidir?
Seçenekler
A
Karesel Öklid uzaklığı
B
Karl Pearson uzaklığı
C
Binary Öklid uzaklığı
D
Minkowski uzaklığı
E
Manhattan uzaklığı
Açıklama:
n sayıda birim ve p sayıda değişken ile çalışılırken birimler yada değişkenler arasındaki uzaklıkları hesaplamak için kullanılan genel bir uzaklık ölçüsüdür. Lλ norm olarak da bilinir. Minkowski uzaklık ölçüsündeki λ değeri büyük ve küçük farklara verilen ağırlığı değiştirir. Farklı λ değerleri için farklı uzaklık ölçüleri elde edile- bileceği için genel uzaklık ölçüsü olarak nitelendirilir.
Soru 50
Veri madenciliği çerçevesinde genellikle nesnelerin özelliklerini temsil eden boyutlara sahip olan uzaklığa ne denir?
Seçenekler
A
Uzaklık
B
Özdeşlik
C
Benzerlik
D
Eşitlik
E
Karşılaştırma
Açıklama:
Veri madenciliği çerçevesinde benzerlik, genellikle nesnelerin özelliklerini temsil eden boyutlara sahip bir uzaklık olarak tanımlanabilir.
Soru 51
Veri madenciliği çerçevesinde iki nesnenin birbirinden farklılık derecesinin sayısal ölçüsü nedir?
Seçenekler
A
Uzaklık
B
Benzerlik
C
Dengesizlik
D
Zıtlık
E
Ardışıklık
Açıklama:
Veri madenciliği çerçevesinde iki nesne arasındaki uzaklık; iki nesnenin birbirinden farklılık derecesinin sayısal bir ölçüsüdür.
Soru 52
İki nesne arasındaki yüksek uzaklık değeri neyi ifade eder?
Seçenekler
A
Yüksek benzerlik değerini
B
Nesnelerin aynı olduklarını
C
Nesnelerin benzer olduklarını
D
Nesnelerin benzer olmadıklarını
E
Nesnelerin aynı olmadıklarını
Açıklama:
İki nesne arasındaki yüksek benzerlik değeri nesnelerin benzer olduklarını, yüksek uzaklık değeri ise nesnelerin benzer olmadıklarını ifade eder.
Soru 53
Genellikle benzerlik ve uzaklıklara ilişkin ölçüm değerlerinin birbirlerine dönüştürülmesinde veya her ikisi için farklı aralıklarda elde edilmiş ölçüm değerlerinin [0,1] gibi belirli bir aralık içerisinde ölçeklendirilmesi amacıyla kullanılan kavram seçeneklerden hangisidir?
Seçenekler
A
Uzaklıklar
B
Benzerlikler
C
Değişimler
D
Dönüşümler
E
Yakınlıklar
Açıklama:
Dönüşümler genellikle benzerlik ve uzaklıklara ilişkin ölçüm değerlerinin birbirlerine dönüştürülmesinde veya her ikisi için farklı aralıklarda elde edilmiş ölçüm değerlerinin [0,1] gibi belirli bir aralık içerisinde ölçeklendirilmesi amacıyla kullanılırlar.
Soru 54
Seçeneklerden hangisi yanlıştır?
Seçenekler
A
Veri madenciliğinde benzerlik ölçüm değerlerinin [0,1] aralığında tanımlanmış olması gerekir
B
Yakınlık ölçüm değerleri her zaman sonlu aralıkta olmayabilir
C
Yakınlık ölçüm değerleri her zaman sonlu aralıkta olur
D
Benzerlik ve uzaklık değerlerinin birbirlerine dönüşümü için herhangi bir monoton azalan fonksiyon da kullanılabilir
E
Benzerlik ve uzaklık değerlerinin birbirlerine dönüşümü sırasında probleme özgü diğer faktörlerin de göz önünde bulundurulmalıdır.
Açıklama:
Yakınlık ölçüm değerleri her zaman sonlu aralıkta olmayabilir. Hatırlanacağı gibi yakınlık ölçüm değerleri genellikle matematiksel olarak [0,∞) aralığında değerler almaktadırlar. Bu durumda yakınlık ölçüm değerlerini [0,1] sonlu aralığında ifade etmek için doğrusal olmayan bir dönüşüm uygulanır.
Soru 55
Bir dizi niteliğe sahip nesnelerin yakınlığı nasıl tanımlanır?
Seçenekler
A
Nesnelerin her bir niteliği için elde edilecek yakınlıklarının karşılaştırması
B
Nesnelerin her bir niteliği için elde edilecek yakınlıklarının birleşimi
C
Nesnelerin her bir niteliği için elde edilecek yakınlıklarının kıyaslaması
D
Nesnelerin her bir niteliği için elde edilecek yakınlıklarının değerlendirilmesi
E
Nesnelerin her bir niteliği için elde edilecek yakınlıklarının analizi
Açıklama:
Bir dizi niteliğe sahip nesnelerin yakınlığı, nesnelerin her bir niteliği için elde edilecek yakınlıklarının birleşimi olarak tanımlanır.
Soru 56
Nitelendirilen iki ürünün benzerliklerini ölçmek için ilk olarak niteliğin her bir sonucuna 0 veya 1’den başlamak suretiyle {örneğin; kötü = 0, zayıf = 1, orta = 2, iyi = 3, mükemmel = 4} şeklinde tamsayı değerler atanması hangi karşılaştırmaya örnektir?
Seçenekler
A
Kademeli karşılaştırma
B
Aşamalı karşılaştırma
C
Düzenleyici nitelik bakımından karşılaştırma
D
Özdeşlik bakımından karşılaştırma
E
Sıralayıcı nitelik bakımından karşılaştırma
Açıklama:
Sıralayıcı nitelik bakımından iki nesne karşılaştırıldığında durum karmaşıklaşır. Örneğin bir araştırmada üretilen bir ürünün kalitesinin {kötü, zayıf, orta, iyi, mükemmel} olarak değerlendirildiğini varsayalım. Bu şekilde nitelendirilen iki ürünün benzerliklerini ölçmek için ilk olarak niteliğin her bir sonucuna 0 veya 1’den başlamak suretiyle {kötü = 0, zayıf = 1, orta = 2, iyi = 3, mükemmel = 4} şeklinde tamsayı değerler atanır.
Soru 57
Aralıklı veya oransal ölçekle ölçümlenmiş bir nitelik bakımından iki nesne arasındaki uzaklık ölçüm değeri belirlenmek istendiğinde ne yapılmalıdır?
Seçenekler
A
Ölçüm değerlerinin farklarının alınması
B
Ölçüm değerlerinin mutlak farklarının alınması
C
Ölçüm değerlerinin kıyaslanması
D
Ölçüm değerlerinin sayısal veriye dönüştürülmesi
E
Ölçüm değerlerinin kıyaslanması
Açıklama:
Aralıklı veya oransal ölçekle ölçümlenmiş bir nitelik bakımından iki nesne arasındaki uzaklık ölçüm değeri belirlenmek istendiğinde ise ölçüm değerlerinin mutlak farklarının alınması gerekmektedir.
Soru 58
Seçeneklerden hangisi değişkenlere ilişkin ölçüm değerlerinin, matematiksel özelliklerine göre belirlenmiş ölçeklerinden biri değildir?
Seçenekler
A
Sınıflayıcı
B
Sıralayıcı
C
Aralıklı
D
Oransal
E
Sayısal
Açıklama:
Yakınlık ölçüleri, temel olarak ilgilenilen değişkenlerin nicel (sayısal) veya nitel (kategorik) olmasına göre farklılık gösterir. Değişkenlerin bu şekilde sınıflandırılmasının nedeni ise, değişkenlere ilişkin ölçüm değerlerinin matematiksel özelliklerine göre sınıflayıcı, sıralayıcı, aralıklı ve oransal olmak üzere dört ölçek ile ölçülmesidir.
Soru 59
Öklid uzaklığının değişkenin varyansına oranlanması ile elde edilen uzaklık seçeneklerden hangisidir?
Seçenekler
A
Karesel Öklid Uzaklığı
B
Manhattan Uzaklığı
C
City-Block Uzaklığı
D
Karl Pearson Uzaklığı
E
Minowski Uzaklığı
Açıklama:
Karl Pearson uzaklığı, Öklid uzaklığının değişkenin varyansına oranlanması ile elde edilen bir uzaklıktır. Bu özelliğinden dolayı standartlaştırılmış Öklid uzaklığı olarak da bilinmektedir.
Soru 60
Aşağıda benzerlik ve uzaklık kavramlarına dair verilen bilgilerden hangisi yanlıştır?
Seçenekler
A
Benzerlikler birbirine daha çok benzeyen nesne çiftleri için daha yüksektir.
B
Benzerlikler genellikle [0,1] arasında ölçeklendirilirler.
C
“1” sayısı ilgili nesnelerin özdeş olduklarını ifade eder.
D
Uzaklık iki nesne arasındaki düzensizliğin veya bozukluğun bir ölçüsüdür.
E
Birbirine benzemeyen nesne çiftleri için uzaklık ölçüsünün alacağı değer küçüktür.
Açıklama:
Benzerlikler birbirine daha çok benzeyen nesne çiftleri için daha yüksektir. Benzerlikler temel olarak [-1,1] arasında bir sayısal değer ile ifade edilebilmelerine rağmen, genellikle normalleştirilerek [0,1] arasında ölçeklendirilirler. Bu durumda “0” nesneler arasında hiç benzerliğin olmadığını, “1” ise ilgili nesnelerin tam benzer olduklarını, bir diğer ifadeyle aynı (özdeş) nesneler olduklarını ifade eder. Uzaklık iki nesne arasındaki düzensizliğin veya bozukluğun bir ölçüsü olarak düşünülebilir. Birbirine benzemeyen nesne çiftleri için farklılıklar fazla ve uzaklık ölçüsünün alacağı değer de o oranda büyüktür.
Soru 61
En büyük değerin 100 ve en küçük değerin 1 olduğu bir problemde hesaplanan 50 benzerlik değerinin [0,1] aralığına düşecek şekilde dönüşüm yapılmış karşılığı aşağıdakilerden hangisidir?
Seçenekler
A
0,29
B
0,44
C
0,49
D
0,50
E
0,52
Açıklama:
formülü ele alındığında 50-1/100-1= 49/99= 0, 49
Soru 62
Bir araştırmada ilgilenilen değişkenin [0,∞) aralığında değerler aldığını varsayalım. Bu araştırmada nesneler arasındaki uzaklık değerleri 20 olarak elde edilmiş olsun. Bu uzaklık değeri [0,1] sonlu aralığında nasıl ifade edilir?
Seçenekler
A
0,82
B
0,85
C
0,90
D
0,91
E
0,95
Açıklama:
Soru 63
Bir fabrikada kakaolu ve sade olmak üzere iki çeşit bisküvi üretilmektedir. Ürünleri lezzet açısından değerlendirmek için {kötü = 0, zayıf = 1, orta = 2, iyi = 3, mükemmel = 4} değerleri kullanılmaktadır. İlgili ürünlerin lezzet açısından elde edilen değerlendirme sonuçlarının sırasıyla mükemmel ve zayıf olarak tespit edildiğini varsaydığımızda bu iki ürün arasındaki uzaklık değeri aşağıdakilerden hangisi olacaktır?
Seçenekler
A
1
B
2
C
3
D
4
E
5
Açıklama:
Soru 64
Aşağıdakilerden hangisi nicel değişkenlerden elde edilen gözlem değerleri arasındaki yakınlığın belirlenmesinde kullanılmaz?
Seçenekler
A
Öklid uzaklığı
B
Karesel Öklid uzaklığı
C
Karl Pearson uzaklığı
D
Manhattan uzaklığı
E
Basit eşleştirme katsayısı ve uzaklığı
Açıklama:
Nicel değişkenlerden elde edilen gözlem değerleri arasındaki yakınlığın belirlenmesinde Öklid uzaklığı, Karesel Öklid uzaklığı, Karl Pearson uzaklığı, Manhattan uzaklığı, Minkowski uzaklığı, Mahalanobis uzaklığı, Korelasyon uzaklığı ve Açısal benzerlik ölçülerinden yararlanılırken; Basit eşleştirme katsayısı ve uzaklığı iki sonuçlu (binary) değişkenler için yakinlik ölçülerindendir.
Soru 65
Pearson korelasyon katsayısı hangi sembol ile gösterilir?
Seçenekler
A
n
B
p
C
s
D
r
E
q
Açıklama:
Pearson korelasyon katsayısı r sembolü ile gösterilir.
Soru 66
Pearson korelasyon katsayısında -1 (eksi bir) değeri değişkenler açısından neyi ifade eder?
Seçenekler
A
İncelenen iki değişken arasında ters yönlü bir ilişki vardır.
B
İncelenen iki değişken arasında aynı yönlü bir ilişki vardır.
C
İncelenen iki değişken arasında ilişki tam değildir.
D
İncelenen iki değişken arasında ilişki yoktur.
E
İncelenen iki değişken arasında mükemmel bir ilişki yoktur.
Açıklama:
-1 ve +1 değerleri incelenen iki değişken arasında tam/mükemmel bir ilişkiyi ifade ederken, 0 (sıfır) değeri ilgili değişkenler arasında hiç ilişkinin olmadığını ifade eder. Hesaplanacak katsayı değerinin eksi işaretli olması değişkenler arasında ters yönlü bir ilişki olduğunun, artı işaretli olması ise değişkenler arasında aynı yönlü bir ilişki olduğunun göstergesidir.
Soru 67
I. Evet/Hayır
II. Erkek/Kadın
III. Doğru/Yanlış
IV. İyi/Kötü
V. Açık/Koyu
Yukarıdakilerden hangisi/hangileri iki sonuçlu (binary) değişkenlere örnek olarak verilebilir?
II. Erkek/Kadın
III. Doğru/Yanlış
IV. İyi/Kötü
V. Açık/Koyu
Yukarıdakilerden hangisi/hangileri iki sonuçlu (binary) değişkenlere örnek olarak verilebilir?
Seçenekler
A
I ve II
B
II ve V
C
I, II ve III
D
I, II ve IV
E
I, II, III ve IV
Açıklama:
İki sonuçlu (binary) değişkenler, ölçüm değerleri sınıflama yoluyla elde edilen nitel değişkenlerdir. Bu değişkenler sadece evet/hayır, var/yok, erkek/kadın, doğru/yanlış gibi değerler alırlar.
Soru 68
Soru 9-10’u aşağıda verilen x ve y araçlarının ABS, hız sabitleme, yokuş kalkış desteği, otomatik silecek özelliklerinin var olup olmama durumuna göre var(+) / yok(-) değerlendirildiği tabloya göre cevaplayınız.
Bu iki araca ilişkin basit eşleştirme katsayısı aşağıdakilerden hangisidir?
Bu iki araca ilişkin basit eşleştirme katsayısı aşağıdakilerden hangisidir?
Seçenekler
A
0,15
B
0,25
C
0,50
D
0,75
E
0,90
Açıklama:
Soru 69
Bu iki araca ilişkin basit eşleştirme uzaklığı aşağıdakilerden hangisidir?
Seçenekler
A
0,15
B
0,25
C
0,50
D
0,75
E
0,90
Açıklama:
Soru 70
0-1 aralığına ölçeklendirilmiş bir benzerlik araştırmasında iki nesne arasındaki benzerlik sıfır ise seçeneklerden hangisi söylenir?
Seçenekler
A
korelasyon 1'dir
B
Korelasyon -0.75'tir
C
Özdeş nesnelerdir.
D
Özdeşe yakın nesnelerdir
E
Benzerlik yoktur
Açıklama:
Benzerlikler birbirine daha çok benzeyen nesne çiftleri için daha yüksektir. Benzerlikler temel olarak [-1,1] arasında bir sayısal değer ile ifade edilebilmelerine rağmen, genellikle normalleştirilerek [0,1] arasında ölçeklendirilirler. Bu durumda “0” nesneler arasında hiç benzerliğin olmadığını, “1” ise ilgili nesnelerin tam benzer olduklarını, bir diğer ifadeyle aynı (özdeş) nesneler olduklarını ifade eder.
Soru 71
Benzerlik ölçülerine göre iki nesne özdeş ise benzerlik değeri kaç olur?
Seçenekler
A
-7
B
-0.5
C
0.59
D
1
E
6
Açıklama:
Benzerlikler birbirine daha çok benzeyen nesne çiftleri için daha yüksektir. Benzerlikler temel olarak [-1,1] arasında bir sayısal değer ile ifade edilebilmelerine rağmen, genellikle normalleştirilerek [0,1] arasında ölçeklendirilirler. Bu durumda “0” nesneler arasında hiç benzerliğin olmadığını, “1” ise ilgili nesnelerin tam benzer olduklarını, bir diğer ifadeyle aynı (özdeş) nesneler olduklarını ifade eder.
Soru 72
Uzaklık için tanımlanan d(x,y)≥ 0 koşulu neyi ifade eder?
Seçenekler
A
Özdeşlik
B
Bağımsızlık
C
Negatif olmama
D
Simetri
E
Üçgen eşitsizliği
Açıklama:

Soru 73
Uzaklık için tanımlanan d(x,y)=0 koşulu neyi ifade eder?
Seçenekler
A
özdeşlik
B
Simetri
C
Üçgen
D
Negatif olma
E
Varyans
Açıklama:
Soru 74
Benzerlik konusu ele alındığında s(x,y)=s(y,x) durumuna ne ad verilir?
Seçenekler
A
Maksimum benzerlik
B
Simetri
C
Üçgensellik
D
Negatiflik
E
Özdeşlik
Açıklama:

Soru 75
Bir çalışmada sonlu aralıkta değerler alan değişken ölçüm değerleri [0,1] aralığına uyacak şekilde dönüştürülmek istenmektedir. İlgili gözlem değeri 45, değişken için en küçük değer 15 ve en büyük değer 95 ise bu gözlem değerinin dönüştürülmüş değeri nedir?
Seçenekler
A
-0.45
B
0
C
0.25
D
0.375
E
0.90
Açıklama:
s= (45-15)/(95-15)=30/80=0.375
Soru 76
[0,∞) aralığında değerler alan bir uzaklık ölçümü için, gözlemlenen değer 22 ise dönüştürülmüş değer nedir?
Seçenekler
A
0,4535
B
0,9565
C
0,3495
D
0,8565
E
0,6743
Açıklama:
d'=22/(1+22)=0.9565
Soru 77
[0,∞) aralığında değerler alan bir uzaklık ölçümü için, gözlemlenen değer 3 ise dönüştürülmüş değer nedir?
Seçenekler
A
0,25
B
0,35
C
0,55
D
0,75
E
1
Açıklama:
d'=3/(3+1)
Soru 78
Benzerlik değerlerinin [0,1] sonlu aralığında olduğu durumda, s=0,45 ise ilgili uzaklık değeri nedir?
Seçenekler
A
0
B
0,35
C
0,55
D
0,65
E
0,85
Açıklama:
d=1-0,45=0,55
Soru 79
[0,1] kapalı aralığındaki uzaklık değerlerine karşı gelen benzerlik değerleri elde edilmek istendiğinde uzaklık değeri d=0,12 ise benzerlik değeri nedir?
Seçenekler
A
0,25
B
0,68
C
0,62
D
0,98
E
0,88
Açıklama:
s=1-0,12=0,88
Soru 80
Veri madenciliği uygulamalarında dönüşümlerden faydalanılmasının nedeni aşağıdakilerden hangisidir?
Seçenekler
A
Veriyi aşırı uç değerlerden temizlemek
B
Değişkenleri aynı ölçüm aralığına getirmek
C
Bağımlı değişkeni standardize etmek
D
Veriyi daha anlaşılabilir kılmak
E
Veriyi özetlemek
Açıklama:
Değişkenleri biribirine yakınlık-uzaklıklarına göre benzer-farklı olma durumunu ortaya koyma amacıyla yapılan analizlerde, değişkenlerin farklı ölçek düzeylerin olması (farklı ranjda değerler almaları) analiz sonuçlarında yanlılığa neden olur. Bu nedenle değişkenler aynı ölçek düzeyine getirilir; aldıkları değerler aynı aralıkta olacak biçimde dönüşüm yapılır.
Soru 81
Aralarındaki uzaklığı belirlemek amacıyla iki değişkenin aldığı değerler arasındaki farkın mutlak değerce hesaplanması, hangi ölçek türünde yapılır?
Seçenekler
A
Sınıflama
B
Sıralama
C
Aralık ya da oran
D
Kategorik
E
Dereceleme
Açıklama:
Aralık ve oran ölçeğindeki değişkenler arasındaki uzaklık, aralarındaki matematiksel farkın mutlak değerce karşılığıdır.
Soru 82
Uzaklık ölçüleri arasında en çok kullanılanı aşağıdakilerden hangisidir?
Seçenekler
A
Öklid
B
Pearson
C
Mahalanobis
D
Manhattan
E
Minkowski
Açıklama:
Öklid, en çok kullanılan uzaklık ölçüsüdür.
Soru 83
Öklid ile karesel öklid uzaklığı arasındaki fark nedir?
Seçenekler
A
Sadece birinde standartlaştırılmış değerlerden faydalanılması
B
Sadece birinin aldığı değerler 0 ile +ꚙ arasında olması
C
Sadece birinde elde edilen değerin karekökünün alınması
D
Birisinde uzaklık farkına, diğerinde toplamına bakılması
E
Birinin sınıflama, diğerinin ise aralık ölçeğindeki değişkenler için kullanılması
Açıklama:
Karesel öklid hesaplanırken, farkların karesi alındıktan sonra tekrar karekök alınmaz.
Soru 84
Uzaklıkları hesaplanacak değişkenlerin ölçü birimleri birbirinden farklı olduğunda hangi ölçü birimi tercih edilmelidir?
Seçenekler
A
Öklid
B
Manhattan
C
Mahalanobis
D
Karl Pearson
E
Minkowski
Açıklama:
Değişkenlerin ölçü birimleri birbirinden farklı olduğunda, noktalar arasındaki farkın değişkenin varyansına bölünmesiyle elde edilen Karl Pearson yöntemi kullanılır.
Soru 85
Birimler arası farkların mutlak değerini alarak hesaplanan uzaklık ölçüsü nedir?
Seçenekler
A
Manhattan
B
Mahalanobis
C
Öklid
D
Pearson
E
Minkowski
Açıklama:
Manhattan uzaklığı, farkların mutlak değeri alınarak hesaplanır.
Soru 86
Aralarındaki korelasyon 0.25 olan iki değişken için korelasyon uzaklığı nedir?
Seçenekler
A
0.12
B
0.20
C
0.28
D
0.38
E
0.50
Açıklama:
Korelasyon uzaklığı, (1-rxy)/2 formülüyle elde edilir. Buna göre:
(1-0.25)/2 = 0.38'dir.
(1-0.25)/2 = 0.38'dir.
Soru 87
Açısal benzerlik için R'de kullanılan lsa paketindeki fonksiyon nedir?
Seçenekler
A
cosine()
B
cor()
C
dist()
D
mahalanobis()
E
smc()
Açıklama:
Açısal benzerlik için cosine() fonksiyonu kullanılır.
Soru 88
 Tablodaki değerlere göre, değişkenlerin binary öklid uzaklıkları nedir?
Tablodaki değerlere göre, değişkenlerin binary öklid uzaklıkları nedir?Seçenekler
A
0.25
B
0.50
C
0.75
D
0.90
E
0.95
Açıklama:
Tabloda, uyuşmayan değerler olan 1 ve 8 toplanarak bu değerin kare kökü alınır. Sonrasında bu değer, 1 ile toplanmış değerine bölünerek (3/(1+3)) = 0.75 olarak bulunur.
Soru 89
Özellikle ekolojik çalışmalarda kullanılan katsayı aşağıdakilerden hangisidir?
Seçenekler
A
Öklid
B
Mahalanobis
C
Jaccard
D
Manhattan
E
Açısal Benzerlik
Açıklama:
Doğru seçenek, Jaccard benzerlik katsayısıdır.
Ünite 5
Soru 1
Aşağıdakilerden hangisinin belirlenmesinde, pazar sepeti analiz’inin çıktıları rol oynamaz?
Seçenekler
A
Müşterilerin kişisel tercihlerinin belirlenmesi
B
Birlikte satışa sunulacak ürünlerin belirlenmesi
C
Ürün satış raflarının düzenlenmesi
D
Promosyon ürünlerin belirlenmesi
E
Ürün fiyatlarının belirlenmesi
Açıklama:
Pazar sepeti analizi, müşterilerin daha önceden yapmış oldukları alışverişlerinden oluşan veritabanından her bir alışverişinde birlikte almış olduğu ürünler arasındaki ilişkilerden yola çıkılarak müşterilerin alışveriş alışkanlıklarının belirlenmesidir. Bu sayede müşterilerin kişisel tercihlerinin belirlenmesi, birlikte satışa sunulacak ürünlerin belirlenmesi, ürün satış raflarının tasarlanması ve promosyon düzenlemeleri gibi satışı artırmaya yönelik çalışmalar daha doğru bir şekilde yapılabilmektedir.
Soru 2
Bir ilişki kuralında, destek ve güven değerleri ile O ilişki kuralına ilişkin ne ölçümlenebilir?
Seçenekler
A
Nesneler Kümesi
B
İlginç ilişki kuralı
C
İlişki kuralının gücü
D
Nesne Seti
E
Nesne Veri Tabanı
Açıklama:
Bir ilişki kuralının gücü, o kural için hesaplanacak destek ve güven değerleri ile ölçümlenebilir.
Soru 3
A⇒B şeklindeki bir ilişki kuralında güven değeri, P(B│A)koşullu olasılığı neyi ifade eder?
Seçenekler
A
A bilindiğinde B’nin ortaya çıkma olasılığını
B
A küme sayısının B küme sayısına oranını
C
A ve B ilişki kuralının güven değerini
D
A⇒B ilişki kuralının küme elemanlarını
E
B ve A ilişki kuralının güven değerini
Açıklama:
A⇒B şeklindeki bir ilişki kuralının güven değeri, aslında A’yı içeren işlemlerin aynı zamanda B’yi de içerme olasılığıdır yani P(B│A)koşullu olasılığıdır. Yani A bilindiğinde B’nin ortaya çıkma olasılığıdır
Soru 4
m = 6 adet nesne içeren bir I = {a, b, c, d, e, f} nesneler kümesinden ilişki kuralı oluşturmada kaç farklı nesne kümesi kullanılabilir?
Seçenekler
A
60
B
61
C
62
D
63
E
64
Açıklama:
Boş küme ilişki kuralı oluşturmada kullanılamayacağından sorunun cevabı 26 - 1: 63 'tür. Doğru cevap D.
Soru 5
m=7 adet nesne içeren bir nesneler kümesinden k=3 içeren nesne kümelerinin sayısı kaçtır?
Seçenekler
A
30
B
35
C
45
D
55
E
70
Açıklama:
M adet nesneler kümesinden k tane nesne içeren küme sayısı yani 7 adet nesne kümesinin 3 tane nesnelerolarak karşımıza çıkar. Dolayısıyla formülü kullandığımızda formülasyonundan sonucu 35 olarak elde ederiz. Formül: P(m,k)= (m!)/[(m-k)!.k!]
F(7,3)= (7!)/[(7-3)!.3!]
=(7.6.5.4!)/ (4!.3.2)
= 35
Soru 6
m=3 içeren bir nesneler kümesinden kaç tane ilişki kuralı oluşturulabilir?
Seçenekler
A
11
B
12
C
13
D
14
E
18
Açıklama:
M adet nesne içeren bir I nesneler kümesinden toplamda 3m-2m+1+1 adet ilişki kuralı oluşturulabilir. Bu soruda 33 - 23+1 + 1=12 sonucuna ulaşılır.
Soru 7
Bir alışveriş veritabanından oluşturulacak ilişki kuralları içerisinden işe yarayacak bilgiyi üretmek amacıyla kullanılacak ilişki kuralına ne denir?
Seçenekler
A
Destek ölçütü kuralı
B
Güven ölçütü kuralı
C
İlk ölçüt kuralı
D
İlginç kural
E
Sonuç kural
Açıklama:
Bir alışveriş veritabanından oluşturulacak ilişki kuralları arasından işe yarayacak bilgiyi üretmek amacıyla kullanılacak ilişki kuralı ilginç kural olarak tanımlanabilir.
Soru 8
Hesaplanan bir kaldıraç değerinin (A⇒B) = 0,70 olması durumunda aşağıdaki yorumlardan hangisi yapılabilir?
Seçenekler
A
A ve B nesneleri arasındaki ilişkinin negatif olduğu
B
A ve B nesneleri arasındaki ilişkinin zayıf olduğu
C
A ve B nesneleri arasında bir ilişkinin olmadığı
D
A ve B nesneleri arasındaki ilişkinin güçlü olduğu
E
A ve B nesneleri arasındaki ilişkinin pozitif olduğu
Açıklama:
Kaldıraç değerinin (A⇒B) < 1 olması, A ve B nesne setleri arasında negatif bir ilişki olduğunu ifade eder.
Soru 9
I = {a, b, c, d, e} şeklinde verilen beş nesne kümesi için {c} ve {c, d} sık görülen kümeler değil ise ve destek bazlı budama özelliğine göre bu nesne kümesi için ilişki kuralı oluşturulduğunda aşağıdakilerden hangisi bu nesne setinde değerlendirme dışında bırakılmaz?
Seçenekler
A
{a, b, c}
B
{a, b, c, d}
C
{b, c, d, e}
D
{a, d, e}
E
{a, c, d, e}
Açıklama:
M = 5 adet nesne içeren bir I={a, b, c, d, e} nesneler kümesinden ilişki kuralı oluşturmada kullanılacak nesne seti sayısı 2m-1=32-1=31 tanedir.
Tüm bu 31 nesne seti içerisinden {c} ve {c, d} nesne setlerinin sık görülen nesne setleri olmadığı bilindiğine göre destek bazlı budama özelliğine göre bu 31 nesne seti içerisinden de {c} nesnesini içeren nesne setleri ve {c, d} nesnelerini içeren nesne setleri budanır ve değerlendirme dışı bırakılır. Dolayısıyla bu durumda {a, d, e} nesne seti {c} ve {c, d} nesne setlerinden birini içermediği için nesne seti olarak kalır.
Tüm bu 31 nesne seti içerisinden {c} ve {c, d} nesne setlerinin sık görülen nesne setleri olmadığı bilindiğine göre destek bazlı budama özelliğine göre bu 31 nesne seti içerisinden de {c} nesnesini içeren nesne setleri ve {c, d} nesnelerini içeren nesne setleri budanır ve değerlendirme dışı bırakılır. Dolayısıyla bu durumda {a, d, e} nesne seti {c} ve {c, d} nesne setlerinden birini içermediği için nesne seti olarak kalır.
Soru 10
Destek ({Pirinç, Barbunya}⇒{Turşu})=0,60 olarak hesaplanmış ise aşağıdakilerden hangisi doğrudur?
Seçenekler
A
Pirinç ve barbunya alanlar %40 olasılıkla turşu da alırlar.
B
Pirinç ve barbunya alanlar beraberinde turşu da almışlardır.
C
Pirinç ve barbunya alanların %60’ı turşu da almıştır.
D
Pirinç ve barbunyanın birlikte alındığı alışverişlerin %60’ında turşu da alınmıştır.
E
Pirinç ve barbunya alma olasılığı, sadece turşu alma olasılığından %60 daha fazladır.
Açıklama:
Bir A nesne setinin destek değeri, A nesne setindeki nesnelerin veritabanındaki işlemler içerisindeki bulunma olasılığını ifade eder ve P (A) şeklinde gösterilir. Destek değeri [0,1] aralığında değer alır ve yüzde olarak yorumlanır. Elde edilen destek değeri alışverişlerin yüzde kaçında söz konusu nesnelerin birlikte alınmış olduğunu ifade eder. Bu soruda ise pirinç ve barbunya alanların %60’ının turşu da aldığı yorumu yapılabilir.
Soru 11
Büyük veri kümeleri içerisinde belirli veriler arasındaki ilişkileri bulan ve olayların birlikte gerçekleşme ihtimallerini geçmiş verileri analiz edip ortaya koyarak geleceğe yönelik çalışmaları destekleyen veri madenciliği yöntemi aşağıdakilerden hangisidir?
Seçenekler
A
İlişki kuralları
B
Karar ağaçları
C
Kümeleme analizi
D
Sosyal medya madenciliği
E
Benzerlik ve uzaklık ölçüleri
Açıklama:
İlişki kuralları, veri madenciliğinin tanımlayıcı modellerinden birisidir. Büyük veri kümeleri içerisinde belirli veriler arasındaki ilişkileri bulan ve olayların birlikte gerçekleşme ihtimallerini geçmiş verileri analiz edip ortaya koyarak geleceğe yönelik çalışmaları destekleyen veri madenciliği yöntemine ilişki kuralları denilmektedir. Genel olarak ilişki kuralları sayesinde büyük miktarlardaki veriler arasından ilginç birliktelik örüntüleri keşfedilerek karar verme, pazarlama ve iş yönetimi vb. gibi konularda birçok fayda sağlanmaktadır. İlişki kuralları; ekonomi, eğitim, e-ticaret, pazarlama, iletişim ve sağlık gibi birçok sektörde geniş kullanıma sahip veri madenciliğinin özel bir uygulama alanıdır.
Bu nedenle doğru yanıt a) seçeneğidir.
Bu nedenle doğru yanıt a) seçeneğidir.
Soru 12
Müşterilerin daha önceden yapmış oldukları alışverişlerinden oluşan veritabanından her bir alışverişinde birlikte almış olduğu ürünler arasındaki ilişkilerden yola çıkılarak müşterilerin alışveriş alışkanlıklarının belirlenmesi yöntemi aşağıdakilerden hangisidir?
Seçenekler
A
Pazar sepeti analizi
B
Benzerlik ölçülerini belirleme
C
Uzaklık ölçülerini belirleme
D
Web madenciliği
E
Regresyon ağaçları
Açıklama:
Pazar sepeti analizi, müşterilerin daha önceden yapmış oldukları alışverişlerinden oluşan veritabanından her bir alışverişinde birlikte almış olduğu ürünler arasındaki ilişkilerden yola çıkılarak müşterilerin alışveriş alışkanlıklarının belirlenmesidir. Bu sayede müşterilerin kişisel tercihlerinin belirlenmesi, birlikte satışa sunulacak ürünlerin belirlenmesi, ürün satış raflarının tasarlanması ve promosyon düzenlemeleri gibi satışı artırmaya yönelik çalışmalar daha doğru bir şekilde yapılabilmektedir.
Bu nedenle doğru yanıt a) seçeneğidir.
Bu nedenle doğru yanıt a) seçeneğidir.
Soru 13
Bir alışveriş veritabanından oluşturulacak ilişki kuralları arasından daha önceden keşfedilmemiş ve eyleme dönük, bir başka ifadeyle uygulanabilir işe yarayacak bilgiyi üretmek amacıyla kullanılacak ilişki kuralı aşağıdakilerden hangisidir?
Seçenekler
A
İlginç kural
B
Güçlü kural
C
Güven ölçütü
D
Destek eşik değeri
E
Kaldıraç ölçütü
Açıklama:
İlgilenilen problemde ilişki kurallarını belirlemede kullanılacak nesneler kümesinin eleman sayısı arttıkça bu nesneler aracılığı ile oluşturulacak kural sayısı da katlanarak artmaktadır. Dolayısıyla bu kurallar içerisinden belirli ölçütler kullanmak suretiyle bilgi üretmek amacıyla kullanılmayacak, önemsiz kuralların elenmesi gerekir. Bir alışveriş veritabanından oluşturulacak ilişki kuralları arasından işe yarayacak bilgiyi üretmek amacıyla kullanılacak ilişki kuralı ilginç kural olarak tanımlanabilir. Bir ilişki kuralının ilginç kural olarak değerlendirilebilmesi için,
Bir ilişki kuralının “ilginç”liği, kişiden kişiye değişiklik gösterebilen yani subjektif bir karar olmasına rağmen, bu kararın verilebilmesi için verilerden elde edilebilecek ilişki kurallarının bilimsel veya objektif ölçütler aracılığı ile de elenmesi beklenir. İlginç kuralların belirlenebilmesi amacıyla kullanılan başlıca objektif ölçütler destek ve güven ölçütleridir. İlişki kurallarının elenerek sayılarının azaltılmasında çoğu zaman destek ve güven temel ölçütleri yeterli olmasına karşın bazı durumlarda yapılan eleme sonucunda elde edilen kural sayısı da arzu edilenden fazla olabilir. Bu gibi durumlarda ilave ölçütlere gereksinim duyulur. Bu amaçla geliştirilen birçok ölçüt mevcuttur. Bu ölçütler içerisinde en yaygın kullanılanı öncül ve sonuç nesne setleri arasındaki korelasyonu hesaba katan kaldıraç ölçütüdür.
Bu nedenle doğru yanıt a) seçeneğidir.
- Daha önceden keşfedilmemiş
- Eyleme dönük, bir başka ifadeyle uygulanabilir
Bir ilişki kuralının “ilginç”liği, kişiden kişiye değişiklik gösterebilen yani subjektif bir karar olmasına rağmen, bu kararın verilebilmesi için verilerden elde edilebilecek ilişki kurallarının bilimsel veya objektif ölçütler aracılığı ile de elenmesi beklenir. İlginç kuralların belirlenebilmesi amacıyla kullanılan başlıca objektif ölçütler destek ve güven ölçütleridir. İlişki kurallarının elenerek sayılarının azaltılmasında çoğu zaman destek ve güven temel ölçütleri yeterli olmasına karşın bazı durumlarda yapılan eleme sonucunda elde edilen kural sayısı da arzu edilenden fazla olabilir. Bu gibi durumlarda ilave ölçütlere gereksinim duyulur. Bu amaçla geliştirilen birçok ölçüt mevcuttur. Bu ölçütler içerisinde en yaygın kullanılanı öncül ve sonuç nesne setleri arasındaki korelasyonu hesaba katan kaldıraç ölçütüdür.
Bu nedenle doğru yanıt a) seçeneğidir.
Soru 14
|D|, veritabanındaki tüm işlemlerin sayısını ve |A| ise tüm işlemler içerisinde A nesne setini içeren işlem sayısını ifade ettiğine göre A nesne setinin Destek(A) destek değeri aşağıdaki eşitliklerden hangisi ile hesaplanır?
Seçenekler
A
Destek(A) = | A | / | D |
B
Destek(A) = | D | / | A |
C
Destek(A) = | A | * | D | / | A∪D |
D
Destek(A) = | A | / | A∪D |
E
Destek(A) = |D | / | A∪D |
Açıklama:
Bir A nesne setinin destek değeri, D işlemler veritabanında A nesne setini içeren işlem sayısının veritabanındaki tüm işlemlerin sayısına oranı şeklinde elde edilir ve
Destek(A) = | A |/ | D |
eşitliği yardımıyla hesaplanır. Eşitlikte |A|, tüm işlemler içerisinde A nesne setini içeren işlem sayısını, |D| ise işlemler veritabanındaki tüm işlemlerin sayısını ifade eder. Aslında bir A nesne setinin destek değeri, A nesne setindeki nesnelerin veritabanındaki işlemler içerisindeki bulunma olasığını ifade eder ve P (A) şeklinde gösterilir. Destek değeri [0,1] aralığında değer alır ve yüzde olarak yorumlanır.
Bu nedenle doğru yanıt a) seçeneğidir.
Destek(A) = | A |/ | D |
eşitliği yardımıyla hesaplanır. Eşitlikte |A|, tüm işlemler içerisinde A nesne setini içeren işlem sayısını, |D| ise işlemler veritabanındaki tüm işlemlerin sayısını ifade eder. Aslında bir A nesne setinin destek değeri, A nesne setindeki nesnelerin veritabanındaki işlemler içerisindeki bulunma olasığını ifade eder ve P (A) şeklinde gösterilir. Destek değeri [0,1] aralığında değer alır ve yüzde olarak yorumlanır.
Bu nedenle doğru yanıt a) seçeneğidir.
Soru 15
A⇒B şeklinde ifade edilen bir ilişki kuralının Destek (A⇒B) destek değeri; |A|, tüm işlemler içerisinde A nesne setini içeren işlem sayısını; |D|, işlemler veritabanındaki tüm işlemlerin sayısını; |A∪B|, tüm işlemler içerisinde hem A hem de B nesne setlerini birlikte içeren işlem sayısını ifade ederken, , aşağıdaki eşitliklerden hangisi ile hesaplanır?
Seçenekler
A
Destek(A⇒B)=| A∪B | / | D |
B
Destek(A⇒B)=| D | / | A∪B |
C
Destek(A⇒B)= |A | * | B | / |A∪B|
D
Destek(A⇒B)=| A∪B | / | A | * | B |
E
Destek(A⇒B)=| A∪B | * | D |
Açıklama:
Bir nesne seti için destek değeri hesaplanabileceği gibi, benzer mantıkla A⇒B şeklinde ifade edilen bir ilişki kuralı için de destek değeri hesaplanabilir. Bir ilişki kuralının destek değeri, D işlemler veritabanında A ve B nesne setlerini birlikte içeren işlem sayısının veritabanındaki tüm işlemlerin sayısına oranı şeklinde elde edilir ve
Destek(A⇒B)=|A∪B|/|D|
eşitliği ile hesaplanır. Eşitlikte |A∪B|, tüm işlemler içerisinde hem A hem de B nesne setlerini birlikte içeren işlem sayısını ifade eder. Aslında bir ilişki kuralının destek değeri, o kuralın öncül (A) ve sonuç (B) kısmındaki nesne setlerinin birlikte gözlenme olasılığıdır ve P(A∪B) şeklinde ifade edilir.
Bu nedenle doğru yanıt a) seçeneğidir.
Destek(A⇒B)=|A∪B|/|D|
eşitliği ile hesaplanır. Eşitlikte |A∪B|, tüm işlemler içerisinde hem A hem de B nesne setlerini birlikte içeren işlem sayısını ifade eder. Aslında bir ilişki kuralının destek değeri, o kuralın öncül (A) ve sonuç (B) kısmındaki nesne setlerinin birlikte gözlenme olasılığıdır ve P(A∪B) şeklinde ifade edilir.
Bu nedenle doğru yanıt a) seçeneğidir.
Soru 16
D işlemler veritabanında A ve B nesne setleri içinde karar verici tarafından belirlenmiş olan destek eşik değerine eşit ya da daha büyük destek değerine sahip nesne setleri yani sık görülen nesne setleri ile A⇒B şeklinde oluşturulan bir ilişki kuralının güven değeri aşağıdaki eşitliklerden hangisi ile hesaplanır?
Seçenekler
A
Güven(A ⇒ B) = Destek(A∪ B) / Destek(A)
B
Güven(A ⇒ B) = Destek(A∪ B) / Destek(B)
C
Güven(A ⇒ B) = Destek(A) / Destek(A∪ B)
D
Güven(A ⇒ B) = Destek(B) / Destek(A∪ B)
E
Güven(A ⇒ B) = Destek(A∪ B) * Destek(A)
Açıklama:
İlginç ilişki kuralı elde edebilmek için kullanılan ikinci ölçüt, güven değeridir. Öncelikle karar verici tarafından belirlenmiş olan destek eşik değerine eşit ya da daha büyük destek değerine sahip nesne setleri yani sık görülen nesne setleri ile oluşturulması mümkün tüm ilişki kuralları oluşturulur. Karar verici tarafından belirlenmiş olan güven eşik değerine eşit ya da daha büyük güven değerine sahip ilişki kuralları ilginç kural elde etmek için değerlendirilmeye alınırken, bu değerin altında güven değerine sahip ilişki kuralları ise elenir, değerlendirilmez. Sık görülen nesne setleri ile A⇒B şeklinde oluşturulan bir ilişki kuralı için hesaplanacak güven değeri, D işlemler veritabanında A’yı içeren ve aynı zamanda B’yi de içeren işlemlerin sayısının sadece A’yı içeren işlem sayısına oranıdır. Dolayısıyla A⇒B şeklinde ifade edilen ilişki kuralı için güven değeri,
Güven(A ⇒ B) = Destek(A∪ B) /Destek(A) = | A∪ B |/ | A |
eşitliği yardımıyla hesaplanır. Aslında bir ilişki kuralının güven değeri, o kuralın öncül(A) nesne setinin ortaya çıkması veya gözlenmesi durumunda sonuç (B) nesne seti- nin de ortaya çıkması, gözlenmesi olasılığıdır ve P(B│A) şeklinde gösterilir. Güven değeri [0,1] arasında değer alır ve yüzde olarak yorumlanır
Bu nedenle doğru yanıt a) seçeneğidir.
Güven(A ⇒ B) = Destek(A∪ B) /Destek(A) = | A∪ B |/ | A |
eşitliği yardımıyla hesaplanır. Aslında bir ilişki kuralının güven değeri, o kuralın öncül(A) nesne setinin ortaya çıkması veya gözlenmesi durumunda sonuç (B) nesne seti- nin de ortaya çıkması, gözlenmesi olasılığıdır ve P(B│A) şeklinde gösterilir. Güven değeri [0,1] arasında değer alır ve yüzde olarak yorumlanır
Bu nedenle doğru yanıt a) seçeneğidir.
Soru 17
A⇒B şeklinde ifade edilen bir ilişki kuralı için kaldıraç değeri aşağıdaki eşitliklerden hangisi ile hesaplanır?
Seçenekler
A
Kaldıraç (A⇒ B)= Güven(A⇒ B) / Destek(B)
B
Kaldıraç (A⇒ B)= Güven(A⇒ B) / Destek(A)
C
Kaldıraç (A⇒ B)= Destek(A⇒ B) / Güven(B)
D
Kaldıraç (A⇒ B)= Güven(A⇒ B) * Destek(B)
E
Kaldıraç (A⇒ B)= Destek(A⇒ B) / Destek(B)
Açıklama:
İlişki kuralı oluşturmak için kullanılan algoritmalarının hepsi ilişki kuralı oluşturmada destek ve güven eşik değerlerini kullanır. Belirlenen destek ve güven eşik değerleri, güçlü olmayan birçok kuralın gereksiz yere elde edilmesini engellemesine rağmen, bazı durumlarda değerlendirilmesi gereken güçlü kural sayısı yine de fazla olabilmektedir. Böyle durumlarda ortaya çıkan güçlü kurallar içerisinden bir seçim yapabilmek ya da güçlü kuralları önem sırasına göre sıralamak ve problemin amacına en uygun ilişki kuralını belirleyebilmek için ilave kısıtlamalar kullanmak gerekmektedir. Bunlar içerisinden en çok kullanılan ölçüt ise, öncül(A) ve sonuç(B) nesne setleri arasındaki ilişkinin(korelasyonun) belirlenmesi temeline dayanarak hesaplanan kaldıraç(lift) değeridir. A⇒B şeklinde ifade edilen bir ilişki kuralı için kaldıraç değeri, A ve B nesne setlerinin istatistiksel olarak bağımsız oldukları varsayımı altında, kuralın güven değerinin sonucun (B’nin) destek değerine oranı şeklinde elde edilir ve
Kaldıraç (A⇒ B)= Güven(A⇒ B) / Destek(B) = Destek(A∪ B) / Destek(A) * Destek(B)
eşitliği yardımıyla hesaplanır. Oluşturulan güçlü ilişki kuralının ilginç yani bilgi üretme- de kullanılabilir bir kural olup olmadığının bir ölçüsü olarak hesaplanan kaldıraç değeri [0,∞) arasında değer alır ve yüzde olarak ifade edilir. Hesaplanan kaldıraç değerinin,
Bu nedenle doğru yanıt a) seçeneğidir.
Kaldıraç (A⇒ B)= Güven(A⇒ B) / Destek(B) = Destek(A∪ B) / Destek(A) * Destek(B)
eşitliği yardımıyla hesaplanır. Oluşturulan güçlü ilişki kuralının ilginç yani bilgi üretme- de kullanılabilir bir kural olup olmadığının bir ölçüsü olarak hesaplanan kaldıraç değeri [0,∞) arasında değer alır ve yüzde olarak ifade edilir. Hesaplanan kaldıraç değerinin,
- Kaldıraç (A⇒B)<1 olması, A ve B nesne setleri arasında ters yönlü (negatif) bir ilişki olduğunu,
- Kaldıraç (A⇒B)=1 olması, A ve B nesne setleri arasında ilişki olmadığını
- Kaldıraç (A⇒B)>1 olması, A ve B nesne setleri arasında aynı yönlü (pozitif) bir ilişki olduğunu ifade eder.
Bu nedenle doğru yanıt a) seçeneğidir.
Soru 18
Sık görülen nesne setleri elde etmek için aşağıdaki işlemlerden hangisi uygulanır?
Seçenekler
A
Karar verici tarafından belirlenen destek eşik değerine eşit ya da daha yüksek destek değerine sahip nesne setleri belirlenir.
B
Karar verici tarafından belirlenen destek eşik değerinden daha küçük destek değerine sahip nesne setleri belirlenir.
C
Karar verici tarafından belirlenen güven eşik değerine eşit ya da daha yüksek destek değerine sahip nesne setleri belirlenir.
D
Karar verici tarafından belirlenen güven eşik değerinden daha küçük güven değerine sahip nesne setleri belirlenir.
E
Karar verici tarafından belirlenen kaldıraç değerine eşit ya da daha yüksek kaldıraç değerine sahip nesne setleri belirlenir.
Açıklama:
İlginç ilişki kuralı elde edebilmek için öncelikle nesne setlerinin destek değerleri he- saplanır. Belirlenen destek eşik değerine eşit ya da bu değerin üzerinde destek değerine sahip nesne setleri ilişki kuralları oluşturmada kullanılacak nesne setleridir. Destek eşik değerini geçen ve kural oluşturmada kullanılacak nesne setleri sık görülen nesne setleri (frequent itemset) olarak adlandırılır.
Bu nedenle doğru yanıt a) seçeneğidir.
Bu nedenle doğru yanıt a) seçeneğidir.
Soru 19
“Eğer k nesneden oluşan nesne setleri kümesi en küçük destek kriterini sağlıyorsa, bu kümenin alt kümeleri de en küçük destek kriterini sağlar” özelliği aşağıdakilerden hangisidir?
Seçenekler
A
Apriori özelliği
B
Destek bazlı budama özelliği
C
Kaldıraç kuralı özelliği
D
Sık görülen nesne setleri özelliği
E
Güven eşik değeri özelliği
Açıklama:
İlişki kuralı oluşturabilmek için geliştirilen algoritmalar içerisinde en çok bilinen ve en sık kullanılan algoritmadır. Apriori algoritması, 1994 yılında Agrawal ve Srikant tarafından geliştirilmiştir. Algoritmanın ismi, sık görülen nesne kümelerin önsel bilgisini kullanmasından, diğer bir ifadeyle bilgileri bir önceki adımdan almasından dolayı bir önceki (prior) anlamına gelen “apriori” dir.
Apriori özelliği
Apriori algoritmasının temel yaklaşımı, “Eğer k nesneden oluşan nesne setleri kümesi en küçük destek kriterini sağlıyorsa, bu kümenin alt kümeleri de en küçük destek kriterini sağlar.” şeklindedir.
Örneğin; I={a,b,c,d} nesne kümesi için, şayet {a,b,c} nesne kümesi bir sık görülen nesne kümesi ise, onun tüm alt kümeleri olan ∅, {a}, {b}, {c}, {a, b}, {a, c} ve {b, c} kümeleri de sık görülen nesne kümeleridir. Bu özelliğe apriori özelliği adı verilir.
Destek Bazlı Budama Özelliği
Apriori özelliğinin aksine, “Eğer bir alt küme sık görülen nesne kümesi değil ise, onun bütün üst kümeleri de sık görülen nesne kümesi değildir” temel yaklaşımına sahiptir. Böylece belirlenen destek eşik değerini geçemeyen az elemanlı kümelerin üst kümeleri de destek eşik değerini geçemeyeceği için değerlendirme dışı bırakılır. Bu yönteme destek-bazlı budama (support based pruning) denir.
Örneğin; I={a,b,c,d} nesne kümesi için, şayet {c, d} nesne kümesi bir sık görülen nesne kümesi değil ise, bu kümenin elemanlarını içeren tüm üst kümeleri olan {a, c, d}, {b, c, d} ve {a, b, c, d} kümeleri de sık görülen nesne kümeleri değildir.
Bu nedenle doğru yanıt a) seçeneğidir.
Apriori özelliği
Apriori algoritmasının temel yaklaşımı, “Eğer k nesneden oluşan nesne setleri kümesi en küçük destek kriterini sağlıyorsa, bu kümenin alt kümeleri de en küçük destek kriterini sağlar.” şeklindedir.
Örneğin; I={a,b,c,d} nesne kümesi için, şayet {a,b,c} nesne kümesi bir sık görülen nesne kümesi ise, onun tüm alt kümeleri olan ∅, {a}, {b}, {c}, {a, b}, {a, c} ve {b, c} kümeleri de sık görülen nesne kümeleridir. Bu özelliğe apriori özelliği adı verilir.
Destek Bazlı Budama Özelliği
Apriori özelliğinin aksine, “Eğer bir alt küme sık görülen nesne kümesi değil ise, onun bütün üst kümeleri de sık görülen nesne kümesi değildir” temel yaklaşımına sahiptir. Böylece belirlenen destek eşik değerini geçemeyen az elemanlı kümelerin üst kümeleri de destek eşik değerini geçemeyeceği için değerlendirme dışı bırakılır. Bu yönteme destek-bazlı budama (support based pruning) denir.
Örneğin; I={a,b,c,d} nesne kümesi için, şayet {c, d} nesne kümesi bir sık görülen nesne kümesi değil ise, bu kümenin elemanlarını içeren tüm üst kümeleri olan {a, c, d}, {b, c, d} ve {a, b, c, d} kümeleri de sık görülen nesne kümeleri değildir.
Bu nedenle doğru yanıt a) seçeneğidir.
Soru 20
> library(“arules”)
> verideğişkeni <- list(…)
> işlemdeğişkeni <- as(verideğişkeni, “transactions”)
> sonuçdeğişkeni <- apriori(işlemdeğişkeni, parameter = list(supp=destekdeğeri, conf=güvendeğeri, minlen=3))
> inspect(sonuçdeğişkeni)
Yukarıda verilen, ilişki kuralları belirleme amacıyla oluşturulmuş R komutları kümesinde liste şeklinde girilmiş olan işlem verilerinin apriori() fonksiyonu ile işlenebilmesi için gereken veri dönüşümünün yapıldığı atama komutu hangisidir?
> verideğişkeni <- list(…)
> işlemdeğişkeni <- as(verideğişkeni, “transactions”)
> sonuçdeğişkeni <- apriori(işlemdeğişkeni, parameter = list(supp=destekdeğeri, conf=güvendeğeri, minlen=3))
> inspect(sonuçdeğişkeni)
Yukarıda verilen, ilişki kuralları belirleme amacıyla oluşturulmuş R komutları kümesinde liste şeklinde girilmiş olan işlem verilerinin apriori() fonksiyonu ile işlenebilmesi için gereken veri dönüşümünün yapıldığı atama komutu hangisidir?
Seçenekler
A
> işlemdeğişkeni <- as(verideğişkeni, “transactions”)
B
> inspect(sonuçdeğişkeni)
C
> sonuçdeğişkeni <- apriori(işlemdeğişkeni, parameter = list(supp=destekdeğeri, conf=güvendeğeri, minlen=3))
D
> verideğişkeni <- list(…)
E
> library(“arules”)
Açıklama:
R ile ilişki kuralı oluşturabilmek için arules paketinin R’de kurulması ve hafızaya yüklenmesi gerekir. arules paketi içerisinde yer alan apriori() fonksiyonu yardımıyla güçlü ilişki kuralları oluşturulur.
https://cran.r-project.org/web/packages/arules/
apriori() fonksiyonunun temel parametreleri ilişki kurallarının oluşturulabilmesi için elde edilen tüm işlemleri (alışverişleri) barındıran veri değişkenini ifade eden data ve özellikle destek ve güven eşik değerleri vb. kısıtlamalara ilişkin eşik değerlerinin belirlendiği parameter’dır. Veri girişi standart veri girişlerinden herhangi birisi ile yapılabilir. Ancak girilen verinin apriori() fonksiyonu ile işlenebilmesi için işlemlerden oluşan veritabanı formatına dönüştürülmesi gerekir. Veri dönüşümü için help(“transactions”) komutundan ve fonksiyon ile ilgili yardım için ise, help(“apriori”) komutundan yararlanılabilir.
Örnek 4 için apriori() fonksiyonu yardımıyla dört işlemden oluşan veritabanından destek eşik değeri 0,50 ve güven eşik değeri 0,75 olan güçlü ilişki kurallarının elde edilmesine ilişkin komut dizisi ve hesaplama sonucu izleyen biçimde ortaya çıkacaktır.
> library(“arules”)
> v e r i < - l i s t ( c ( “ M a k a r n a ” , ” A y r a n ” , ” E t ” ) , c(“Peynir”,”Ayran”,”Tavuk”), c(“Makarna”,”Peynir”,”Ayran ”,”Tavuk”), c(“Peynir”,”Tavuk”))
> islem <- as(veri, “transactions”)
> kurallar <- apriori(islem, parameter = list(supp=0.50, conf=0.75, minlen=3))
> inspect(kurallar)
lhs rhs support confidence lift
1 {Ayran, Peynir} ⇒ {Tavuk} 0.5 1 1.333333
2 {Ayran, Tavuk} ⇒ {Peynir} 0.5 1 1.333333
Verilen komut dizisinin dördüncü satırınındaki “islem <- as(veri, “transactions”)” komutu, liste şeklinde girilmiş olan işlem verilerinin apriori() fonksiyonu ile işlenebilmesi için gereken veri dönüşümünün yapıldığı atama komutudur. Komut dizisinin en altında elde edilen “kurallar” değişkeni dört adet işlem içeren veritabanı üzerinden oluşturulan, destek değeri en az 0,50 ve güven değeri en az 0,75 olan güçlü ilişki kurallarını ve bu kuralların hesaplanan sırasıyla destek, güven ve kaldıraç değerlerini vermektedir. R aracılığı ile elde edilen güçlü ilişki kuralları ve bu kuralların hesaplanan destek, güven ve kaldıraç değerlerinin Örnek 4’ün çözümünde elde edilen sonuçlar ile aynı olduğu görülmektedir.
Bu nedenle doğru yanıt a) seçeneğidir.
https://cran.r-project.org/web/packages/arules/
apriori() fonksiyonunun temel parametreleri ilişki kurallarının oluşturulabilmesi için elde edilen tüm işlemleri (alışverişleri) barındıran veri değişkenini ifade eden data ve özellikle destek ve güven eşik değerleri vb. kısıtlamalara ilişkin eşik değerlerinin belirlendiği parameter’dır. Veri girişi standart veri girişlerinden herhangi birisi ile yapılabilir. Ancak girilen verinin apriori() fonksiyonu ile işlenebilmesi için işlemlerden oluşan veritabanı formatına dönüştürülmesi gerekir. Veri dönüşümü için help(“transactions”) komutundan ve fonksiyon ile ilgili yardım için ise, help(“apriori”) komutundan yararlanılabilir.
Örnek 4 için apriori() fonksiyonu yardımıyla dört işlemden oluşan veritabanından destek eşik değeri 0,50 ve güven eşik değeri 0,75 olan güçlü ilişki kurallarının elde edilmesine ilişkin komut dizisi ve hesaplama sonucu izleyen biçimde ortaya çıkacaktır.
> library(“arules”)
> v e r i < - l i s t ( c ( “ M a k a r n a ” , ” A y r a n ” , ” E t ” ) , c(“Peynir”,”Ayran”,”Tavuk”), c(“Makarna”,”Peynir”,”Ayran ”,”Tavuk”), c(“Peynir”,”Tavuk”))
> islem <- as(veri, “transactions”)
> kurallar <- apriori(islem, parameter = list(supp=0.50, conf=0.75, minlen=3))
> inspect(kurallar)
lhs rhs support confidence lift
1 {Ayran, Peynir} ⇒ {Tavuk} 0.5 1 1.333333
2 {Ayran, Tavuk} ⇒ {Peynir} 0.5 1 1.333333
Verilen komut dizisinin dördüncü satırınındaki “islem <- as(veri, “transactions”)” komutu, liste şeklinde girilmiş olan işlem verilerinin apriori() fonksiyonu ile işlenebilmesi için gereken veri dönüşümünün yapıldığı atama komutudur. Komut dizisinin en altında elde edilen “kurallar” değişkeni dört adet işlem içeren veritabanı üzerinden oluşturulan, destek değeri en az 0,50 ve güven değeri en az 0,75 olan güçlü ilişki kurallarını ve bu kuralların hesaplanan sırasıyla destek, güven ve kaldıraç değerlerini vermektedir. R aracılığı ile elde edilen güçlü ilişki kuralları ve bu kuralların hesaplanan destek, güven ve kaldıraç değerlerinin Örnek 4’ün çözümünde elde edilen sonuçlar ile aynı olduğu görülmektedir.
Bu nedenle doğru yanıt a) seçeneğidir.
Soru 21
Aşağıdakilerden hangisi iletişim sektöründe, veri madenciliği ilişki kurallarının kullanıldığı alanlardan biridir?
Seçenekler
A
Ek hizmet paketleri
B
Hastalık ve tedavi geçmişinin belirlenmesi
C
Yatırım ürünleri
D
Krediler
E
Sigorta dolandırıcılığı tedbiri
Açıklama:
İletişim sektöründeki müşterilerin isteğe bağlı olarak satın aldıkları telesekreter, çağrı aktarma, ilave süre, internet hızı ve internet kotası vb. gibi ek hizmet kullanımları, hizmet paketleri oluşturmak amacıyla kullanılabilir. Doğru cevap A'dır.
Soru 22
"Bağlantıların ortaya çıkarılması ve bunun bir kural olarak değerlendirilmesi ilişki analizi ile mümkün olmaktadır."
Yukarıdaki ilişki analizine literatürde ne ad verilmektedir?
Yukarıdaki ilişki analizine literatürde ne ad verilmektedir?
Seçenekler
A
Veri tabanı
B
Pazar sepeti analizi
C
İlişki analizi
D
İlişki kuralları analizi
E
Veri analizi
Açıklama:
Bağlantıların ortaya çıkarılması ve bunun bir kural olarak değerlendirilmesi ilişki analizi ile mümkün olmaktadır. Buna da literatürde pazar sepeti analizi denmektedir. Doğru cevap B'dir.
Soru 23
Aşağıdakilerden hangisi pazar sepeti analizinin faydalarından biri değildir?
Seçenekler
A
Müşterinin kişisel tercihlerinin belirlenmesine yarar
B
Müşteri portföyünün genişlemesine yarar
C
Birlikte satışa sunulacak ürünlerin belirlenmesini sağlar
D
Ürün satış raflarının tasarlanmasına yardım eder
E
Promosyon düzenlemelerine imkan verir
Açıklama:
Pazar sepeti analizi, müşteri portföyünün genişlemesine olanak sağlamaz. Doğru cevap B'dir.
Soru 24
Bir alışveriş veritabanından oluşturulacak ilişki kuralları arasından işe yarayacak bilgiyi üretmek amacıyla kullanılacak ilişki kuralına ne denir?
Seçenekler
A
Veri madenciliği
B
Pazar sepeti analizi
C
İlişki kuralları
D
İlginç kural
E
Enteresan kural
Açıklama:
Bir alışveriş veritabanından oluşturulacak ilişki kuralları arasından işe yarayacak bilgiyi üretmek amacıyla kullanılacak ilişki kuralına ilginç kural denir.
Soru 25
İlginç olarak nitelendirilen ve bilgi üretmek amacıyla kullanılacak bir ilişki kuralının belirlenebilmesi için kullanılan ilk ölçüt hangisidir?
Seçenekler
A
Kaldıraç
B
Güven
C
Apriori Algoritması
D
Destek
E
Destek eşik değeri
Açıklama:
İlginç olarak nitelendirilen ve bilgi üretmek amacıyla kullanılacak bir ilişki kuralının belirlenebilmesi için kullanılan ilk ölçüt destektir. Doğru cevap D'dir.
Soru 26
Belirlenen destek ve güven eşik değerleri üzerinde destek ve güven değerine sahip ilişki kuralına ne denir?
Seçenekler
A
Güven eşik değeri
B
Destek eşik değeri
C
Güven
D
Destek
E
Güçlü kural
Açıklama:
Belirlenen destek ve güven eşik değerleri üzerinde destek ve güven değerine sahip ilişki kuralına güçlü kural denir. Doğru cevap E'dir.
Soru 27
Aşağıdakilerden hangisi ilişki kuralı oluşturabilmek için geliştirilen algoritmalardan biri değildir?
Seçenekler
A
CSS
B
AIS
C
SETM
D
FP-Growth
E
Eclat
Açıklama:
CSS, bir yazılım dilidir. Geliştirilen algoritmalardan biri değildir. Doğru cevap A'dır.
Soru 28
Aşağıdakilerden hangisi Apriori algoritmasının temel yaklaşımıdır?
Seçenekler
A
Eğer k nesneden oluşan nesne setleri kümesi en büyük destek kriterini sağlıyorsa, bu kümenin alt kümeleri de en küçük destek kriterini sağlar.
B
Eğer k nesneden oluşan nesne setleri kümesi en küçük destek kriterini sağlıyorsa, bu kümenin alt kümeleri de en küçük destek kriterini sağlar.
C
Eğer k ve l nesnelerinden oluşan nesne setleri kümesi en büyük destek kriterini sağlıyorsa, bu kümenin alt kümeleri de en küçük destek kriterini sağlar.
D
Eğer k ve l nesnelerinden oluşan nesne setleri kümesi en küçük destek kriterini sağlıyorsa, bu kümenin alt kümeleri de en küçük destek kriterini sağlar.
E
Eğer k nesneden oluşan nesne setleri kümesi en büyük destek kriterini sağlıyorsa, bu kümenin alt kümeleri en büyük destek kriterini sağlar.
Açıklama:
Apriori algoritmasının temel yaklaşımı, "Eğer k nesneden oluşan nesne setleri kümesi en küçük destek kriterini sağlıyorsa, bu kümenin alt kümeleri de en küçük destek kriterini sağlar."dır. Doğru cevap B'dir.
Soru 29
Apriori algoritmasının 1. Adımının ilk aşaması aşağıdakilerden hangisidir?
Seçenekler
A
L1 sık görülen nesne setleri kümesi elemanlarının ikili kombinasyonları alın- mak suretiyle birbirinden farklı tüm 2 adet nesne içeren nesne setleri oluşturulur. Ve oluşturulan bu nesne setlerinin destek değerleri hesaplanır.
B
Hesaplanan destek değerleri içerisinden destek eşik değeri olarak verilen 0,50 değerinin üzerinde destek değerine sahip nesne setlerinden bir nesneli sık görülen nesne kümesi L1 oluşturulur.
C
I nesneler kümesindeki 1 adet nesne içeren nesne setleri belirle- nir ve belirlenen her bir nesne seti için destek değerleri hesaplanır.
D
2 adet nesne içeren nesne setleri için hesaplanan destek değerleri içerisinden verilen destek eşik değeri 0,50 değerine eşit veya üzerinde destek değerine sahip nesne setlerinden iki nesneli sık görülen nesne setleri kümesi L2 oluşturulur.
E
Bu aşama giderek artan hesap yükünü azaltabilmek ve tekrar hesaplamalardan kaçınmak adına önceki aşamalarda elde edilen önsel bilgilerin değerlendirildiği aşamadır ve birleştirme ve budama adımlarından oluşur.
Açıklama:
İlk aşamada I nesneler kümesindeki 1 adet nesne içeren nesne setleri belirle- nir ve belirlenen her bir nesne seti için destek değerleri hesaplanır. Doğru cevap C'dir.
Soru 30
Aprio algoritmasının 1. adımının üçüncü aşaması aşağıdakilerden hangisidir?
Seçenekler
A
I nesneler kümesindeki 1 adet nesne içeren nesne setleri belirle- nir ve belirlenen her bir nesne seti için destek değerleri hesaplanır.
B
Hesaplanan destek değerleri içerisinden destek eşik değeri olarak verilen 0,50 değerinin üzerinde destek değerine sahip nesne setlerinden bir nesneli sık görülen nesne kümesi L1 oluşturulur.
C
Giderek artan hesap yükünü azaltabilmek ve tekrar hesaplamalardan kaçınmak adına önceki aşamalarda elde edilen önsel bilgilerin değerlendirildiği aşamadır ve birleştirme ve budama adımlarından oluşur.
D
2 adet nesne içeren nesne setleri için hesaplanan destek değerleri içerisinden verilen destek eşik değeri 0,50 değerine eşit veya üzerinde destek değerine sahip nesne setlerinden iki nesneli sık görülen nesne setleri kümesi L2 oluşturulur.
E
L1 sık görülen nesne setleri kümesi elemanlarının ikili kombinasyonları alın- mak suretiyle birbirinden farklı tüm 2 adet nesne içeren nesne setleri oluşturulur. Ve oluşturulan bu nesne setlerinin destek değerleri hesaplanır.
Açıklama:
Üçüncü aşamada, L1 sık görülen nesne setleri kümesi elemanlarının ikili kombinasyonları alın- mak suretiyle birbirinden farklı tüm 2 adet nesne içeren nesne setleri oluşturulur. Ve oluşturulan bu nesne setlerinin destek değerleri hesaplanır. Doğru cevap E'dir.
Soru 31
6 adet nesne içerisinden oluşturulabilecek nesne set sayısı kaç olur
Seçenekler
A
64
B
65
C
63
D
66
E
31
Açıklama:
nesne setlerinden bir tanesi boş kümedir ve boş küme ilişki kuralı belirlemek amacıyla kullanılamayacağından dolayı ilişki kuralı belirlemede kullanılacak nesne seti sayısı
2m-1 tane olur. Sonuç 26-1=63 tane nesne setidir.
2m-1 tane olur. Sonuç 26-1=63 tane nesne setidir.
Soru 32
5 nesne seti içerisinden 3 tane nesne içeren küme sayısı kaçtır?
Seçenekler
A
10
B
12
C
8
D
6
E
14
Açıklama:
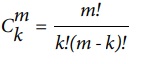 formülü üzerinden
formülü üzerinden 5!/3!*2!=10 nesne kümesi oluşturulur.
Soru 33
3 nesne içeren nesneler kümesinden toplam kaç adet ilişki kuralı oluşturulur?
Seçenekler
A
10
B
11
C
12
D
13
E
14
Açıklama:
3m-2m+1+1 formülü uygulandığında;
33-23+1+1=12
33-23+1+1=12
Soru 34
I. Daha önceden keşfedilmemiş,
II. Eyleme dönük, bir başka ifadeyle uygulanabilir,
III. Subjektif bir karar olabilir.
Yukarıdaki ifadelerden hangisi ya da hangileri ilginç kuralın özellikleri arasında sayılabilir?
II. Eyleme dönük, bir başka ifadeyle uygulanabilir,
III. Subjektif bir karar olabilir.
Yukarıdaki ifadelerden hangisi ya da hangileri ilginç kuralın özellikleri arasında sayılabilir?
Seçenekler
A
I-II
B
I-III
C
II-III
D
I-II-III
E
Yalnız II
Açıklama:
İfadelerin tamamı ilginç kurallar ile ilişkilidir.
Soru 35
5 farklı nesne içeren bir sette (A, B, C, D, E) 2 nesne setinin (A,E) destek değeri kaç olur?
Seçenekler
A
0,40
B
0,60
C
0,20
D
0,80
E
1
Açıklama:
Destek değerlerini hesaplayabilmek için öncelikle m=5 nesne içeren nesneler kümesinden iki nesneden oluşan nesne setlerinin (k=2) belirlenmesi gerekir. İki nesne içeren
nesne seti sayısı= 5!/2!*3!= 10'dur. Destek {A, E}= 2/5= 0,40
nesne seti sayısı= 5!/2!*3!= 10'dur. Destek {A, E}= 2/5= 0,40
Soru 36
Kaldıraç({A} ⇒ {B}) =Güven({A} ⇒ {B})/Destek{B} = 0,70/0,50 = 1,40 ifadesi için hangi yorum doğru olur?
Seçenekler
A
B olduğunda A' da olma olasılığı , sadece A olma olasılığından %40 daha fazladır.
B
A olduğunda B' de olma olasılığı , sadece B olma olasılığından %40 daha fazladır.
C
A olduğunda B' de olma olasılığı , sadece A olma olasılığından %40 daha fazladır.
D
B olduğunda A' da olma olasılığı , sadece A olma olasılığından %40 daha fazladır.
E
A olduğunda B' de olma olasılığı , sadece B olma olasılığından %140 daha fazladır.
Açıklama:
Verilen eşitliğe göre B şıkkındaki yorum doğru olacaktır.
Soru 37
Destek bazlı budama yöntemi nedir?
Seçenekler
A
Öncül(A) ve sonuç(B) nesne setleri arasındaki ilişkinin(korelasyonun) belirlenmesi temeline dayanarak hesaplanan kaldıraç(lift) değeri
B
Belirlenen destek eşik değerini geçemeyen az elemanlı kümelerin üst kümeleri de destek eşik değerini geçemeyeceği için değerlendirme dışı bırakılması
C
Belirlenen destek ve güven eşik değerleri üzerinde destek ve güven değerine sahip ilişki kuralı
D
Destek eşik değerini geçen ve kural oluşturmada kullanılacak nesne setleri
E
Kural için hesaplanacak destek ve güven değerleri ile ölçümü
Açıklama:
Apriori özelliğinin aksine, “Eğer bir alt küme sık görülen nesne kümesi değil ise, onun
bütün üst kümeleri de sık görülen nesne kümesi değildir” temel yaklaşımına sahiptir. Böylece belirlenen destek eşik değerini geçemeyen az elemanlı kümelerin üst kümeleri de destek eşik değerini geçemeyeceği için değerlendirme dışı bırakılır. Bu yönteme destek-bazlı
budama (support based pruning) denir.
bütün üst kümeleri de sık görülen nesne kümesi değildir” temel yaklaşımına sahiptir. Böylece belirlenen destek eşik değerini geçemeyen az elemanlı kümelerin üst kümeleri de destek eşik değerini geçemeyeceği için değerlendirme dışı bırakılır. Bu yönteme destek-bazlı
budama (support based pruning) denir.
Soru 38
7 adet nesne içeren bir sette sık görülen nesne seti toplam ilişki sayısı kaçtır?
Seçenekler
A
128
B
127
C
126
D
63
E
64
Açıklama:
k adet nesne içeren bir sık görülen nesne seti Lk şeklinde gösterilir. Lk’nın elemanları kullanılarak oluşturulacak toplam ilişki kuralı sayısı 2k-2 tanedir. Buradan doğru cevap: 126
Soru 39
Apriori algoritması ile ilişki kuralı oluşturma adımları içerisinde hangi adımda birleştirme ve budama işlemleri gerçekleştirilir?
Seçenekler
A
Aşama 1
B
Aşama 2
C
Aşama 4
D
Aşama 5
E
Aşama 6
Açıklama:
Bu aşama giderek artan hesap yükünü azaltabilmek ve tekrar hesaplamalardan kaçınmak adına önceki aşamalarda elde edilen önsel bilgilerin değerlendirildiği aşamadır ve birleştirme ve budama adımlarından oluşur.
Soru 40
10 nesneli bir set içerisinden bir nesnenin destek değeri ne olur?
Seçenekler
A
0,01
B
0,4
C
0,3
D
0,1
E
0,2
Açıklama:
Bir A nesne setinin destek değeri, aslında P(A)’dır. Yani A nesne setinin gözlenme olasılığıdır.
Soru 41
Müşterilerin daha önceden yapmış oldukları alışverişlerinden oluşan veritabanından her bir alışverişinde birlikte almış olduğu ürünler arasındaki ilişkilerden yola çıkılarak müşterilerin alışveriş alışkanlıklarının belirlenmesi işlemine ne ad verilmektedir?
Seçenekler
A
Piyasa analizi
B
Satış tahmini
C
Pazar sepeti analizi
D
Destek değer
E
İlişki kuralı
Açıklama:
Pazar sepeti analizi, müşterilerin daha önceden yapmış oldukları alışverişlerinden oluşan
veritabanından her bir alışverişinde birlikte almış olduğu ürünler arasındaki ilişkilerden yola çıkılarak müşterilerin alışveriş alışkanlıklarının belirlenmesidir. Doğru ceva C'dir.
veritabanından her bir alışverişinde birlikte almış olduğu ürünler arasındaki ilişkilerden yola çıkılarak müşterilerin alışveriş alışkanlıklarının belirlenmesidir. Doğru ceva C'dir.
Soru 42
5 adet nesne içeren bir I nesneler kümesinden ilişki kuralı belirlemede kullanmak üzere elde edilebilecek nesne seti sayısı kaçtır?
Seçenekler
A
31
B
10
C
16
D
32
E
64
Açıklama:
m adet nesne içeren bir I nesneler kümesinden elemanları birbirinden farklı oluşturulması mümkün tüm nesne setlerinin sayısı 2m tanedir. Ancak bu nesne setlerinden bir tanesi boş kümedir ve boş küme ilişki kuralı belirlemek amacıyla kullanılamayacağından dolayı ilişki kuralı belirlemede kullanılacak nesne seti sayısı 2m-1 tane olur. =32-1=31 olur. Doğru cevap A'dır.
Soru 43
Aşağıdakilerden hangisi I={a,b,c,d} nesneler kümesinden oluşturulabilecek nesne setlerinden biri değildir?
Seçenekler
A
abcd
B
a
C
cd
D
acd
E
abcde
Açıklama:
2m -1= 24 -1=15 adet nesne sayısı oluşturulabilir. Bunlar;a,b,c,d, ab,ac,ad,bc,bd,cd, abc, abd, acd, bcd ve abcd'dir. Doğru cevap E'dir.
Soru 44
İlginç kural ile ilgili olarak verilen ifadelerden hangileri doğrudur?
I-Karar vericinin tutumuna bağlı olarak değişebilmektedir.
II-Kuralın daha önce keşfedilmemiş olması gereklidir.
III-Objektif bir kuraldır.
IV-Belirli ölçütler kullanmak suretiyle bilgi üretmek amacıyla kullanılmayacak, önemsiz kuralların elenmesi ile elde edilebilir.
V-Kural uygulanabilir olmalıdır.
I-Karar vericinin tutumuna bağlı olarak değişebilmektedir.
II-Kuralın daha önce keşfedilmemiş olması gereklidir.
III-Objektif bir kuraldır.
IV-Belirli ölçütler kullanmak suretiyle bilgi üretmek amacıyla kullanılmayacak, önemsiz kuralların elenmesi ile elde edilebilir.
V-Kural uygulanabilir olmalıdır.
Seçenekler
A
II-III-V
B
I-II-III-IV-V
C
II-IV-V
D
I-II-IV-V
E
I-III-V
Açıklama:
Bir alışveriş veritabanından oluşturulacak ilişki kuralları arasından işe yarayacak bilgiyi üretmek amacıyla kullanılacak ilişki kuralı ilginç kural olarak tanımlanabilir. Bir ilişki kuralının ilginç kural
olarak değerlendirilebilmesi için,
i. Daha önceden keşfedilmemiş
ii. Eyleme dönük, bir başka ifadeyle uygulanabilir olması gerekir. Bir ilişki kuralının uygulanabilir olup olmadığı, ilgilenilen problemin amacı doğrultusunda konunun uzmanı olan karar verici tarafından verilen subjektif bir karardır. Dolayısıyla bir ilişki kuralının “ilginç kural” olarak değerlendirilmesi, problemin amacına ve karar vericinin tutumuna bağlı olarak değişebilmektedir. Bir ilişki kuralının “ilginç”liği, kişiden kişiye değişiklik gösterebilen yani subjektif bir karar olmasına rağmen, bu kararın verilebilmesi için verilerden elde edilebilecek ilişki kurallarının bilimsel veya objektif ölçütler aracılığı ile de elenmesi beklenir. Doğru cevap D'dir.
olarak değerlendirilebilmesi için,
i. Daha önceden keşfedilmemiş
ii. Eyleme dönük, bir başka ifadeyle uygulanabilir olması gerekir. Bir ilişki kuralının uygulanabilir olup olmadığı, ilgilenilen problemin amacı doğrultusunda konunun uzmanı olan karar verici tarafından verilen subjektif bir karardır. Dolayısıyla bir ilişki kuralının “ilginç kural” olarak değerlendirilmesi, problemin amacına ve karar vericinin tutumuna bağlı olarak değişebilmektedir. Bir ilişki kuralının “ilginç”liği, kişiden kişiye değişiklik gösterebilen yani subjektif bir karar olmasına rağmen, bu kararın verilebilmesi için verilerden elde edilebilecek ilişki kurallarının bilimsel veya objektif ölçütler aracılığı ile de elenmesi beklenir. Doğru cevap D'dir.
Soru 45
Çocuk bezi, ıslak mendil, mama, biberon, bebek şampuanı işlemlerinden oluşan bir veri tabanında; 3 nesne içeren bir A=(çocuk bezi, ıslak mendil, bebek şampuanı) biçiminde verilen bir nesne setinin destek değeri kaçtır?
Seçenekler
A
100
B
0,20
C
15
D
0,40
E
0,10
Açıklama:
m=5 tane nesne içeren, 3 nesneden oluşam nesne seti sayısı 5'in 3 lü kombinasyonu ile 10 olarak bulunur. Bunlar; Çocuk bezi=A, ıslak mendil= b, mama= c, biberon=D, bebek şampuanı=e olmak üzere:ABC, ABD, ABE, ACD, ACE, ADE, BCD, BDE, CDE VE BCE olmak üzere 10 tanedir. A=(çocuk bezi, ıslak mendil, bebek şampuanı); A=(A,B,E)
Destek (A)=|A|/|D| şeklinde elde edilir. A; nesne seti işlem sayısı=1 D ise işlemler veritabanındaki tüm işlemlerin sayısını=10 olmak üzere; Destek (A)=1/10=0,10 (%10) olarak elde edilir. Doğru cevap B'dir.
Destek (A)=|A|/|D| şeklinde elde edilir. A; nesne seti işlem sayısı=1 D ise işlemler veritabanındaki tüm işlemlerin sayısını=10 olmak üzere; Destek (A)=1/10=0,10 (%10) olarak elde edilir. Doğru cevap B'dir.
Soru 46
Belirlenen destek ve güven eşik değerleri üzerinde destek ve güven değerine sahip ilişki kuralına ne ad verilmektedir?
Seçenekler
A
Destek kural
B
Güven eşik değeri
C
Güçlü kural
D
Basit kural
E
Kaldıraç
Açıklama:
Belirlenen destek ve güven eşik değerleri üzerinde destek ve güven değerine sahip ilişki
kuralına güçlü kural denir. Doğru cevap C'dir.
kuralına güçlü kural denir. Doğru cevap C'dir.
Soru 47
A⇒B şeklinde ifade edilen bir ilişki kuralında B nesnesi ne olarak adlandırılmaktadır?
Seçenekler
A
Güven
B
Sonuç
C
Güç
D
Öncül
E
Alt küme
Açıklama:
A ⇒ B kuralı bir ilişki kuralı olarak adlandırılır. Burada A öncül (antecedent), B ise sonuç (consequent) olarak adlandırılır. Doğru cevap B'dir.
Soru 48
Destek({Makarna,Ketçap}⇒{Mayonez})=0,65 olarak hesaplanmış ise aşağıdakilerden hangisi doğrudur?
Seçenekler
A
Makarna alanların %65 i mayonez almış, %35'i ketçap almıştır.
B
Makarna ve ketçap alanlar mayonez almamıştır.
C
Mayonez alanlar ketçap ve makarna alanların %35'i kadardır.
D
Makarna ve ketçap alanlar mayonez alanların %35'i karadır.
E
Makarna ve ketçap alanların %65'i mayonez de almıştır.
Açıklama:
Bir ilişki kuralının destek değeri, o kuralın öncül (A) ve sonuç (B) kısmındaki nesne setlerinin birlikte gözlenme olasılığıdır ve P(A∪B) şeklinde ifade edilir. {Makarna, ketçap} ⇒{mayonez} şeklinde bir ilişkinin destek değeri;
{Makarna, ketça,mayonez} /|D|=0.65 yapılan alışverişlerin %65'inde makarna, ketçap ve mayonezin birlikte alınmış olduğu anlamına gelmektedir. Doğru cevap E'dir.
{Makarna, ketça,mayonez} /|D|=0.65 yapılan alışverişlerin %65'inde makarna, ketçap ve mayonezin birlikte alınmış olduğu anlamına gelmektedir. Doğru cevap E'dir.
Soru 49
Kaldıraç ({Zeytin}⇒{Peynir})= Güven({Zeytin}⇒{Peynir}) / Destek{Peynir} =0,85/0,50 = 1,70 sonucu nasıl yorumlanır?
Seçenekler
A
Zeytin alındığı zaman peynirinde alınma olasılığı, sadece peynir alınma olasılığından %70 daha fazladır.
B
Zeytin ve peynirin birlikte alınma olasılıkları%85'dir.
C
Peynir alınırken zeytinin alınmama olasılığı %1.70'dir.
D
Peynir alınıp zeytin alınmama olasılığı %85'dir.
E
Ya zeytin ya da peynirden birinin alınma olasığı %50'dir.
Açıklama:
Kaldıraç değeri, öncül (A) nesne setinin gözlendiği durumlarda sonuç(B) nesne setinin olasılığındaki değişim hakkında bilgi verir. İlişki kuralları için hesaplanacak kaldıraç değerinin özellikle 1 değerinden büyük olması istenilen durumdur. Çünkü bir ilişki kuralında kaldıraç değerinin 1’den büyük olması, tüm işlemler içerisinde sadece B’nin gözlendiği işlemlerin sayısının, A’nın gözlendiği işlemler içerisinde B’nin de gözlendiği işlem sayısından daha az olduğu anlamına gelir. Dolayısıyla kaldıraç değeri ne kadar büyük olursa, ilişki kuralını oluşturulan nesne setleri arasındaki ilişki de o kadar güçlü olur. Bu sonuçlara göre Zeytin alındığı zaman peynirinde alınma olasılığı, sadece peynir alınma olasılığından %70 daha fazladır.Doğru cevap A'dır.
Soru 50
Kaldıraç (A⇒B)<1 olması ne anlama gelmektedir?
Seçenekler
A
A ve B nesne setleri arasında ilişki yoktur.
B
A ve B nesne setleri arasında ilişkide, A nesne seti daha fazla gözlenmektedir.
C
A ve B nesne setleri arasında aynı yönlü zayıf bir ilişki vardır.
D
A ve B nesne setleri arasında ters yönlü bir ilişki vardır.
E
A ve B nesne setleri arasında zıt yönlü güçlü bir ilişki vardır.
Açıklama:
Kaldıraç değeri [0,∞) arasında değer alır ve yüzde olarak ifade edilir. Hesaplanan kaldıraç değerinin,
• Kaldıraç (A⇒B)<1 olması, A ve B nesne setleri arasında ters yönlü (negatif) bir
ilişki olduğunu,
• Kaldıraç (A⇒B)=1 olması, A ve B nesne setleri arasında ilişki olmadığını
• Kaldıraç (A⇒B)>1 olması, A ve B nesne setleri arasında aynı yönlü (pozitif) bir
ilişki olduğunu ifade eder. Doğru cevap D'dir.
• Kaldıraç (A⇒B)<1 olması, A ve B nesne setleri arasında ters yönlü (negatif) bir
ilişki olduğunu,
• Kaldıraç (A⇒B)=1 olması, A ve B nesne setleri arasında ilişki olmadığını
• Kaldıraç (A⇒B)>1 olması, A ve B nesne setleri arasında aynı yönlü (pozitif) bir
ilişki olduğunu ifade eder. Doğru cevap D'dir.
Soru 51
A ⇒ B şeklinde ifade edilen bir ilişki kuralında B nesne seti ne olarak ifade edilir?
Seçenekler
A
Sonuç
B
Öncül
C
Veri tabanı
D
Nesneler kümesi
E
Nesne seti
Açıklama:
A ⇒ B kuralı bir ilişki kuralı ise, A öncül (antecedent), B ise sonuç (consequent) olarak adlandırılır.
Soru 52
- Bir ilişki kuralının gücü, o kural için hesaplanacak destek ve güven değerleri ile ölçümlenebilir.
- Bir ilişki kuralının ilginç kural olarak değerlendirebilmesi için daha önceden de keşfedilmiş olması gereklidir.
- Bir ilişki kuralının ilginç kural olarak değerlendirebilmesi için uygulanabilir olması gereklidir.
- İlginç kuralların belirlenebilmesi amacıyla kullanılan ölçütler güven ve kaldıraç olmak üzere iki adettir.
Seçenekler
A
I ve II
B
I ve III
C
II ve IV
D
Yalnız II
E
II, III ve IV
Açıklama:
- Bir ilişki kuralının gücü, o kural için hesaplanacak destek ve güven değerleri ile ölçümlenebilir.
- Bir ilişki kuralının ilginç kural olarak değerlendirebilmesi için daha önceden de keşfedilmemiş olması gereklidir.
- Bir ilişki kuralının ilginç kural olarak değerlendirebilmesi için uygulanabilir olması gereklidir.
- İlginç kuralların belirlenebilmesi amacıyla kullanılan ölçütler destek, güven ve kaldıraç olmak üzere üç adettir.
Soru 53
Aşağıda verilen ifadelerden hangisi yanlıştır?
Seçenekler
A
Destek değeri, A nesne setinin gözlenme olasılığıdır.
B
A ⇒ B şeklinde olan ilişki kuralının destek değeri, A ve B nesne setlerinin birlikte gözlenme olasılığıdır.
C
Yüksek destek eşik değeri, ilginç kural elde edilebilecek nesne setlerinin sayısını arttırır.
D
Belirlenen destek eşik değerine eşit veya daha büyük destek değerine sahip nesne setine sık görülen nesne seti denir.
E
A ⇒ B şeklindeki bir ilişki kuralının güven değeri, aslında A’ yı içeren işlemlerin aynı zamanda B’ yi de içerme olasılığıdır.
Açıklama:
Yüksek destek eşik değeri, ilginç kural elde edilebilecek nesne setlerinin sayısını azaltır.
Soru 54
- Destek
- Güven
- Kaldıraç
- Doğruluk
- Geçerlik
Seçenekler
A
III, IV ve V
B
I, III ve V
C
II ve IV
D
I-II ve III
E
IV ve V
Açıklama:
İlginç kuralların belirlenebilmesi amacıyla kullanılan başlıca objektif ölçütler: destek, güven ve kaldıraç ölçütleridir.
Soru 55
Beş adet nesne içeren nesneler kümesinden ilişki kuralı oluşturmada kullanılabilecek farklı nesne sayılarına sahip oluşturulabilecek nesne seti sayısı aşağıdakilerden hangisidir?
Seçenekler
A
8
B
12
C
14
D
15
E
31
Açıklama:
25-1=31
Soru 56
A ve B nesne setleri arasında ilişki yok ise aşağıdakilerden hangisi doğrudur?
Seçenekler
A
Kaldıraç değeri=1
B
Kaldıraç değeri>1
C
Kaldıraç değeri<1
D
Destek değeri>1
E
Güven değeri>1
Açıklama:
Kaldıraç değerinin 1 olması A ve B nesneleri arasında ilişki olmadığı anlamına gelir.
Soru 57
R yazılımı ile kullanılan apriori fonksiyonu aşağıdaki seçeneklerden hangisi için kullanılır?
Seçenekler
A
Kümelere ayırmak
B
İlişki kuralı elde etmek
C
Sınıflama yapmak
D
Nedenleri tespit etmek
E
Farkları bulmak
Açıklama:
R ile ilişki kuralı oluşturabilmek için arules paketinin R’de kurulması ve hafızaya yüklenmesi gerekir. arules paketi içerisinde yer alan apriori() fonksiyonu yardımıyla güçlü ilişki kuralları oluşturulur.
Soru 58
Apriori algoritması ile ilgili aşağıdaki ifadelerden hangisi yanlıştır?
Seçenekler
A
Yinelemeli bir yaklaşım kullanır.
B
k-1 öğeli nesne setlerini birleştirerek k öğeli nesne setleri oluşturur.
C
Başlangıçta kullandığı bilgilere tekrar başvurup tekrar hesaplamalar yapar.
D
Belirlenmiş destek eşik değerini geçen nesne setleri ile sık görülen nesne setleri kümesi yapar.
E
Belirlenen eşik değerlerini dikkate alarak birleştirme ve budama yapar.
Açıklama:
Apriori algoritması seviye mantığı (level-wise) arama olarak bilinen yinelemeli bir yaklaşım kullanır. Bu yaklaşımda k ögeli nesne setleri (k-1) ögeli nesne setlerinin birleştirilmesiyle oluşturulur. Böylece algoritma ile başlangıçta hesaplanan bilgiler daha sonraki yinelemelerde kullanıldığı için tekrar hesapların yapılması engellenmiş olur. Apriori algoritmasının işleyişinde ilk olarak bir nesne içeren nesne setleri arasından belirlenen destek eşik değerini geçen nesne setlerinden yani bir nesneli sık görülen nesne setleri kümesi belirlenir.
Soru 59
Destek({Simit,Peynir}⇒{Çay})=0,90 olarak hesaplanmış ise aşağıdakilerden hangisi doğrudur?
Seçenekler
A
Simit ve peynirin birlikte alındığı alışverişlerin %90’ınında çay da alınmıştır.
B
Simit ve peynir alanlar yanında çay da almışlardır.
C
Simit ve peynir alama olasılığı, çay alma olasılığından %90 fazladır.
D
Simit ve peynir alanların % 90’ı çay da almıştır.
E
Simit ve peynir alanlar %10 olasılıkla çay da alırlar.
Açıklama:
Destek({Simit,Peynir}⇒{Çay})=0,90 olarak hesaplanmış ise, simit ve peynir alanların % 90’ı çay da almış şeklinde yorumlanır.
Soru 60
Güven({Kalem,Silgi}⇒{Defter})=0,60 olarak hesaplanmış ise aşağıdakilerden hangisi doğrudur?
Seçenekler
A
Kalem ve silgi alanların %60’ı defter de almıştır.
B
Kalem ve silgi alanlar %40 olasılıkla defter de alırlar.
C
Kalem ve silgi alanlar yanında defter de almışlardır.
D
Kalem ve silgi alma olasılığı, defter alma olasılığından %60 fazladır.
E
Kalem ve silginin birlikte alındığı alışverişlerin %60’ında defter de alınmıştır.
Açıklama:
Güven({Kalem,Silgi}⇒{Defter})=0,60 olarak hesaplanmış ise, kalem ve silginin birlikte alındığı alışverişlerin %60’ında defter de alındığı şeklinde yorumlanır.
Soru 61
Büyük veri kümeleri içerisinde belirli veriler arasındaki ilişkileri bulan ve olayların birlikte gerçekleşme ihtimallerini geçmiş verileri analiz edip ortaya koyarak geleceğe yönelik çalışmaları destekleyen veri madenciliği yöntemine ne denilir?
Seçenekler
A
İlişki kuralları
B
Veri kuralları
C
Veri madenciliği kuralları
D
Sıralama kuralları
E
Sınıflandırma kuralları
Açıklama:
Büyük veri kümeleri içerisinde belirli veriler arasındaki ilişkileri bulan ve olayların birlikte gerçekleşme ihtimallerini geçmiş verileri analiz edip ortaya koyarak geleceğe yönelik çalışmaları destekleyen veri madenciliği yöntemine ilişki kuralları denilmektedir.
Soru 62
Müşterilerin alışveriş alışkanlıklarının veritabanındaki bilgiler aracılığı ile ortaya çıkartılması işlemine ne denmektedir?
Seçenekler
A
İlişki analizi
B
Pazar analizi
C
Sepet analizi
D
Müşteri analizi
E
Pazar sepeti analizi
Açıklama:
Pazar sepeti analizi, müşterilerin alışveriş alışkanlıklarının veritabanındaki bilgiler aracılığı ile ortaya çıkartılması işlemidir. Müşterilerin alışveriş alışkanlıklarının ortaya çıkartılması, mağazalardaki ürünlerin yerleştirilmesine, mağaza alanının tasarlanmasına ve satışı yapılacak ürünlerin belirlenmesine yardımcı olur.
Soru 63
Bir ilişki kuralı oluşturmak amacıyla yapılacak ilişki analizinin amacı seçeneklerden hangisidir?
Seçenekler
A
Eşik değerlerini sağlayan kuralların elde edilmesi
B
Veri kümeleri arasındaki ilişkinin saptanması
C
Veri analizi kurallarının elde edilmesi
D
Veri depolama yöntemlerinin belirlenmesi
E
Analiz kriterlerinin elde edilmesi
Açıklama:
Bir ilişki kuralı oluşturmak amacıyla yapılacak ilişki analizinin amacı, değerleri karar verici tarafından belirlenen destek ve güven değerlerini kısaca eşik değerlerini sağlayan kuralların elde edilmesidir.
Soru 64
Seçeneklerden hangisi pazar sepet analizinin yapılması ile elde edilen çıktılardan biri değildir?
Seçenekler
A
Müşterilerin kişisel tercihlerinin belirlenmesi
B
Birlikte satışa sunulacak ürünlerin belirlenmesi
C
Ürün satış raflarının tasarlanması
D
Promosyon düzenlemeleri
E
Müşterilerin demografik özelliklerinin belirlenmesi
Açıklama:
Pazar sepeti analizi, müşterilerin daha önceden yapmış oldukları alışverişlerinden oluşan veritabanından her bir alışverişinde birlikte almış olduğu ürünler arasındaki ilişkilerden yola çıkılarak müşterilerin alışveriş alışkanlıklarının belirlenmesidir. Bu sayede müşterilerin kişisel tercihlerinin belirlenmesi, birlikte satışa sunulacak ürünlerin belirlenmesi, ürün satış raflarının tasarlanması ve promosyon düzenlemeleri gibi satışı artırmaya yönelik çalışmalar daha doğru bir şekilde yapılabilmektedir.
Soru 65
Pazar sepeti analizinde müşterilerin alışverişlerinde aldıkları her bir ürün nasıl ifade edilir?
Seçenekler
A
Mal
B
Nesne
C
İhtiyaç
D
Meta
E
Edinim
Açıklama:
Pazar sepeti analizinde müşterilerin alışverişlerinde aldıkları her bir ürün nesne olarak ifade edilir.
Soru 66
Pazar sepeti analizinde müşterilerin alışverişlerinde, içerisinde birçok ürünü barındıran her bir alışveriş nasıl ifade edilir?
Seçenekler
A
Ürün toplamı
B
Alışveriş
C
Sepet
D
İşlem
E
Küme
Açıklama:
Pazar sepeti analizinde müşterilerin alışverişlerinde aldıkları her bir ürün nesne, içerisinde birçok nesneyi yani ürünü barındıran her bir alışveriş ise işlem olarak ifade edilir.
Soru 67
Bir alışveriş veri tabanından oluşturulacak ilişki kuralları arasından işe yarayacak bilgiyi üretmek amacıyla kullanılacak ilişki kuralı nasıl tanımlanır?
Seçenekler
A
Doğru kural
B
Geçerli kural
C
İlginç kural
D
Anlamlı kural
E
Bast kural
Açıklama:
Bir alışveriş veri tabanından oluşturulacak ilişki kuralları arasından işe yarayacak bilgiyi üretmek amacıyla kullanılacak ilişki kuralı ilginç kural olarak tanımlanabilir.
Soru 68
İlginç kural ile ilgili seçeneklerden hangisi söylenemez?
Seçenekler
A
Daha önce keşfedilmemiş olması
B
Eyleme dönük olması
C
Uygulanabilir olması
D
Karar vericinin tutumuna göre değişmemesi
E
Belli ölçütlere uygun olması
Açıklama:
Bir ilişki kuralının ilginç kural olarak değerlendirilebilmesi için,
i. Daha önceden keşfedilmemiş
ii. Eyleme dönük, bir başka ifadeyle uygulanabilir
olması gerekir.
Bir ilişki kuralının “ilginç”liği, kişiden kişiye değişiklik gösterebilen yani subjektif bir karar olmasına rağmen, bu kararın verilebilmesi için verilerden elde edilebilecek ilişki kurallarının bilimsel veya objektif ölçütler aracılığı ile de elenmesi beklenir.
İlginç kuralların belirlenebilmesi amacıyla kullanılan başlıca objektif ölçütler destek ve güven ölçütleridir.
Bir ilişki kuralının “ilginç kural” olarak değerlendirilmesi, problemin amacına ve karar vericinin tutumuna bağlı olarak değişebilmektedir.
i. Daha önceden keşfedilmemiş
ii. Eyleme dönük, bir başka ifadeyle uygulanabilir
olması gerekir.
Bir ilişki kuralının “ilginç”liği, kişiden kişiye değişiklik gösterebilen yani subjektif bir karar olmasına rağmen, bu kararın verilebilmesi için verilerden elde edilebilecek ilişki kurallarının bilimsel veya objektif ölçütler aracılığı ile de elenmesi beklenir.
İlginç kuralların belirlenebilmesi amacıyla kullanılan başlıca objektif ölçütler destek ve güven ölçütleridir.
Bir ilişki kuralının “ilginç kural” olarak değerlendirilmesi, problemin amacına ve karar vericinin tutumuna bağlı olarak değişebilmektedir.
Soru 69
1994 yılında Agrawal ve Srikant tarafından geliştirilmiş ve ilişki kuralları oluşturabilme algoritmalarından en bilinen ve sık kullanılan algoritma seçeneklerden hagisidir?
Seçenekler
A
Arama algoritması
B
Graf Boyama Algoritması
C
Sıkıştırma Algoritması
D
Apriori Algoritması
E
Şifreleme Algoritması
Açıklama:
İlişki kuralı oluşturabilmek için geliştirilen algoritmalar içerisinde en çok bilinen ve en sık kullanılan algoritmadır. Apriori algoritması, 1994 yılında Agrawal ve Srikant tarafından geliştirilmiştir. Algoritmanın ismi, sık görülen nesne kümelerin önsel bilgisini kullanmasından, diğer bir ifadeyle bilgileri bir önceki adımdan almasından dolayı bir önceki (prior) anlamına gelen “apriori” dir.
Soru 70
Apriori algoritmasında belirlenen destek eşik değerini geçemeyen az elemanlı kümelerin üst kümeleri de destek eşik değerini geçemeyeceği için değerlendirme dışı bırakılmasına ne denir?
Seçenekler
A
Devre dışı bırakma
B
Kontrollü budama
C
Destek bazlı budama
D
Dereceli budama
E
Aşamalı budama
Açıklama:
Apriori algoritmasında belirlenen destek eşik değerini geçemeyen az elemanlı kümelerin üst kümeleri de destek eşik değerini geçemeyeceği için değerlendirme dışı bırakılır. Bu yönteme destek-bazlı budama (support based pruning) denir.
Soru 71
Pazar sepeti analizinde, bir işlemde alınan nesneler arasındaki ilişkiler incelenerek çeşitli ___________ oluşturulur?
Seçenekler
A
Korelasyonlar
B
Ortalamalar
C
Testler
D
İlişki kuralları
E
Olaylar
Açıklama:
Pazar sepeti analizinde nesneler, müşteriler tarafından satın alınan ürünlerdir. Bir kalemde satın alınan ve içerisinde birçok nesneyi barındıran satın alma ise işlem veya kayıt olarak nitelendirilir. Dolayısıyla Pazar sepeti analizinde, bir işlemde alınan nesneler arasındaki ilişkiler incelenerek çeşitli ilişki kuralları oluşturulur.
Soru 72
{Süt, Ekmek} ⇒ {Yumurta} kuralında sonuç hangisidir?
Seçenekler
A
Hepsinin bileşkesi
B
Süt
C
Sonuç yoktur
D
Yumurta
E
Ekmek
Açıklama:
A ⇒ B kuralı bir ilişki kuralı olarak adlandırılır. Burada A öncül (antecedent), B ise sonuç (consequent) olarak adlandırılır.
Bu marketten süt ve ekmek alan müşterilerin bunlarla birlikte çoğunlukla yumurta da aldıkları yönünde oluşturulacak bir ilişki kuralı {Süt, Ekmek} ⇒ {Yumurta} şeklinde ifade edilir.
Bu marketten süt ve ekmek alan müşterilerin bunlarla birlikte çoğunlukla yumurta da aldıkları yönünde oluşturulacak bir ilişki kuralı {Süt, Ekmek} ⇒ {Yumurta} şeklinde ifade edilir.
Soru 73
m=4 adet nesne ya da ürün içeren bir I={a, b, c, d} nesneler kümesinden farklı nesne sayılarına sahip, oluşturulması mümkün tüm nesne setlerinin sayısı nedir?
Seçenekler
A
2
B
3
C
6
D
12
E
16
Açıklama:
2^m = 2^4 =16 tane olur.
Soru 74
m=4 adet nesne ya da ürün içeren bir nesneler kümesinden k=2 nesne içeren nesne kümelerinin sayısı nedir?
Seçenekler
A
1
B
3
C
6
D
8
E
12
Açıklama:
Combinasyon(4,2)=6
Soru 75
Bir alışveriş veritabanından oluşturulacak ilişki kuralları arasından işe yarayacak bilgiyi üretmek amacıyla kullanılacak ilişki kuralı ___________olarak tanımlanabilir?
Seçenekler
A
Deneme
B
Tanımlayıcı ilişki
C
ilginç kural
D
Tahminsel kural
E
Düzenli kural
Açıklama:
Bir alışveriş veritabanından oluşturulacak ilişki kuralları arasından işe yarayacak bilgiyi üretmek amacıyla kullanılacak ilişki kuralı ilginç kural olarak tanımlanabilir.
Soru 76
İlginç olarak nitelendirilen ve nesne setleri içerisinden eleme yapılmasını sağlayan ilk ölçüt nedir?
Seçenekler
A
Bağımsızlık
B
Destek
C
Durağanlık
D
Düzeylilik
E
Benzerlik
Açıklama:
İlginç olarak nitelendirilen ve bilgi üretmek amacıyla kullanılacak bir ilişki kuralının belirlenebilmesi için kullanılan ilk ölçüt, nesne setleri içerisinden eleme yapılmasını sağlayan destek değeridir.
Soru 77
Veritabanında yer alan toplam 5 işlemin 2 tanesinde süt ve ekmek nesneleri birlikte alınmış ise {süt,ekmek} için destek değeri nedir?
Seçenekler
A
0,40
B
0,35
C
0,20
D
0,10
E
0,05
Açıklama:
Destek{süt,ekmek}=2/5=0,40
Soru 78
Belirlenen destek eşik değerine eşit veya daha büyük destek değerine sahip nesne setine _________ nesne seti denir?
Seçenekler
A
ortalama
B
sık görülen
C
en az görülen
D
tamamlayıcı
E
eksik
Açıklama:
Belirlenen destek eşik değerine eşit veya daha büyük destek değerine sahip nesne setine sık görülen nesne seti denir.
Soru 79
Sık görülen nesne setleri ile A⇒B şeklinde oluşturulan bir ilişki kuralı için hesaplanacak güven değeri, D işlemler veritabanında A’yı içeren ve aynı zamanda B’yi de içeren işlemlerin sayısının sadece A’yı içeren işlem sayısına __________?
Seçenekler
A
eklenmesidir
B
çıkarılmasıdır
C
oranıdır
D
çarpımıdır
E
eşittir
Açıklama:
Sık görülen nesne setleri ile A⇒B şeklinde oluşturulan bir ilişki kuralı için hesaplanacak güven değeri, D işlemler veritabanında A’yı içeren ve aynı zamanda B’yi de içeren işlemlerin sayısının sadece A’yı içeren işlem sayısına oranıdır.
Soru 80
Aşağıdaki güven değerlerinden hangisi geçerli bir değerdir?
Seçenekler
A
2
B
3,14
C
0,97
D
1,45
E
-1,45
Açıklama:
bir ilişki kuralının güven değeri, o kuralın öncül(A) nesne setinin ortaya çıkması veya gözlenmesi durumunda sonuç (B) nesne setinin de ortaya çıkması, gözlenmesi olasılığıdır ve P(B│A) şeklinde gösterilir. Güven değeri [0,1] arasında değer alır ve yüzde olarak yorumlanır.
Soru 81
Büyük veri setlerinde, geçmişte ortaya çıkmış örüntülere dayanarak gelecekteki çalışmaları destekleyen veri madenciliği yöntemine ne ad verilir?
Seçenekler
A
k-ortalamalar
B
İlişki kuralları
C
Kümeleme analizi
D
Rassal orman
E
Karar ağaçları
Açıklama:
Doğru yanıt, ilişki kurallarıdır.
Soru 82
Bir ürünün, alıcıya sunuşu aşamasında hangi ürünlerle birlikte alındığının belirlenmesine yönelik yönteme ne ad verilir?
Seçenekler
A
Pazar sepet analizi
B
A priori algortiması
C
k-ortalamalar
D
En yakın komşular
E
Karar ağaçları
Açıklama:
Birlikte hangi ürünlerin sattığı, pazar sepet analizi ile belirlenir.
Soru 83
Bir ilişki kuralının ilginçliğini belirlemede, ilgili nesne setinin gözlenme olasılığının hesaplanmasına ne ad verilir?
Seçenekler
A
Güven
B
Kaldıraç
C
Destek
D
Çapraz geçerleme
E
Hassasiyet
Açıklama:
Bir ilişki kuralının belirlenmesinde ilginçlik, subjektif olabilmektedir. Bu durumu değiştirmek adına bilimsel bazı kurallar belirlenmiştir. Bunlardan soruda bahsedileni ise "destek"tir.
Soru 84
Bir olayın öncülünü içeren işlemlerin aynı zamanda sonucunu da içermesine ne ad verilir?
Seçenekler
A
Güven değeri
B
Kaldıraç
C
Destek
D
A priori
E
Çapraz geçerlik
Açıklama:
Tanıma uygun doğru yanıt, güven ya da daha geniş olarak güven değeridir.
Soru 85
Bir ilişki kuralının "güçlü" olabilmesi için gerekli olan durum nedir?
Seçenekler
A
Güven değerinin çok yüksek olması
B
Destek değerinin çok yüksek olması
C
Hem güven hem de destek değerinin çok yüksek olması
D
Hem güven hem de destek için eşiğin üzerinde değerler elde edilmesi
E
Destek değeri için belirlenen eşiğin çok üzerinde değerler kestirilmesi
Açıklama:
Hem destek hem de güven değerleri için belirlenen eşiğin üzerinde destek ve güven değerlerinin kestirilmesi, ilişki kuralının "güçlü kural" olduğunun göstergesidir.
Soru 86
I={a,b,c,d,e} şeklinde verilen beş nesne içeren nesne kümesi için, {a} ve {c, e} nesne kümeleri sık görülen nesne kümeleri olmadığına göre, destek bazlı budama özelliğine göre ilişki kuralı oluşturmak için kullanılabilecek nesne seti sayısı kaçtır?
Seçenekler
A
8
B
9
C
10
D
11
E
12
Açıklama:
İlişki kuralı oluşturulurken nesne sayısı 2n-1 formülüyle elde edilir. Buna göre nesne sayısı 31'dir. içerisinde a ya da (c,e)'nin bulunmadığı nesnelerin sayısı ise 11'dir.
Soru 87
n sayıda nesneden oluşan bir nesne setleri kümesinin en küçük destek kriterini sağlaması durumunda, alt kümelerinin de en küçük destek kümelerini sağladığı yönündeki yaklaşıma ne ad verilir?
Seçenekler
A
A priori
B
Destek bazlı budama
C
Kaldıraç
D
Güven
E
Destek
Açıklama:
Bu yaklaşım, a priori adını almaktadır.
Soru 88
İlginç kurala ilişkin aşağıdakilerden hangisi doğrudur?
Seçenekler
A
Daha önce keşfedilmelidir
B
Düşünceye dönüktür
C
Problemin amacına ve karar vericinin tutumuna bağlı olarak değişebilmektedir
D
İlginçlik niteliğine objektif olarak karar verilebilir
E
İlginç kuralların belirlenebilmesi amacıyla kullanılan başlıca subjektif ölçütler destek ve güven ölçütleridir
Açıklama:
İlginç kural problemin amacına ve karar vericinin tutumuna bağlı olarak değişebilmektedir.
Soru 89
Destek Eşik Değeri'ne ilişkin olarak hangisi doğrudur?
Seçenekler
A
İlginç kural elde edebilmek için ilk eleme işlemi,destek eşik değerinin belirlenmiş olması durumunda yapılabilmektedir
B
Elenen nesne setleri, ilişki kuralı oluşturmak amacıyla kullanılabilir
C
Belirlenecek destek eşik değerinin çok düşük bir değer olması, ilginç kural elde edebilmek için ele alınacak nesne setlerinin sayısını aşırı derecede azaltacaktır
D
ilginç kural elde edebilmek için ele alınacak nesne setlerinin sayısının çok olması durumunda ilişki kuralı sayısı çok olacaktır
E
Belirlenecek destek eşik değeri, tüm nesne setleri içerisinden bu destek eşik değerinden daha büyük destek değerine sahip nesne setlerinin elenmesini sağlar
Açıklama:
İlginç kural elde edebilmek için ilk eleme işlemi,destek eşik değerinin belirlenmiş olması durumunda yapılabilmektedir.
Soru 90
Aşağıdakilerden hangisi öncül (A) nesne setinin gözlendiği durumlarda sonuç(B) nesne setinin olasılığındaki değişim hakkında bilgi verir?
Seçenekler
A
Güven eşik değeri
B
Destek eşit değeri
C
Destek değeri
D
Kaldıraç değeri
E
Güven değeri
Açıklama:
Kaldıraç değeri, öncül (A) nesne setinin gözlendiği durumlarda sonuç (B) nesne setinin olasılığındaki değişim hakkında bilgi verir.
Soru 91
İlişki kuralı oluşturabilmek için geliştirilen algoritmalar içerisinde en çok bilinen ve en sık kullanılan Apriori algoritması kaç yılında geliştirtilmiştir?
Seçenekler
A
1994
B
1995
C
1996
D
1997
E
1998
Açıklama:
Apriori algoritması, 1994 yılında Agrawal ve Srikant tarafından geliştirilmiştir.
Soru 92
Aşağıdakilerden hangisi yanlıştır?
Seçenekler
A
Apriori algoritması “Eğer bir alt küme sık görülen nesne kümesi değil ise, onun bütün üst kümeleri de sık görülen nesne kümesi değildir” temel yaklaşımına sahiptir
B
Apriori özelliğine göre; I={a,b,c,d} nesne kümesi için, şayet {a,b,c} nesne kümesi bir sık görülen nesne kümesi ise, onun tüm alt kümeleri olan ∅, {a}, {b}, {c}, {a, b}, {a, c} ve {b, c} kümeleri de sık görülen nesne kümeleridir
C
Destek bazlı budama özelliğine göre; I={a,b,c,d} nesne kümesi için, şayet {c, d} nesne kümesi bir sık görülen nesne kümesi değil ise, bu kümenin elemanlarını içeren tüm üst kümeleri olan {a, c, d}, {b, c, d}
ve {a, b, c, d} kümeleri de sık görülen nesne kümeleri değildir
ve {a, b, c, d} kümeleri de sık görülen nesne kümeleri değildir
D
Apriori algoritması yaklaşımında k ögeli nesne setleri (k-1) ögeli nesne setlerinin birleştirilmesiyle oluşturulmaktadır
E
Apriori algoritması ile başlangıçta hesaplanan bilgiler daha sonraki yinelemelerde kullanıldığı için tekrar hesapların yapılması engellenmiş olur
Açıklama:
Destek bazlı budama özelliği, “Eğer bir alt küme sık görülen nesne kümesi değil ise, onun bütün üst kümeleri de sık görülen nesne kümesi değildir” temel yaklaşımına sahiptir.
Soru 93
Apriori algoritması ile ilişki kuralı oluşturma adımlarına ilişkin hangisi doğrudur?
Seçenekler
A
1. adımın ilk aşamasında L1 sık görülen nesne setleri kümesi elemanlarının ikili kombinasyonları alınmak suretiyle birbirinden farklı tüm 2 adet nesne içeren nesne setleri oluşturulur ve oluşturulan bu nesne setlerinin destek değerleri hesaplanır
B
1. adımın ikinci aşamasında I nesneler kümesindeki 1 adet nesne içeren nesne setleri belirlenir ve belirlenen her bir nesne seti için destek değerleri hesaplanır
C
1. adımın üçüncü aşamasında 2 adet nesne içeren nesne setleri için hesaplanan destek değerleri içerisinden verilen destek eşik değeri 0,50 değerine eşit veya üzerinde destek değerine sahip nesne
setlerinden iki nesneli sık görülen nesne setleri kümesi L2 oluşturulur
setlerinden iki nesneli sık görülen nesne setleri kümesi L2 oluşturulur
D
1.adımın 6. aşaması giderek artan hesap yükünü azaltabilmek ve tekrar hesaplamalardan kaçınmak adına önceki aşamalarda elde edilen önsel bilgilerin değerlendirildiği aşamadır ve birleştirme ve budama adımlarından oluşur
E
1. adımın 7. aşamasında L3 sık görülen nesne kümesinin sadece bir elemanı olduğu için 4 ve daha
fazla nesneden oluşan nesne setleri oluşturulamaz
fazla nesneden oluşan nesne setleri oluşturulamaz
Açıklama:
1. adımın 7. aşamasında L3 sık görülen nesne kümesinin sadece bir elemanı olduğu için 4 ve daha
fazla nesneden oluşan nesne setleri oluşturulamaz.
fazla nesneden oluşan nesne setleri oluşturulamaz.
Soru 94
Apriori algoritması ile ilişki kuralı oluşturma adımlarına ilişkin hangisi yanlıştır?
Seçenekler
A
1. adım tüm sık görülen nesne setlerinin elde edilmesidir
B
2. adım sık görülen nesne setlerinden güçlü ilişki kuralının elde edilmesidir
C
1.adımda amaç, apriori algoritması ile verilen 0,50 destek eşik değerine eşit veya daha büyük destek değerine sahip olan sık görülen nesne setleri kümelerinin elde edilmesidir
D
2. adımda amaç, birinci adımda elde edilen en düşük mertebeye sahip sık görülen nesne setleri
kümesinin elemanları kullanılarak güçlü ilişki kurallarının oluşturulmasıdır
kümesinin elemanları kullanılarak güçlü ilişki kurallarının oluşturulmasıdır
E
1. adım 7 aşamadan oluşmaktadır
Açıklama:
2. adımda amaç, birinci adımda elde edilen en yüksek mertebeye sahip sık görülen nesne setleri
kümesinin elemanları kullanılarak güçlü ilişki kurallarının oluşturulmasıdır.
2. adımda amaç, birinci adımda elde edilen en düşük mertebeye sahip sık görülen nesne setleri
kümesinin elemanları kullanılarak güçlü ilişki kurallarının oluşturulmasıdır.
kümesinin elemanları kullanılarak güçlü ilişki kurallarının oluşturulmasıdır.
2. adımda amaç, birinci adımda elde edilen en düşük mertebeye sahip sık görülen nesne setleri
kümesinin elemanları kullanılarak güçlü ilişki kurallarının oluşturulmasıdır.
Soru 95
İlişki kurallarında R çözümüne ilişkin hangisi doğrudur?
Seçenekler
A
R ile ilişki kuralı oluşturabilmek için arules paketinin R’de kurulması ve hafızaya yüklenmesi gerekir
B
Arules paketi içerisinde yer alan apriori() fonksiyonu yardımıyla zayıf ilişki kuralları oluşturulur
C
Veri dönüşümü için help (“apriori”) komutundan yararlanılabilir
D
Fonksiyon ile ilgili yardım için help(“transaction”) komutundan yararlanılabilir
E
Veri girişi standart olmayan veri girişlerinden herhangi birisi ile yapılabilir
Açıklama:
R ile ilişki kuralı oluşturabilmek için arules paketinin R’de kurulması ve hafızaya yüklenmesi gerekmektedir.
Soru 96
İlişki kurallarını belirleme aşamalarından 2. aşamaya ilişkin hangisi doğrudur?
Seçenekler
A
K adet nesne içeren bir sık görülen nesne seti Lk şeklinde gösterilir
B
Lk’nın elemanları kullanılarak oluşturulacak toplam İlişki kuralı sayısı 2k-1 tanedir
C
Oluşturulan ilişki kuralları içerisinden belirlenen güven eşik değerine eşit ya da daha düşük güven değerine sahip ilişki kuralları güçlü ilişki kuralları olarak nitelendirilir
D
İlişki kuralı oluşturmak amacıyla kullanılan algoritmalarının performansını belirleyen adım ikinci adımdır
E
İlişki kuralı oluşturma aşamalarından 2.adım 1.adıma göre işlem yükü açısından çok daha karmaşıktır
Açıklama:
K adet nesne içeren bir sık görülen nesne seti Lk şeklinde gösterilir.
Soru 97
İlişki kurallarına ilişkin hangisi yanlıştır?
Seçenekler
A
İlişki kuralları, veri madenciliğinin tanımlayıcı modellerinden birisidir
B
Büyük veri kümeleri içerisinde belirli veriler arasındaki ilişkileri bulan ve olayların birlikte gerçekleşme ihtimallerini geçmiş verileri analiz edip ortaya koyarak geleceğe yönelik çalışmaları destekleyen veri madenciliği yöntemine ilişki kuralları denilmektedir
C
İlişki kuralları sayesinde büyük miktarlardaki veriler arasından ilginç birliktelik örüntüleri keşfedilerek karar verme, pazarlama ve iş yönetimi gibi konularda birçok fayda sağlanmaktadır
D
İlişki kuralları; ekonomi, eğitim, e-ticaret, pazarlama, iletişim ve sağlık gibi birçok sektörde geniş kullanıma sahip veri madenciliğinin özel bir uygulama alanıdır
E
İlişki kuralları, günlük hayatta özellikle insanların beklentilerinin belirlenmesinde çoğu zaman başarılı olmaktadır
Açıklama:
İlişki kuralları, günlük hayatta özellikle insanların beklentilerinin belirlenmesinde çoğu zaman başarısızdır.
İlişki kuralları, günlük hayatta özellikle insanların beklentilerinin belirlenmesinde çoğu zaman başarılı olmaktadır.
İlişki kuralları, günlük hayatta özellikle insanların beklentilerinin belirlenmesinde çoğu zaman başarılı olmaktadır.
Soru 98
5 adet nesne içeren nesneler kümesinde ilişki kuralı oluşturmak için kullanılabilecek toplam nesne seti sayısı kaçtır?
Seçenekler
A
7
B
15
C
31
D
63
E
255
Açıklama:
İlişki kuralı oluşturmak için kullanılabilecek toplam nesne seti sayısı 2m-1 'dir. Burada m=5 olduğuna göre:
25-1=32-1=31 'tür
25-1=32-1=31 'tür
Soru 99
m=5 adet nesne ya da ürün içeren bir nesneler kümesinden k=3 nesne içeren nesne kümelerinin sayısı kaçtır?
Seçenekler
A
4
B
6
C
8
D
10
E
12
Açıklama:
C53 = 5! / 3! (5-3)! = 5x4x3x2x1/3x2x1x2 = 10
Soru 100
m=6 nesne içeren nesneler kümesinden kaç tane ilişki kuralı oluşturulabilir?
Seçenekler
A
202
B
302
C
402
D
502
E
602
Açıklama:
Sayfa 106'da belirtildiği gibi m adet nesne içeren bir nesneler kümesinden toplamda 3m-2m+1 adet ilişki kuralı oluşturulabilir.
m=6 olduğuna göre; 36-26+1+1 tane ilişki kuralı oluşturulabilir.
36-26+1+1= 729-128+1= 602
m=6 olduğuna göre; 36-26+1+1 tane ilişki kuralı oluşturulabilir.
36-26+1+1= 729-128+1= 602
Soru 101
Aşağıdakilerden hangisi bir destek değeri olabilir?
Seçenekler
A
-3,2
B
3,2
C
1,6
D
3
E
0,20
Açıklama:
Destek değeri 0 ile bir arasında bir değerdir.
Soru 102
A nesne setini içeren işlem sayısı 12 ve A nesne setinin destek değeri 0,4 ise işlemler veritabanındaki toplam işlem sayısı kaçtır?
Seçenekler
A
18
B
24
C
30
D
36
E
42
Açıklama:
Bir A nesne setinin destek değeri, D işlemler veritabanında A nesne setini içeren işlem sayısının veritabanındaki tüm işlemlerin sayısına oranı şeklinde elde edilir.
12/D = 0,4 = 4/10
120=4xD
D=30
12/D = 0,4 = 4/10
120=4xD
D=30
Soru 103
Bir markette o gün yapılan tüm alışlar içerisinde süt ve ekmeği birlikte alan kişi sayısı 18' dir. Süt ve ekmeği birlikte satın alan kişilerin yarısı yumurta da almıştır. Toplam alışveriş sayısı 36 olduğuna göre "süt ve ekmek alanlar yumurta da almıştır" kuralının destek değeri kaçtır?
Seçenekler
A
0,125
B
0,25
C
0,50
D
0,625
E
0,75
Açıklama:
Aslında bir ilişki kuralının destek değeri, o kuralın öncül (A) ve sonuç (B) kısmındaki nesne setlerinin birlikte gözlenme olasılığıdır. Bu durumda öncelikle süt, ekmek ve yumurtayı birlikte alanların sayısını hesaplamak gerekir. Süt ve ekmeği birlikte satın alan kişilerin yarısı yumurta da aldığına göre. 18/2=9 kişi süt ekmek ve yumurtayı birlikte almıştır. Toplam 36 işlem olduğuna göre 9/36=0,25 'tir.
Soru 104
Bir markette o gün yapılan tüm alışverişler içerisinde süt ve ekmeği birlikte alan kişi sayısı 18' dir. Süt ve ekmeği birlikte satın alan kişilerin yarısı yumurta da almıştır. Toplam alışveriş sayısı 36 olduğuna göre "süt ve ekmek alanlar yumurta da almıştır" kuralının güven değeri kaçtır?
Seçenekler
A
0,125
B
0,25
C
0,50
D
0,625
E
0,75
Açıklama:
Tüm alışverişler içerisinde süt ve ekmeğin birlikte alındığı alışverişlerin yarısında yumurta da alınmıştır. Dolayısı ile bu kuralın güven değeri 0,50' dir.
Soru 105
Bir markette o gün yapılan tüm alışlar içerisinde süt ve ekmeği birlikte alan kişi sayısı 18' dir. Süt ve ekmeği birlikte satın alan kişilerin yarısı yumurta da almıştır. Toplam alışveriş sayısı 36 ve yumurta alanların toplam sayısı 18 olduğuna göre "süt ve ekmek alanlar yumurta da almıştır" kuralının kaldıraç değeri kaçtır?
Seçenekler
A
0,25
B
0,5
C
0,75
D
1
E
1,25
Açıklama:
Kaldıraç (A ⇒ B) = Güven(A⇒B) / Destek (B)
A süt ve ekmek alanlar ve B yumurta alanlar olduğuna göre;
Güven(A⇒B) 0,5' dir çünkü ekmek ve süt alanların yarısı yumurta almıştır.
Destek (B) de 0,5' bir çünkü tüm alışverişlerin yarısında yumurta alınmıştır (18/36).
Dolayısı ile Kaldıraç (A ⇒ B) = Güven(A⇒B) / Destek (B)= 1 'dir.
Süt ve ekmeği beraber almak ve yumurta almak arasında ilişki yoktur.
A süt ve ekmek alanlar ve B yumurta alanlar olduğuna göre;
Güven(A⇒B) 0,5' dir çünkü ekmek ve süt alanların yarısı yumurta almıştır.
Destek (B) de 0,5' bir çünkü tüm alışverişlerin yarısında yumurta alınmıştır (18/36).
Dolayısı ile Kaldıraç (A ⇒ B) = Güven(A⇒B) / Destek (B)= 1 'dir.
Süt ve ekmeği beraber almak ve yumurta almak arasında ilişki yoktur.
Soru 106
5 nesne içeren bir sık görülen nesne setinden kaç tane ilişki kuralı üretilebilir?
Seçenekler
A
6
B
14
C
30
D
70
E
142
Açıklama:
K adet nesne içeren bir sık görülen nesne seti Lk şeklinde gösterilir. Lk ’nın elemanları kullanılarak oluşturulacak toplam ilişki kuralı sayısı 2k -2 tanedir.
25 -2= 30' tir.
25 -2= 30' tir.
Soru 107
I. A
II. A,C
III. A, B, D
IV. D, B
V. ∅ A, B ve C elemanlarından oluşan küme sık görülen nesne kümesi olduğuna göre
yukarıdakilerden hangisi sık görülen nesne kümesi olmayabilir?
II. A,C
III. A, B, D
IV. D, B
V. ∅ A, B ve C elemanlarından oluşan küme sık görülen nesne kümesi olduğuna göre
yukarıdakilerden hangisi sık görülen nesne kümesi olmayabilir?
Seçenekler
A
I, V
B
IV, V
C
III, IV
D
V
E
I, III, IV
Açıklama:
şayet {a,b,c} nesne kümesi bir sık görülen nesne kümesi ise, onun tüm alt kümeleri olan ∅, {a}, {b}, {c}, {a, b}, {a, c} ve {b, c} kümeleri de sık görülen nesne kümeleridir. Diğerleri için bir yargıya varılamaz yani sık görülen nesne kümesi olmama şansları vardır.
Soru 108
Verilen değerler ışığında bir ilişki kuralının belirlenmesinin ilk adımı aşağıdakilerden hangisidir?
Seçenekler
A
Tüm Sık Görülen Nesne Setlerinin Elde Edilmesi
B
Birleştirme
C
Budama
D
Sık Görülen Nesne Setlerinden Güçlü İlişki Kuralının Elde Edilmesi
E
Veri Setini Eğitme
Açıklama:
İlk aşamada sık görülen tüm nesne setlerinin elde edilmesi gerekir.
Soru 109
Öncül ve sonuç nesne setleri arasındaki korelasyonun belirlenmesine dayanarak hesaplanan değer aşağıdakilerden hangisidir?
Seçenekler
A
Güven
B
Destek
C
Kaldıraç
D
Budama
E
Eşik
Açıklama:
Öncül ve sonuç nesneleri arasındaki ilişkinin hesaplanmasına dayanan yöntem, kaldıraçtır.
Soru 110
İlişki kuralı oluşturulurken nesne sayısı hangi formül ile bulunur?
Seçenekler
A
2n
B
1 - 2n
C
2n + 1
D
2n - 1
E
(2n - 1)/2
Açıklama:
Doğru yanıt D seçeneğinde verilmiştir.
Ünite 6
Soru 1
Karar vericinin içinde bulunduğu karar verme probleminde ortaya çıkabilecek tüm durumları ve karar vericinin karşılaşabileceği tüm senaryoları bir arada gösterebilen bir grafiksel yaklaşıma ne ad verilir?
Seçenekler
A
Karar ağaçları
B
Sınıflandırıcı
C
Ayırıcı
D
Sınıflayıcı
E
Karar verme
Açıklama:
Karar ağaçları, karar vericinin içinde bulunduğu karar verme probleminde ortaya çıkabilecek tüm durumları ve karar vericinin karşılaşabileceği tüm senaryoları bir arada gösterebilen bir grafiksel yaklaşımdır.
Bu nedenle doğru yanıt a) seçeneğidir.
Bu nedenle doğru yanıt a) seçeneğidir.
Soru 2
Karar ağacının oluşturulmasında kök ve iç düğümlerde ayırma işlemini en iyi şekilde gerçekleştirecek olan niteliğin belirlenmesi işlemine ne ad verilir?
Seçenekler
A
Ayırma kriterinin belirlenmesi
B
Durma kriterinin belirlenmesi
C
Yaprak düğümüne ait sınıfın belirlenmesi
D
Sınıflandırma işleminin yapılması
E
Olası karar ağaçlarının oluşturulması
Açıklama:
Karar ağaçlarını, sınıflandırma probleminin çözümlenmesinde kullanırken iki adıma ihtiyaç duyulur. Bu adımlar,
Bu nedenle doğru yanıt a) seçeneğidir.
- Karar ağacının oluşturulması
- Veritabanında yer alan her bir kaydın (ti) sınıflandırmasının yapılması
Bu nedenle doğru yanıt a) seçeneğidir.
Soru 3
Bir kaydı, önceden tanımlanmış çeşitli sınıflardan birine atayan bir modelin uygulanması işlemi aşağıdakilerden hangisidir?
Seçenekler
A
Sınıflandırma
B
Sınıf kestirimi
C
Sınıflayıcı
D
Karar problemi
E
Ayırıcı belirleme
Açıklama:
Sınıflandırma, bir kaydı, önceden tanımlanmış çeşitli sınıflardan birine atayan bir modelin uygulanması işlemi olarak tanımlanabilir. Sınıflandırma yapabilmek için, girdi olarak nitelik değerlerinden oluşan örnek kayıt yığını ve karşılık gelen bir sınıf verilmelidir. Sınıflandırma modeli ise, mevcut olan nitelik değerleri ile yeni bir kaydın sınıfının kestirimini yapar ve sınıflayıcı olarak adlandırılır.
Karar ağaçları, veri madenciliğinde karşılaşılan sınıflandırma problemlerinin çözümü için en sık başvurulan mantıksal yaklaşım yöntemidir.
Bu nedenle doğru yanıt a) seçeneğidir.
Karar ağaçları, veri madenciliğinde karşılaşılan sınıflandırma problemlerinin çözümü için en sık başvurulan mantıksal yaklaşım yöntemidir.
Bu nedenle doğru yanıt a) seçeneğidir.
Soru 4
Bir banka müşteri veritabanında yer alan müşterilerin kredi riskleri kümesi R={iyi, kötü, kötü, iyi, iyi, kötü, iyi, iyi, kötü, iyi} olarak verilmiş olsun. Buna göre C1 iyi sonucunu, C2 kötü sonucunu temsil etmek üzere, risk niteliğinin olasılık dağılımı aşağıdakilerden hangisidir?
Seçenekler
A
PR={6/10, 4/10}
B
PR={4/10, 6/10}
C
PR={10/6, 10/4}
D
PR={10/4, 10/6}
E
PR={6/100, 4/100}
Açıklama:
R={iyi, kötü, kötü, iyi, iyi, kötü, iyi, iyi, kötü, iyi} listesinde 6 adet iyi, 4 adet kötü değeri vardır. C1=iyi, C2=kötü olarak verilmiştir. Bu durumda
PR={6/10, 4/10}
olacaktır.
Bu nedenle doğru yanıt a) seçeneğidir.
PR={6/10, 4/10}
olacaktır.
Bu nedenle doğru yanıt a) seçeneğidir.
Soru 5
Bir banka müşteri veritabanında yer alan BORÇ, GELİR, STATÜ niteliklerine göre müşterinin RİSK durumu belirlenmek istenmektedir. H entropi değeri olmak üzere, BORÇ niteliği ile ayırma yapılması istendiğinde elde edilen kazanç aşağıdaki eşitliklerden hangisi ile hesaplanır?
Seçenekler
A
Kazanç(BORÇ, RİSK) =H(RİSK) - H(BORÇ, RİSK)
B
Kazanç(RİSK, BORÇ) =H(RİSK) - H(RİSK, BORÇ)
C
Kazanç(BORÇ) =H(RİSK) - H(BORÇ)
D
Kazanç(BORÇ, RİSK) =H(RİSK) / H(BORÇ, RİSK)
E
Kazanç(BORÇ, RİSK) =H(RİSK) * H(BORÇ, RİSK)
Açıklama:
T hedef niteliğini X niteliğine göre bölerek elde edilen bilgiyi ölçmek için kazanç ölçütünden yararlanılır ve hesaplama için izleyen eşitlik kullanılır.
Kazanç(X, T) = H(T) ‒ H(X, T)
Bu nedenle doğru yanıt a) seçeneğidir.
Kazanç(X, T) = H(T) ‒ H(X, T)
Bu nedenle doğru yanıt a) seçeneğidir.
Soru 6
Ayırma kritesi olarak kazanç ölçütünden yararlanan; durdurma kriteri olarak tüm kayıtların tek bir sınıfa ait olması veya kazanç ölçütünün sıfırdan büyük olmaması durumunu kullanan; karar ağacına herhangi bir budama uygulamayan; sayısal nitelikleri ve kayıp veriyi işleyemeyen; 1983 yılında Ross Quinlan tarafından önerilen karar ağacı oluşturma algoritması aşağıdakilerden hangisidir?
Seçenekler
A
ID3
B
C4.5
C
CART
D
CHAID
E
QUEST
Açıklama:
ID3 karar ağacı oluşturma algoritması en basit karar ağacı oluşturma algoritmasıdır. Ayırma kriteri olarak kazanç ölçütünden yararlanılmaktadır. Karar ağacının büyümesini durdurma kriteri ise tüm kayıtların tek bir sınıfa ait olması veya kazanç ölçütünün sıfırdan büyük olmaması durumudur. ID3 algoritmasında, karar ağacına herhangi bir budama işlemi uygulanmaz, ek olarak bu algoritma sayısal (ölçüm düzeyi nicel) nitelikleri ve kayıp veriyi işleyememektedir. 1983 yılında Ross Quinlan tarafından önerilmiştir.
Bu nedenle doğru yanıt a) seçeneğidir.
Bu nedenle doğru yanıt a) seçeneğidir.
Soru 7
Bir karar ağacında bir ya da daha fazla dalı çıkartarak, karar ağacını daha basitleştirmek amacıyla, çıkartılmasına karar verilen dalın içerdiği kayıtların, bağlı olduğu üst düğüme dahil edilerek, düğümün yaprak düğüme dönüştürülmesi işlemine ne ad verilir?
Seçenekler
A
Karar ağacı budama
B
Karar ağacı modelini test etme
C
Çapraz doğrulama
D
Eğitim verisi elde etme
E
Maliyet karmaşıklığını azaltma
Açıklama:
Budama bir ya da daha fazla dalı çıkartarak, karar ağacını daha basitleştirmek amacıyla, yaprak düğüm ile değiştirme işlemidir. Bu işlem, çıkartılmasına karar verilen dalın içerdiği kayıtların, bağlı olduğu üst düğüme dahil edilerek, düğümün yaprak düğüme dönüştürülmesine dayanır. Böylece, kestirim hata oranının, ortaya çıkan aşırı uyum (overfitting) sorununun giderilmesi, azaltılması ve sınıflandırma modelinin kalitesinin arttırılması hedeflenir. Kısaca ifade etmek gerekirse, karar ağacının en iyi duruma getirilmesi işlemidir. Budama işlemi, gerekli görülmesi hâlinde, büyümesi önceden belirlenmiş olan durma kriterine göre sonlandırılmış karar ağacına uygulanabileceği gibi, durma kriterini daha esnek tanımlayarak ağacın olabildiğince büyümesi sağlandıktan sonra, en iyi duruma getirmek için de kullanılabilir. Budama, özellikle çok az sayıda kayıt bulunduran yaprak düğümlerin kesilmesi bakımından önemlidir. Ancak, çok fazla budanmış bir karar ağacı ise, örnek uzayı hakkında yeterli bilgi sağlamayacaktır.
Bu nedenle doğru yanıt a) seçeneğidir.
Bu nedenle doğru yanıt a) seçeneğidir.
Soru 8
İkili (binary) karar ağacı yapısından dolayı diğer algoritmalardan farklılık gösteren; ayırma kriteri için Entropi, Gini ve Twoing indekslerinden, karar ağacını budamak için ise maliyet-karmaşıklığı kriterinden faydalananan; yaprak düğümlerinde bir sınıf kestirimi yerine sayısal bir değer kestirimini içeren regresyon ağacını da oluşturulabilmesini sağlayan; 1984 yılında Breiman, Friedman, Olshen ve Stone tarafından önerilen sınıflandırma ve regresyon ağaçları algoritması aşağıdakilerden hangisidir?
Seçenekler
A
CART
B
CHAID
C
QUEST
D
ID3
E
C4.5
Açıklama:
Kısaca CART olarak adlandırılan sınıflandırma ve regresyon ağaçları algoritması, ikili (binary) karar ağacı yapısından dolayı diğer algoritmalardan farklılık göstermektedir. Karar ağacındaki her bir düğüm yanlızca iki dala ayrılır. Ayırma kriteri için Entropi, Gini ve Twoing indekslerinden, karar ağacını budamak için ise maliyet-karmaşıklığı kriterinden faydalanılır. CART algoritmasının önemli bir işlevi ise, yaprak düğümlerinde bir sınıf kestirimi yerine sayısal bir değer kestirimini içeren regresyon ağacının da oluşturulabilmesidir. Bu durumda, ayırma kriteri olarak en küçük kareler sapması kriterine başvurulmaktadır. 1984 yılında Breiman, Friedman, Olshen ve Stone tarafından önerilmiştir.
Bu nedenle doğru yanıt a) seçeneğidir.
Bu nedenle doğru yanıt a) seçeneğidir.
Soru 9
Sınıflandırma ve regresyon ağacı oluşturabilmek için R’de yüklenmesi gereken paket aşağıdakilerden hangisidir?
Seçenekler
A
rpart
B
stats
C
lsa
D
scrime
E
arules
Açıklama:
R ile sınıflandırma ve regresyon ağacı oluşturabilmek için rpart paketinin R’de kurulu olması gerekmektedir. Eğer kurulu değilse, Paketler menüsünden Paket Kur seçeneği seçilerek kurulur. Kurulum bittikten sonra, paketin hafızaya yüklenmesi için, yine aynı menüde bulunan Paket Yükle seçeneği yardımıyla veya library(rpart) komutu yardımıyla rpart paketi hafızaya yüklenebilir.
Bu nedenle doğru yanıt a) seçeneğidir.
Bu nedenle doğru yanıt a) seçeneğidir.
Soru 10
>library(rpart)
>agac<-rpart(formula=RİSK~BORÇ+GELİR+STATÜ,data=veri[,2:5],method=“class”)
>agac
n= 45
node), split, n, loss, yval, (yprob)
* denotes terminal node
1) root 45 22 iyi (0.5111111 0.4888889)
2) STATÜ=ücretli 28 12 iyi (0.5714286 0.4285714)
4) GELİR=düşük 13 4 iyi (0.6923077 0.3076923) *
5) GELİR=yüksek 15 7 kötü (0.4666667 0.5333333) *
3) STATÜ=işveren 17 7 kötü (0.4117647 0.5882353) *
Yukarıda verilen, sınıflandırma ve regresyon ağacı oluşturmak amacıyla kullanılan R komutları kümesinde (*) ile işaretlenen düğümler aşağıdakilerden hangisidir?
>agac<-rpart(formula=RİSK~BORÇ+GELİR+STATÜ,data=veri[,2:5],method=“class”)
>agac
n= 45
node), split, n, loss, yval, (yprob)
* denotes terminal node
1) root 45 22 iyi (0.5111111 0.4888889)
2) STATÜ=ücretli 28 12 iyi (0.5714286 0.4285714)
4) GELİR=düşük 13 4 iyi (0.6923077 0.3076923) *
5) GELİR=yüksek 15 7 kötü (0.4666667 0.5333333) *
3) STATÜ=işveren 17 7 kötü (0.4117647 0.5882353) *
Yukarıda verilen, sınıflandırma ve regresyon ağacı oluşturmak amacıyla kullanılan R komutları kümesinde (*) ile işaretlenen düğümler aşağıdakilerden hangisidir?
Seçenekler
A
Yaprak düğüm
B
Kök düğüm
C
İç düğüm
D
Sınıflayıcı nitelik
E
Ayırıcı düğüm
Açıklama:
Verilen R komutu sonucu komut diziliminin en son satırında yer alan agac değişkeni bize elde edilen sonuçları göstermektedir. Sonuçlara göre, sırasıyla düğüm numarası (node), düğümü yaratan ayırıcı niteliğin tanımı (split), düğümdeki kayıt sayısı (n), düğümdeki kayıp kayıt sayısı (loss), düğüm için yapılan sınıf kestirimi (yval) ve ilgili düğümde yer alan kayıtların sınıflayıcı nitelik değerlerinin olasılıkları (yprob) yer almaktadır. “*” ile işaretlenen düğümler yaprak düğümleri ifade etmektedir.
Bu nedenle doğru yanıt a) seçeneğidir.
Bu nedenle doğru yanıt a) seçeneğidir.
Soru 11
Aşağıdakilerden hangisi veya hangileri nitel verilerde kullanılan ayırma kriteri belirleme metotlarından biridir?
I-Entropi indeksi
II-Twoing indeksi
III-En Küçük Kareler Sapması yöntemi
I-Entropi indeksi
II-Twoing indeksi
III-En Küçük Kareler Sapması yöntemi
Seçenekler
A
I
B
I-II
C
I-III
D
III
E
I-II-III
Açıklama:
Düğümün temsil ettiği, dolayısı ile ayırma işlemini en iyi şekilde gerçekleştirecek olan niteliğin seçilmesi, başka bir ifadeyle ayırma kriterinin belirlenmesi için çeşitli ölçüler geliştirilmiştir. Bu ölçüler, niteliğin veri tipine göre değişiklik göstermektedir. Nitel veri için Entropi İndeksi, Gini İndeksi, Sınıflandırma Hatası İndeksi ve Twoing ölçüleri kullanılır.
Ek olarak Twoing ölçüsünün sıralı ölçekle ölçülmüş değişkenlerin bulunduğu veri için Ordered Twoing bulunmaktadır. Nicel veriler için ise En Küçük Kareler Sapması yöntemi en sık kullanılan ölçüdür.
Doğru cevap B şıkkıdır.
Ek olarak Twoing ölçüsünün sıralı ölçekle ölçülmüş değişkenlerin bulunduğu veri için Ordered Twoing bulunmaktadır. Nicel veriler için ise En Küçük Kareler Sapması yöntemi en sık kullanılan ölçüdür.
Doğru cevap B şıkkıdır.
Soru 12
bir veri yığınındaki düzensizliğin, rassallığın miktarını ölçmek için kullanılan ve en iyi ayırıcı niteliğin seçilmesi için kullanılan ölçü aşağıdakilerden hangisidir?
Seçenekler
A
Sınıflandırma hatası indeksi
B
Gini İndeksi
C
Entropi İndeksi
D
Twoing indeksi
E
En Küçük Kareler Sapması yöntemi
Açıklama:
Entropi, bir veri yığınındaki düzensizliğin, rassallığın miktarını ölçmek için kullanılan bir ölçüdür. Entropisi 0 olan bir grubun tam homojen bir grup, entropisi 1 olan grubun ise tam heterojen olduğu söylenebilir.
Doğru cevap C şıkıdır.
Doğru cevap C şıkıdır.
Soru 13
Karar ağaçlarında her biri bir sınıfı temsil eden ve karar ağacının son bölümü olan düğüm aşağıdakilerden hangisidir?
Seçenekler
A
Yaprak düğüm
B
Kök düğüm
C
Son düğüm
D
İç düğüm
E
T düğümü
Açıklama:
Karar ağaçlarında her biri bir sınıfı temsil eden ve karar ağacının son bölümü olan düğüm yaprak düğümdür.
Doğru cevap A şıkkıdır.
Doğru cevap A şıkkıdır.
Soru 14
Karar ağacı ile sınıflandırma sonucu iki küme oluşmuştur. Birinci kümenin olasılığı 0.57 ise, ikinci kümenin olasılığı kaçtır?
Seçenekler
A
0.57
B
0.33
C
0.27
D
0.43
E
1
Açıklama:
Karar ağaçlarının son düğümleri yani yaprak düğümler sınıfları belirtir. Bu sınıfların olasılık değerleri toplamı 1'dir. Bu nedenle ikinci kümenin olasılık değeri, 1-0.57=0.43
Doğru cevap D şıkkıdır.
Doğru cevap D şıkkıdır.
Soru 15
Sınıflandırma problemlerinde bir karar ağacının oluşturulması için farklı algoritmalardan yararlanılabilir. Aşağıdakilerden hangisi bu algoritmalardan biri değildir?
Seçenekler
A
QUEST
B
SLIQ
C
C4.5
D
ID3
E
ARENA
Açıklama:
Sınıflandırma problemlerinde bir karar ağacının oluşturulması için farklı algoritmalardan yararlanılabilir. Bu algoritmalara örnek olarak ID3, C4.5, CART, CHAID, QUEST, SLIQ, SPRINT ve MARS verilebilir. ARENA bu algoritmalardan biri değildir.
Doğru cevap E şıkkıdır.
Doğru cevap E şıkkıdır.
Soru 16
Karar ağaçlarında kestirim hata oranının, ortaya çıkan aşırı uyum (overfitting) sorununun giderilmesi, azaltılması ve sınıflandırma modelinin kalitesinin arttırılması amacıyla yapılan işleme ne denir?
Seçenekler
A
Çoklu bağıntı azaltma
B
Ağırlıklandırma
C
Serpme
D
Budama
E
Standartlaştırma
Açıklama:
Budama bir ya da daha fazla dalı çıkartarak, karar ağacını daha basitleştirmek amacıyla, yaprak düğüm ile değiştirme işlemidir. Bu işlem, çıkartılmasına karar verilen dalın içerdiği kayıtların, bağlı olduğu üst düğüme dahil edilerek, düğümün yaprak düğüme dönüştürülmesine dayanır. Böylece, kestirim hata oranının, ortaya çıkan aşırı uyum (overfitting) sorununun giderilmesi, azaltılması ve sınıflandırma modelinin kalitesinin arttırılması hedeflenir.
Doğru cevap D şıkkıdır.
Doğru cevap D şıkkıdır.
Soru 17
Çoğu teknikte olduğu gibi karar ağacı oluşturulurken de, veritabanının bir kısmı modeli oluşturmak için kullanılırken, kalan kısım ise oluşturulan modelin test edilebilmesi için ayrılır. Veriyi ikiye ayırmanın amacı, kullanılan karar ağacı algoritmasının ortaya çıkardığı sınıflandırmanın test için saklanan veri ile tekrar denenerek, elde edilen sonuçlar arasında anlamlı bir farklılık olup olmadığının tespit edilmesidir. Aşağıdakilerden hangisi bu amaca yönelik olarak kullanılan tekniklerden biri değildir?
Seçenekler
A
Çapraz-doğrulama tekniği
B
Hold-out tekniği
C
Out-come tekniği
D
Tekrarlı hold-out tekniği
E
Bootstrap tekniği
Açıklama:
Çoğu teknikte olduğu gibi karar ağacı oluşturulurken de, veritabanının bir kısmı modeli oluşturmak için kullanılırken, kalan kısım ise oluşturulan modelin test edilebilmesi için ayrılır. Veriyi ikiye ayırmanın amacı, kullanılan karar ağacı algoritmasının ortaya çıkardığı sınıflandırmanın test için saklanan veri ile tekrar denenerek, elde edilen sonuçlar arasında anlamlı bir farklılık olup olmadığının tespit edilmesidir. Bu tespit, elde edilen modelin performansını ölçen bir tespittir. Bu amaca yönelik olarak kullanılan tekniklerden bazıları hold-out tekniği, tekrarlı hold-out (repeated hold-out) tekniği, çapraz-doğrulama (cross-validation) tekniği ve bootstrap tekniğidir.
Doğru cevap C şıkkıdır.
Doğru cevap C şıkkıdır.
Soru 18
R ile sınıflandırma ve regresyon ağacı oluşturabilmek için hangi paketinin R’de kurulu olması gerekmektedir?
Seçenekler
A
data.frame
B
rpart
C
click
D
treeg
E
svrt
Açıklama:
R ile sınıflandırma ve regresyon ağacı oluşturabilmek için rpart paketinin R’de kurulu olması gerekmektedir.
Soru 19
Karar vericinin içinde bulunduğu karar verme probleminde ortaya çıkabilecek tüm durumları ve karar vericinin karşılaşabileceği tüm senaryoları bir arada gösterebilen bir grafiksel yaklaşıma nedir?
Seçenekler
A
Kavram haritası
B
Histogram
C
Karar ağaçları
D
Çoklu karşılaştırma yöntemleri
E
Bireysel seçim teorisi
Açıklama:
Karar ağaçları, karar vericinin içinde bulunduğu karar verme probleminde ortaya çıkabilecek tüm durumları ve karar vericinin karşılaşabileceği tüm senaryoları bir arada gösterebilen bir grafiksel yaklaşımdır. Karar ağaçlarının bazı avantajları,
• Açıklanmalarının kolay olması,
• İnsani karar almayı diğer yaklaşımlara göre daha iyi yansıtması,
• Grafiksel olarak gösterilebilir olması,
• Uzman olmayan kişiler tarafından da kolaylıkla yorumlanabilir olması,
• Temsili değişkenlere ihtiyaç duymadan nitel değişkenleri de işleyebiliyor olmalarıdır.
Doğru cevap C şıkkıdır.
• Açıklanmalarının kolay olması,
• İnsani karar almayı diğer yaklaşımlara göre daha iyi yansıtması,
• Grafiksel olarak gösterilebilir olması,
• Uzman olmayan kişiler tarafından da kolaylıkla yorumlanabilir olması,
• Temsili değişkenlere ihtiyaç duymadan nitel değişkenleri de işleyebiliyor olmalarıdır.
Doğru cevap C şıkkıdır.
Soru 20
Bir rassal değişkenin seçtiğimiz modele göre parametrelerinin yerine konulması ile elde edilen değere ne denir?
Seçenekler
A
Kestirim
B
Parametre
C
Örnekleme
D
İndeks
E
seçim
Açıklama:
Kestirim, bir rassal değişkenin seçtiğimiz modele göre parametrelerinin yerine konulması ile elde edilen değerdir.
Doğru cevap A şıkkıdır.
Doğru cevap A şıkkıdır.
Soru 21
Aşağıdakilerden hangisi karar ağaçlarının bazı avantajlarından birisi değildir?
Seçenekler
A
Açıklanmalarının kolay olması
B
İnsani karar almayı diğer yaklaşımlara göre daha iyi yansıtması
C
Grafiksel olarak gösterilebilir olması
D
Uzman olmayan kişilerce de kolaylıkla yorumlanabilmesi
E
Sadece nicel değişkenleri işleyebiliyor olmaları
Açıklama:
Karar ağaçlarının bazı avantajları,
• Açıklanmalarının kolay olması,
• İnsani karar almayı diğer yaklaşımlara göre daha iyi yansıtması,
• Grafiksel olarak gösterilebilir olması,
• Uzman olmayan kişiler tarafından da kolaylıkla yorumlanabilir olması,
• Temsili değişkenlere ihtiyaç duymadan nitel değişkenleri de işleyebiliyor olmalarıdır
• Açıklanmalarının kolay olması,
• İnsani karar almayı diğer yaklaşımlara göre daha iyi yansıtması,
• Grafiksel olarak gösterilebilir olması,
• Uzman olmayan kişiler tarafından da kolaylıkla yorumlanabilir olması,
• Temsili değişkenlere ihtiyaç duymadan nitel değişkenleri de işleyebiliyor olmalarıdır
Soru 22
Düğüm ve dal bileşenlerinden oluşan grafiksel tekniğe ne ad verilir?
Seçenekler
A
Karar ağacı
B
Tableau yazılımı
C
Entropi indeksi
D
Ayırma kriteri
E
Gini indeksi
Açıklama:
Sınıflandırma tekniklerinden birisi de karar ağaçlarıdır. Karar ağaçları ile ilgili bazı kavramların detaylı bir şekilde ele alınmasında büyük fayda bulunmaktadır. En basit anlamıyla karar ağacı, düğüm ve dal bileşenlerinden oluşan ve Şekil 6.1’de yer alan ağaca benzer bir yapıya sahip grafiksel bir tekniktir.
Soru 23
Aşağıdakilerden hangisi nitel verilerin ayırma kriterleri için kullanılan indekslerden birisi değildir?
Seçenekler
A
Entropi indeksi
B
Gini indeksi
C
Sınıflandırma hatası indeksi
D
Twoing ölçüleri
E
En küçük kareler sapması yöntemi
Açıklama:
Nitel veri için Entropi İndeksi, Gini İndeksi, Sınıflandırma Hatası İndeksi ve Twoing ölçüleri kullanılır. Ek olarak Twoing ölçüsünün sıralı ölçekle ölçülmüş değişkenlerin bulunduğu veri için Ordered Twoing bulunmaktadır. Nicel veriler için ise En Küçük Kareler Sapması yöntemi en sık kullanılan ölçüdür.
Soru 24
Bir veri yığınındaki düzensizliğin, rassallığın miktarını ölçmek için kullanılan ölçüye ne ad verilir?
Seçenekler
A
Gini indeksi
B
Entropi indeksi
C
Sınıflandırma hatası indeksi
D
Twoing ölçüleri
E
En küçük kareler sapması yöntemi
Açıklama:
Entropi, bir veri yığınındaki düzensizliğin, rassallığın miktarını ölçmek için kullanılan bir ölçüdür.
Soru 25
Nitelik değerlerinin sola ve sağa olmak üzere iki bölüme ayrılması işlemi hangi indeks yoluyla yapılabilmektedir?
Seçenekler
A
Gini indeksi
B
Entropi indeksi
C
Sınıflandırma hatası indeksi
D
Twoing ölçüleri
E
En küçük kareler sağması yöntemi
Açıklama:
Gini indeksi, ikili bölünmeye dayanan bir tekniktir. Bu indeksin hesaplanmasında nitelik değerlerinin sola ve sağa olmak üzere iki bölüme ayrılması işlemi yürütülür.
Soru 26
Aşağıdakilerden hangisi karar ağacı oluşturma algoritmalarından birisi değildir?
Seçenekler
A
CHAID
B
QUEST
C
NAIVE BAYESIAN
D
SLIQ
E
C4.5
Açıklama:
Sınıflandırma problemlerinde bir karar ağacının oluşturulması için farklı algoritmalardan yararlanılabilir. Bu algoritmalara örnek olarak ID3, C4.5, CART, CHAID, QUEST, SLIQ, SPRINT ve MARS verilebilir.
Soru 27
Hangi karar ağacının büyümesini durdurma kriteri, ayrılacak olan kayıtların sayısının belirli bir eşiğin altına düşmesi durumudur?
Seçenekler
A
ID3
B
CART
C
CHAID
D
C4.5
E
SLIQ
Açıklama:
C4.5 algoritması, ID3 algoritmasının geliştirilmiş hâlidir. Ayırma kriteri olarak kazanç oranından yararlanılmaktadır. Karar ağacının büyümesini durdurma kriteri, ayrılacak olan kayıtların sayısının belirli bir eşiğin altına düşmesi durumudur.
Soru 28
Aşağıdakilerden hangisinde yaprak düğümlerinde bir sınıf kestirimi yerine sayısal bir değer kestirimini içeren regresyon ağacı da oluşturulabilmektedir?
Seçenekler
A
ID3
B
C4.5
C
CHAID
D
CART
E
QUEST
Açıklama:
CART algoritmasının önemli bir işlevi ise, yaprak düğümlerinde bir sınıf kestirimi yerine sayısal bir değer kestirimini içeren regresyon ağacı da oluşturabilmesidir.
Soru 29
R'ye excel verisi aktarımı hangi komut yardımıyla yapılmaktadır?
Seçenekler
A
dim()
B
head()
C
read.csv()
D
help()
E
library()
Açıklama:
R’ye aktarılmak için hazır durumdadır. Aktarım için read.csv() fonksiyonundan yararlanılır.
Soru 30
R ile sınıflandırma ve regresyon ağacı oluşturabilmek için hangi paketin kurulu olması gerekmektedir?
Seçenekler
A
digest
B
curl
C
colorspace
D
car
E
rpart
Açıklama:
R ile sınıflandırma ve regresyon ağacı oluşturabilmek için rpart paketinin R’de kurulu olması gerekmektedir.
Soru 31
Günümüzde aşağıdakilerden en çok hangisi 'karşılaşılan seçeneklerin sayısını arttırdığı gibi karar verme işleminin de hızlı bir şekilde yerine getirilmesini' zorunlu hâle getirmektedir?
Seçenekler
A
içgüdüler ve eğilimler
B
hızlı yaşam şartları
C
insan ilişkileri
D
ekonomik şartlar
E
eğitim olanaklarının artması
Açıklama:
Günümüzün hızlı yaşam şartları, karşılaşılan seçeneklerin sayısını arttırdığı gibi karar verme işleminin de hızlı bir şekilde yerine getirilmesini zorunlu hâle getirmektedir.
Soru 32
Karar verme sürecinde tüm seçeneklerin ve bunlara bağlı olarak elde edilecek tüm sonuçların rakamsal olarak takip edilmesi önemlidir. Bu durum pek çok karar verici için aşağıdakilerden hangisine neden olmaktadır?
Seçenekler
A
kararları eleme
B
farklı yöntemlere başvurma
C
daha fazla iş yükü
D
yanlış karar verme
E
karardan şüphe etme
Açıklama:
Karar verme sürecinde, seçeneklerin, alınacak kararı etkileyen etmenlerin çokluğu ve hızlı karar verme gerekliliğinin getirdiği karmaşıklık, karar vericinin vereceği kararlarda olumsuz bir etkiye sahip olabilmektedir. Olası tüm seçeneklerin ve bunlara bağlı olarak elde edilecek tüm sonuçların rakamsal olarak takip edilmesi, pek çok karar vericinin daha fazla iş yüküyle karşılaşmasına neden olabilmektedir.
Soru 33
Aşağıdakilerden hangisi karar ağaçlarının avantajlarından birisi değildir?
Seçenekler
A
Açıklanmalarının kolay olması
B
İnsani karar almayı daha iyi yansıtması
C
Grafiksel olarak gösterilebilir olması
D
Uzmanlar tarafından kullanılmaları
E
Nitel değişkenleri de işleyebiliyor olmaları
Açıklama:
Karar ağaçları, karar vericinin içinde bulunduğu karar verme probleminde ortaya çıkabilecek tüm durumları ve karar vericinin karşılaşabileceği tüm senaryoları bir arada gösterebilen bir grafiksel yaklaşımdır. Karar ağaçlarının bazı avantajları,
• Açıklanmalarının kolay olması,
• İnsani karar almayı diğer yaklaşımlara göre daha iyi yansıtması,
• Grafiksel olarak gösterilebilir olması,
• Uzman olmayan kişiler tarafından da kolaylıkla yorumlanabilir olması,
• Temsili değişkenlere ihtiyaç duymadan nitel değişkenleri de işleyebiliyor olmalarıdır
• Açıklanmalarının kolay olması,
• İnsani karar almayı diğer yaklaşımlara göre daha iyi yansıtması,
• Grafiksel olarak gösterilebilir olması,
• Uzman olmayan kişiler tarafından da kolaylıkla yorumlanabilir olması,
• Temsili değişkenlere ihtiyaç duymadan nitel değişkenleri de işleyebiliyor olmalarıdır
Soru 34
'Bir rassal değişkenin seçtiğimiz modele göre parametrelerinin yerine konulması ile elde edilen değer' olarak ifade edilen kavram aşağıdakilerden hangisidir?
Seçenekler
A
kestirim
B
sınıflandırma
C
girdi
D
nitelik değerler
E
gruplandırma
Açıklama:
Kestirim, bir rassal değişkenin seçtiğimiz modele göre parametrelerinin yerine konulması ile elde edilen değerdir.
Soru 35
'Problemde bulunan her bir nitelik için karar ağacında yer alan ve böylece niteliğin test edilmesini sağlayan' aşağıdakilerden hangisidir?
Seçenekler
A
seçenek
B
düğüm
C
dal
D
sınıf
E
seviye
Açıklama:
Problemde yer alan her bir nitelik için karar ağacında bir düğüm yer alır. Böylece niteliğin test edilmesi garanti altına alınır.
Soru 36
'Karar ağaçlarını sınıflandırma probleminin çözümlenmesinde adımlar kullanılır. Bu süreçte karşılaşılabilecek en önemli sorun, kök ve iç düğümlerde hangi niteliklerin yer alacağının tespit edilmesidir. Olası tüm karar ağaçlarını oluşturmak ve bunların arasından en uygunu seçmek oldukça zordur.' Bu durumda aşağıdakilerden hangisi kullanılır?
Seçenekler
A
kestirim
B
ayırma kriteri
C
değişken tablosu
D
sınıflandırma
E
veritabanı
Açıklama:
Karar ağaçlarını, sınıflandırma probleminin çözümlenmesinde kullanırken iki adıma ihtiyaç duyulur. Bu adımlar,
1. Karar ağacının oluşturulması
2. Veritabanında yer alan her bir kaydın sınıflandırmasının yapılması
Bu süreçte karşılaşılabilecek en önemli sorun, kök ve iç düğümlerde hangi niteliklerin yer alacağının tespit edilmesidir. Çünkü, sınırlı sayıda kayıttan oluşan bir veri yığını için olası tüm karar ağaçlarını oluşturmak ve bunların arasından en uygunu seçmek oldukça zor olacaktır. Bu nitelik, ayırma işlemini gerçekleştiren en iyi nitelik olacaktır ve ayırma kriteri olarak adlandırılır.
1. Karar ağacının oluşturulması
2. Veritabanında yer alan her bir kaydın sınıflandırmasının yapılması
Bu süreçte karşılaşılabilecek en önemli sorun, kök ve iç düğümlerde hangi niteliklerin yer alacağının tespit edilmesidir. Çünkü, sınırlı sayıda kayıttan oluşan bir veri yığını için olası tüm karar ağaçlarını oluşturmak ve bunların arasından en uygunu seçmek oldukça zor olacaktır. Bu nitelik, ayırma işlemini gerçekleştiren en iyi nitelik olacaktır ve ayırma kriteri olarak adlandırılır.
Soru 37
'Bir veri yığınındaki düzensizliğin, rassallığın miktarını ölçmek için kullanılan bir ölçü' olarak tanımlanan aşağıdakilerden hangisinde doğru verilmiştir?
Seçenekler
A
ayırma kriteri
B
kestirim
C
entropi
D
yaprak düğüm
E
karar ağacı
Açıklama:
Entropi, bir veri yığınındaki düzensizliğin, rassallığın miktarını ölçmek için kullanılan bir ölçüdür.
Soru 38
En yüksek kazancı sağlayan nitelik, ayırıcı nitelik olarak tanımlanır. Ancak, Entropi ve Gini indeksleri gibi indeksler belli değerleri çok sayıda bulunduran nitelikleri tercih etme eğilimindedirler. Dolayısıyla ayırma sayısı fazla olacaktır. Bu durumun sonucu aşağıdakilerden hangisini getirir?
Seçenekler
A
Elde edilen veriler kesin sonuçlardır.
B
Elde edilen sınıflar çok küçük sınıflar olacaktır.
C
Araştırmacı güvenilir kestirimlere ulaşır.
D
Ayırmanın ne kadar iyi olduğunu belirlemek için kullanılır.
E
Kazanç oranı ölçütün hesaplanması izleyen eşitlik yardımıyla yürütülür.
Açıklama:
En yüksek kazancı sağlayan nitelik, ayırıcı nitelik olarak tanımlanır. Ancak, Entropi ve Gini indeksleri gibi indeksler belli değerleri çok sayıda bulunduran nitelikleri tercih etme eğilimindedirler. Dolayısıyla ayırma sayısı fazla olacağından elde edilen sınıflar çok küçük sınıflar olacaktır.
Soru 39
Aşağıdakilerden hangisi 'ikili bölünmeye dayanan bir tekniktir ve hesaplanmasında nitelik değerlerinin sola ve sağa olmak üzere iki bölüme ayrılması işlemi' yürütülür?
Seçenekler
A
entropi
B
statü niteliği
C
gini indeksi
D
ikili (binary) ayırma
E
kazanç oranı ölçütü
Açıklama:
Gini indeksi, ikili bölünmeye dayanan bir tekniktir. Bu indeksin hesaplanmasında nitelik değerlerinin sola ve sağa olmak üzere iki bölüme ayrılması işlemi yürütülür.
Soru 40
'En basit karar ağacı oluşturma algoritmasıdır ve ayırma kriteri olarak kazanç ölçütünden yararlanılmaktadır' olarak tanımlanan algoritma aşağıdakilerden hangisinde doğru verilmiştir?
Seçenekler
A
C4.5
B
CART
C
CHAID
D
ID3
E
QUEST
Açıklama:
ID3 algoritması en basit karar ağacı oluşturma algoritmasıdır. Ayırma kriteri olarak kazanç ölçütünden yararlanılmaktadır.
Soru 41
Karar vericinin karşılaştığı bir problem çözümünde olumlu bir sonuca ulaşabilmek için, problemin sunduğu birden fazla olası seçenek içerisinden seçim yapması işlemine verilen isim aşağıdakilerden hangisidir?
Seçenekler
A
Budama
B
Ayırma
C
Yaprak düğüm
D
Kestirim
E
Karar verme
Açıklama:
Karar verme, karar vericinin karşılaştığı bir problem çözümünde olumlu bir sonuca
ulaşabilmek için, problemin sunduğu birden fazla olası seçenek içerisinden seçim yapması işlemidir.
ulaşabilmek için, problemin sunduğu birden fazla olası seçenek içerisinden seçim yapması işlemidir.
Soru 42
Aşağıdakilerden hangisi karar ağaçlarının avantajları arasında yer almaz?
Seçenekler
A
Uzman olmayan kişiler tarafından da kolaylıkla yorumlanabilir olması
B
Grafiksel olarak gösterilebilir olması
C
Açıklanmalarının zor olması
D
Temsili değişkenlere ihtiyaç duymadan nitel değişkenleri de işleyebiliyor
E
İnsani karar almayı diğer yaklaşımlara göre daha iyi yansıtması
Açıklama:
Karar ağaçlarının bazı avantajları,
• Açıklanmalarının kolay olması,
• İnsani karar almayı diğer yaklaşımlara göre daha iyi yansıtması,
• Grafiksel olarak gösterilebilir olması,
• Uzman olmayan kişiler tarafından da kolaylıkla yorumlanabilir olması,
• Temsili değişkenlere ihtiyaç duymadan nitel değişkenleri de işleyebiliyor olmalarıdır
• Açıklanmalarının kolay olması,
• İnsani karar almayı diğer yaklaşımlara göre daha iyi yansıtması,
• Grafiksel olarak gösterilebilir olması,
• Uzman olmayan kişiler tarafından da kolaylıkla yorumlanabilir olması,
• Temsili değişkenlere ihtiyaç duymadan nitel değişkenleri de işleyebiliyor olmalarıdır
Soru 43
Bir rassal değişkenin seçtiğimiz modele göre parametrelerinin yerine konulması ile elde edilen değere verilen isim aşağıdakilerden hangisidir?
Seçenekler
A
Kestirim
B
Karar
C
Problem
D
Kök
E
Yaprak
Açıklama:
Kestirim, bir rassal değişkenin seçtiğimiz modele göre parametrelerinin yerine konulması ile elde edilen değerdir.
Soru 44
Bir kaydı, önceden tanımlanmış çeşitli sınıflardan birine atayan bir modelin uygulanması işlemine verilen isim aşağıdakilerden hangisidir?
Seçenekler
A
Kestirim
B
Sınıflandırma
C
Karar verici
D
Karar verme
E
Yaprak düğüm
Açıklama:
Sınıflandırma, bir kaydı, önceden tanımlanmış çeşitli sınıflardan birine atayan bir modelin uygulanması işlemi olarak tanımlanabilir.
Soru 45
Karar ağacını sonlandıran düğüm aşağıdakilerden hangisidir?
Seçenekler
A
Yaprak düğüm
B
Kök düğüm
C
Mevcut düğüm
D
Kör düğüm
E
İç düğüm
Açıklama:
Kök ve iç düğüm bir karar ağacını başlatan ve büyüten düğümler, yaprak düğüm ise dallanmayı sonlandıran düğümdür.
Soru 46
Karar ağacının başlangıcını oluşturan ilk düğüme verilen isim aşağıdakilerden hangisidir?
Seçenekler
A
İç düğüm
B
Yaprak düğüm
C
Karar düğüm
D
Kök düğüm
E
Kötü düğüm
Açıklama:
Karar ağacının başlangıcını oluşturan ilk düğüm kök düğüm olarak adlandırılır.
Soru 47
Aşağıdakilerden hangisi 'Ayırma kriteri'nin belirlenmesi için kullanılan ölçüler arasında yer almaz?
Seçenekler
A
Entropi İndeksi
B
Sınıflandırma ölçüleri
C
Gini İndeksi
D
Twoing ölçüleri
E
Sınıflandırma Hatası İndeksi
Açıklama:
Ayırma kriterinin belirlenmesi için çeşitli ölçüler geliştirilmiştir. Bu ölçüler, niteliğin veri tipine göre değişiklik göstermektedir. Nitel veri için Entropi İndeksi, Gini İndeksi, Sınıflandırma Hatası İndeksi ve Twoing ölçüleri kullanılır
Soru 48
Bir veri yığınındaki düzensizliğin, rassallığın miktarını ölçmek için kullanılan ölçü ismi aşağıdakilerden hangisidir?
Seçenekler
A
Gini
B
Ayırma
C
Yaprak
D
Kök
E
Entropi
Açıklama:
Entropi, bir veri yığınındaki düzensizliğin, rassallığın miktarını ölçmek için kullanılan
bir ölçüdür.
bir ölçüdür.
Soru 49
T hedef niteliğini X niteliğine göre bölerek elde edilen bilgiyi ölçmek için hangi ölçüt aşağıda verilmiştir?
Seçenekler
A
Sınıflandırma Hatası İndeksi
B
Küçük Kareler Sapması
C
Kazanç ölçütü
D
Gini İndeksi
E
Entropi İndeksi
Açıklama:
T hedef niteliğini X niteliğine göre bölerek elde edilen bilgiyi ölçmek için kazanç ölçütünden yararlanılır ve hesaplama için izleyen eşitlik kullanılır.
Soru 50
Aşağıdakilerden hangisi sınıflandırma problemlerinde bir karar ağacının oluşturulması için yararlanılan algoritmalardan değildir?
Seçenekler
A
SPRINT
B
BORC
C
QUEST
D
CART
E
MARS
Açıklama:
Sınıflandırma problemlerinde bir karar ağacının oluşturulması için farklı algoritmalardan yararlanılabilir. Bu algoritmalara örnek olarak ID3, C4.5, CART, CHAID, QUEST, SLIQ, SPRINT ve MARS verilebilir.
Soru 51
- Açıklanmalarının kolay olması
- İnsani karar almayı diğer yaklaşımlara göre daha iyi yansıtması
- Grafiksel olarak gösterilebilir olması
- Problem çözümünde olumsuz sonuca ulaşılması
Seçenekler
A
Yalnız IV
B
I - II
C
III - IV
D
I - II - III
E
I - II - III - IV
Açıklama:
Karar ağaçlarının bazı avantajları:
• Açıklanmalarının kolay olması,
• İnsani karar almayı diğer yaklaşımlara göre daha iyi yansıtması,
• Grafiksel olarak gösterilebilir olması,
• Uzman olmayan kişiler tarafından da kolaylıkla yorumlanabilir olması,
• Temsili değişkenlere ihtiyaç duymadan nitel değişkenleri de işleyebiliyor olmalarıdır.
• Açıklanmalarının kolay olması,
• İnsani karar almayı diğer yaklaşımlara göre daha iyi yansıtması,
• Grafiksel olarak gösterilebilir olması,
• Uzman olmayan kişiler tarafından da kolaylıkla yorumlanabilir olması,
• Temsili değişkenlere ihtiyaç duymadan nitel değişkenleri de işleyebiliyor olmalarıdır.
Soru 52
".................., bir rassal değişkenin seçtiğimiz modele göre parametrelerinin yerine konulması ile elde edilen değerdir."
Metinde verilen boşluğa aşağıdaki seçeneklerden hangisi getirilmelidir?
Metinde verilen boşluğa aşağıdaki seçeneklerden hangisi getirilmelidir?
Seçenekler
A
Kestirim
B
Karar verici
C
Karar verme
D
Sınıflama
E
Sınıflayıcı
Açıklama:
Kestirim, bir rassal değişkenin seçtiğimiz modele göre parametrelerinin yerine konulması ile elde edilen değerdir.
Soru 53
"Kök ve .............. düğüm bir karar ağacını başlatan ve büyüten düğümler, ................... düğüm ise dallanmayı sonlandıran düğümdür."
Metinde verilen boşluklara aşağıdaki seçeneklerden hangisi getirilmelidir?
Metinde verilen boşluklara aşağıdaki seçeneklerden hangisi getirilmelidir?
Seçenekler
A
yaprak - iç
B
iç - yaprak
C
dış - iç
D
yaprak - dış
E
dış - yaprak
Açıklama:
Problemde yer alan her bir nitelik için karar ağacında bir düğüm yer alır. Böylece niteliğin test edilmesi garanti altına alınır. Bir düğümden ayrılan dallar ise o düğümdeki testin tüm olası sonuçlarının her birine karşılık gelmektedir. Karar ağacının başlangıcını oluşturan ilk düğüm kök düğüm olarak adlandırılır. Karar ağacı bu düğümden başlayarak, problemin içerisindeki tüm karar seçeneklerini içerecek şekilde düğümlerin mantık sırasına göre eklenmesiyle tamamlanır. Son düğüm yaprak düğüm, diğer düğümler ise iç düğüm olarak adlandırılır. Yaprak düğümlerin her biri bir sınıfı temsil eder. Kimi sınıflandırma problemlerinde basit yapılı bir karar ağacı oluşurken, problemdeki nitelik sayısına bağlı olarak karar ağacı da karmaşık bir yapıya sahip olacaktır.
Kök ve iç düğüm bir karar ağacını başlatan ve büyüten düğümler, yaprak düğüm ise dallanmayı sonlandıran düğümdür.
Kök ve iç düğüm bir karar ağacını başlatan ve büyüten düğümler, yaprak düğüm ise dallanmayı sonlandıran düğümdür.
Soru 54
- En Küçük Kareler Sapması
- Entropi İndeksi
- Gini İndeksi
- Sınıflandırma Hatası İndeksi
Seçenekler
A
Yalnız I
B
Yalnız II
C
II - III
D
II - III - IV
E
I - II - III - IV
Açıklama:
Düğümün temsil ettiği, dolayısı ile ayırma işlemini en iyi şekilde gerçekleştirecek olan niteliğin seçilmesi, başka bir ifadeyle ayırma kriterinin belirlenmesi için çeşitli ölçüler geliştirilmiştir. Bu ölçüler, niteliğin veri tipine göre değişiklik göstermektedir. Nitel veri için Entropi İndeksi, Gini İndeksi, Sınıflandırma Hatası İndeksi ve Twoing ölçüleri kullanılır. Ek olarak Twoing ölçüsünün sıralı ölçekle ölçülmüş değişkenlerin bulunduğu veri için Ordered Twoing bulunmaktadır. Nicel veriler için ise En Küçük Kareler Sapması yöntemi en sık kullanılan ölçüdür. Bu ünitenin izleyen kesiminde ilgili ölçütlerden Entropi İndeksi ve Gini İndeksi ayrıntılı olarak incelenmiştir.
Soru 55
"En yüksek kazancı sağlayan nitelik, ayırıcı nitelik olarak tanımlanır. Ancak, Entropi ve Gini indeksleri gibi indeksler belli değerleri çok sayıda bulunduran nitelikleri tercih etme eğilimindedirler. Dolayısıyla ayırma sayısı fazla olacağından elde edilen sınıflar çok küçük sınıflar olacaktır. Bu durum araştırmacının güvenilir kestirimler yapmasını mümkün kılamayabilir. Benzer durumlarda kullanılan stratejilerden bir tanesi sadece ikili (binary) ayırma yapacak şekilde testler oluşturmak veya ayırmanın ne kadar iyi olduğunu belirlemek için kullanılan .............................. ölçütünü kullanmaktır."
Metinde verilen boşluğa aşağıdaki seçeneklerden hangisi getirilmelidir?
Metinde verilen boşluğa aşağıdaki seçeneklerden hangisi getirilmelidir?
Seçenekler
A
rassallık miktarı
B
kazanç oranı
C
ordered twoing
D
entropi indeksi
E
bölünme blgisi
Açıklama:
En yüksek kazancı sağlayan nitelik, ayırıcı nitelik olarak tanımlanır. Ancak, Entropi ve Gini indeksleri gibi indeksler belli değerleri çok sayıda bulunduran nitelikleri tercih etme eğilimindedirler. Dolayısıyla ayırma sayısı fazla olacağından elde edilen sınıflar çok küçük sınıflar olacaktır. Bu durum araştırmacının güvenilir kestirimler yapmasını mümkün kılamayabilir. Benzer durumlarda kullanılan stratejilerden bir tanesi sadece ikili (binary) ayırma yapacak şekilde testler oluşturmak veya ayırmanın ne kadar iyi olduğunu belirlemek için kullanılan kazanç oranı ölçütünü kullanmaktır.
Soru 56
- CART
- CHAID
- ANOVA
- LEVENE
- MARS
Seçenekler
A
Yalnız V
B
IV - V
C
III - IV
D
I - II - V
E
I - II - III - IV
Açıklama:
Sınıflandırma problemlerinde bir karar ağacının oluşturulması için farklı algoritmalardan yararlanılabilir. Bu algoritmalara örnek olarak ID3, C4.5, CART, CHAID, QUEST, SLIQ, SPRINT ve MARS verilebilir. ANOVA ve LEVENE gibi testler algoritma değil analiz türleridir.
Soru 57
Aşağıdaki seçeneklerden hangileri budama süreci için geliştirilen yöntemlerden biri değildir?
Seçenekler
A
aşırı uyum (overfitting)
B
kötümser hata (pessimistic error)
C
hata-karmaşıklığı (error complexity)
D
kritik değer (critical value)
E
azaltılmış hata (reduced error)
Açıklama:
Budama süreci için çeşitli yöntemler geliştirilmiştir. Bu yöntemlerden bazıları maliyet karmaşıklığı (cost complexity), kötümser hata (pessimistic error), hata-karmaşıklığı (error complexity), kritik değer (critical value), azaltılmış hata (reduced error), en küçükhata (minimum-error) budama yöntemleridir.
Soru 58
- .................., veritabanının, araştırmacının takdirinde olan bir oranda (yarı yarıya veya 1/3’e 2/3 gibi) iki ayrık gruba bölünerek, eğitim ve test verisi olarak ele alınmasına dayanır.
- ....................., veritabanı iki eşit gruba bölünür ve birinci grup eğitim verisi olurken ikinci grup test verisi olarak ele alınır. Daha sonra, grupların rolleri değiştirilir. Modelin hatası, bu iki denemenin hataları toplamına eşittir.
Seçenekler
A
(a) çapraz doğrulama yöntemi - (b) tekrarlı hold out tekniği
B
(a) tekrarlı hold out tekniği - (b) hold out tekniği
C
(a) hold out tekniği - (b) tekrarlı hold out tekniği
D
(a) çapraz doğrulama yöntemi - (b) hold out tekniği
E
(a) hold out tekniği - (b) çapraz doğrulama yöntemi
Açıklama:
Hold-out tekniği, veritabanının, araştırmacının takdirinde olan bir oranda (yarı yarıya veya 1/3’e 2/3 gibi) iki ayrık gruba bölünerek, eğitim ve test verisi olarak ele alınmasına dayanır. Böylece sınıflandırmanın doğruluğu, eğitim verisi ile elde edilen karar ağacı modelinin test verisi üzerindeki doğruluğuna göre tahmin edilebilir.
Çapraz-doğrulama yönteminde ise, veritabanı iki eşit gruba bölünür ve birinci grup eğitim verisi olurken ikinci grup test verisi olarak ele alınır. Daha sonra, grupların rolleri değiştirilir. Modelin hatası, bu iki denemenin hataları toplamına eşittir. 2-katlı çapraz doğrulama olarak da adlandırılan bu yöntem, k-katlı olarak genelleştirilebilir. Bu durumda, veritabanı eşit büyüklükte k tane gruba bölünür. Gruplardan bir tanesi test verisi olarak seçilirken, diğer gruplar eğitim verisi olarak ele alınır ve k grubun her birisi bir kez test verisi olacak şekilde bu işlem tekrarlanır. Toplam hata, tekrarların hataları toplamına eşit kabul edilir.
Çapraz-doğrulama yönteminde ise, veritabanı iki eşit gruba bölünür ve birinci grup eğitim verisi olurken ikinci grup test verisi olarak ele alınır. Daha sonra, grupların rolleri değiştirilir. Modelin hatası, bu iki denemenin hataları toplamına eşittir. 2-katlı çapraz doğrulama olarak da adlandırılan bu yöntem, k-katlı olarak genelleştirilebilir. Bu durumda, veritabanı eşit büyüklükte k tane gruba bölünür. Gruplardan bir tanesi test verisi olarak seçilirken, diğer gruplar eğitim verisi olarak ele alınır ve k grubun her birisi bir kez test verisi olacak şekilde bu işlem tekrarlanır. Toplam hata, tekrarların hataları toplamına eşit kabul edilir.
Soru 59
- csv (comma seperated values) türü dosya ile veri aktarımı
- kopyala-yapıştır yöntemi
- veritabanı bağlantısı ile veri aktarımı
- library (rpart) komutu yardımıyla
Seçenekler
A
Yalnız IV
B
Yalnız III
C
III - IV
D
I - II - III
E
I - II - III - IV
Açıklama:
R’ye veri aktarmanın birçok yöntemi mevcuttur. Bu yöntemlerden bazıları csv (comma seperated values) türü dosya ile veri aktarımı, kopyala-yapıştır yöntemi ve veritabanı bağlantısı ile veri aktarım yöntemidir.
Soru 60
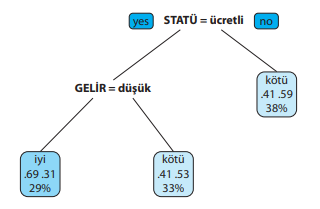 Görseldeki grafiğe başlık olarak aşağıdaki seçeneklerden hangisi getirilmelidir?
Görseldeki grafiğe başlık olarak aşağıdaki seçeneklerden hangisi getirilmelidir?Seçenekler
A
R ile Çizilen Sınıflandırma Ağacı Grafiği
B
Veri Tabanı İçin Oluşan Üç Sınıflı Karar Ağacı
C
prp Fonksiyonu ile Sınıflandırma Ağacı Grafiği
D
fancyRpartPlot Fonksiyonu ile Sınıflandırma Ağacı Grafiği
E
Sınıflandırma Ağacındaki Kayıtların Sınıflayıcı Niteliğe Göre Dağılımı
Açıklama:
Metnin başlığı "prp Fonksiyonu ile Sınıflandırma Ağacı Grafiği" olmalıdır.
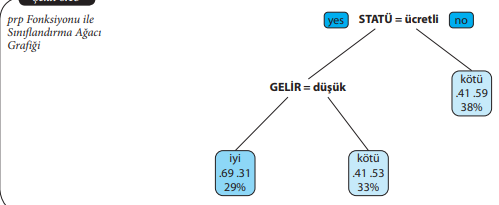
Soru 61
Karar probleminin zaman içerisinde doğuracağı sonuçlardan etkilenen sorumlu kişiye ne ad verilir?
Seçenekler
A
Karar verici
B
Veri Madencisi
C
Analizci
D
Sınıflandırıcı
E
Katılımcı
Açıklama:
Karar probleminin zaman içerisinde doğuracağı sonuçlardan etkilenen sorumlu kişiye karar verici adı verilir.
Soru 62
Aşağıdakilerden hangisi karar ağaçlarının bazı avantajları içinde yer almaz?
Seçenekler
A
Açıklanmalarının kolay olması
B
Tüm değişkenlerin göz ardı edilmesi
C
İnsani karar almayı diğer yaklaşımlara göre daha iyi yansıtması
D
Grafiksel olarak gösterilebilir olması
E
Uzman olmayan kişiler tarafından da kolaylıkla yorumlanabilir olması
Açıklama:
Karar ağaçlarının bazı avantajları,
• Açıklanmalarının kolay olması,
• İnsani karar almayı diğer yaklaşımlara göre daha iyi yansıtması,
• Grafiksel olarak gösterilebilir olması,
• Uzman olmayan kişiler tarafından da kolaylıkla yorumlanabilir olması,
• Temsili değişkenlere ihtiyaç duymadan nitel değişkenleri de işleyebiliyor olmalarıdır.
• Açıklanmalarının kolay olması,
• İnsani karar almayı diğer yaklaşımlara göre daha iyi yansıtması,
• Grafiksel olarak gösterilebilir olması,
• Uzman olmayan kişiler tarafından da kolaylıkla yorumlanabilir olması,
• Temsili değişkenlere ihtiyaç duymadan nitel değişkenleri de işleyebiliyor olmalarıdır.
Soru 63
Bir rassal değişkenin seçtiğimiz modele göre parametrelerinin yerine konulması ile elde edilen değerine ne ad verilir?
Seçenekler
A
Veri
B
Karar
C
Kestirim
D
Sınıflandırma
E
Kök Düğüm
Açıklama:
Kestirim, bir rassal değişkenin seçtiğimiz modele göre parametrelerinin yerine konulması ile elde edilen değerdir.
Soru 64
Aşağıdakilerden hangisi en basit anlamıyla düğüm ve dal bileşenlerinden oluşan grafiksel bir tekniği niteler?
Seçenekler
A
Sınıflandırma
B
Karar Verici
C
Veri
D
Karar ağacı
E
Kestirim
Açıklama:
En basit anlamıyla karar ağacı, düğüm ve dal bileşenlerinden oluşan ve Şekil 6.1’de yer alan ağaca benzer bir yapıya sahip grafiksel bir tekniktir.
Soru 65
Aşağıda verilmiş seçeneklerden hangisi bir kaydı, önceden tanımlanmış çeşitli sınıflardan birine atayan bir modelin uygulanması işlemi olarak tanımlar?
Seçenekler
A
Kestirim
B
Veri
C
Risk
D
Değişken
E
Sınıflandırma
Açıklama:
Sınıflandırma, bir kaydı, önceden tanımlanmış çeşitli sınıflardan birine atayan bir modelin uygulanması işlemi olarak tanımlanabilir.
Soru 66
Kök ve iç düğüm bir karar ağacını başlatan ve büyüten düğümler, ____________ düğüm ise dallanmayı sonlandıran düğümdür. Aşağıdakilerden hangisi boşluğun yerine gelecek doğru tanımdır?
Seçenekler
A
Yaprak
B
Kestirim
C
Veri
D
Sınıflandırma
E
Statü
Açıklama:
Kök ve iç düğüm bir karar ağacını başlatan ve büyüten düğümler, yaprak düğüm ise dallanmayı sonlandıran düğümdür.
Soru 67
Aşağıdakilerden hangisi karar ağaçlarının, sınıflandırma probleminin çözümlenmesinde kullanırken gereksinim duyduğu adımlardan biridir?
Seçenekler
A
İnsani karar almayı, diğer yaklaşımlara göre daha iyi yansıtması
B
Veritabanında yer alan her bir kaydın (ti) sınıflandırmasının yapılması
C
Açıklanmalarının kolay olması
D
Grafiksel olarak gösterilebilir olması
E
Uzman olmayan kişiler tarafından da kolaylıkla yorumlanabilir olması
Açıklama:
Karar ağaçlarını, sınıflandırma probleminin çözümlenmesinde kullanırken iki adıma ihtiyaç duyulur. Bu adımlar,
1. Karar ağacının oluşturulması
2. Veritabanında yer alan her bir kaydın (ti) sınıflandırmasının yapılması
1. Karar ağacının oluşturulması
2. Veritabanında yer alan her bir kaydın (ti) sınıflandırmasının yapılması
Soru 68
Düğümün temsil ettiği, dolayısı ile ayırma işlemini en iyi şekilde gerçekleştirecek olan niteliğin seçilmesi, başka bir ifadeyle ayırma kriterinin belirlenmesi için çeşitli ölçüler geliştirilmiştir. Bu ölçüler, niteliğin veri tipine göre değişiklik göstermektedir. Aşağıdakilerden hangisi nitel veri için kullanılan ölçülerden biri değildir?
Seçenekler
A
Entropi İndeksi
B
Gini İndeksi
C
Zaman indeksi
D
Sınıflandırma Hatası İndeksi
E
Twoing Ölçüsü
Açıklama:
Düğümün temsil ettiği, dolayısı ile ayırma işlemini en iyi şekilde gerçekleştirecek olan niteliğin seçilmesi, başka bir ifadeyle ayırma kriterinin belirlenmesi için çeşitli ölçüler geliştirilmiştir. Bu ölçüler, niteliğin veri tipine göre değişiklik göstermektedir. Nitel veri için Entropi İndeksi, Gini İndeksi, Sınıflandırma Hatası İndeksi ve Twoing ölçüleri kullanılır.
Soru 69
Aşağıdakilerden hangisi bir veri yığınındaki düzensizliğin, rassallığın miktarını ölçmek için kullanılan bir ölçüdür?
Seçenekler
A
Risk
B
Twoing
C
Sınıflandırma Hatası
D
Entropi
E
Gini
Açıklama:
Entropi, bir veri yığınındaki düzensizliğin, rassallığın miktarını ölçmek için kullanılan bir ölçüdür.
Soru 70
Aşağıda yer alan algoritmalardan hangisinde oluşturulan karar ağacına budama uygulanmaz ve kayıp verinin söz konusu olması durumunda hepsini tek bir geçerli kategori olarak dikkate alarak işlem yürütülür?
Seçenekler
A
ID3
B
C4.5
C
CART
D
QUEST
E
CHAID
Açıklama:
CHAID algoritmasında, her girdi niteliği için, hedef niteliğe göre en az anlamlılıktaki farka sahip değer çiftleri bulur. CHAID algoritmasında, anlamlı olarak adlandırılan fark, istatistiksel bir testten elde edilen değeri ile ölçülür.
Soru 71
metin çıktılarının uzunluğunu düzenleyen parametre aşağıdakilerden hangisidir?
Seçenekler
A
faclen
B
rpart
C
prp()
D
rpart.plot
E
rattle
Açıklama:
faclen parametresi metin çıktılarının uzunluğunu düzenlemektedir ve
“0” değeri, metin çıktıların kısaltılmayacağını belirtmektedir
Doğru cevap A
“0” değeri, metin çıktıların kısaltılmayacağını belirtmektedir
Doğru cevap A
Soru 72
R ile elde edilen sınıflandırma ağacı modeli biraz daha detaylı incelenmek istenirse hangi fonksiyondan yararlanılır?
Seçenekler
A
text()
B
summary()
C
plot()
D
rpart()
E
prp()
Açıklama:
R ile elde edilen sınıflandırma ağacı modeli biraz daha detaylı incelenmek istenirse summary() fonksiyonundan yararlanılır.
Doğru yanıt B
Doğru yanıt B
Soru 73
işletmelerde iç veri kaynakları ile dış veri kaynaklarının birleştirilmesi ve
düzenlenmesi ile oluşturulmuş, üzerinde veri madenciliği işlemlerinin gerçekleştirileceği
veriyi sağlayan daha geniş ve özel veritabanlarına verilen isim aşağıdakilerden hangisidir?
düzenlenmesi ile oluşturulmuş, üzerinde veri madenciliği işlemlerinin gerçekleştirileceği
veriyi sağlayan daha geniş ve özel veritabanlarına verilen isim aşağıdakilerden hangisidir?
Seçenekler
A
Örüntü Tanıma
B
İstatistik
C
Veritabanı
Sistemleri
Sistemleri
D
Veri ambarı
E
Görselleştirme
Açıklama:
Veri ambarı işletmelerde
iç veri kaynakları ile dış veri
kaynaklarının birleştirilmesi ve
düzenlenmesi ile oluşturulmuş,
üzerinde veri madenciliği
işlemlerinin gerçekleştirileceği
veriyi sağlayan daha geniş ve özel
veritabanlarına verilen isimdir.
Doğru Yanıt D
iç veri kaynakları ile dış veri
kaynaklarının birleştirilmesi ve
düzenlenmesi ile oluşturulmuş,
üzerinde veri madenciliği
işlemlerinin gerçekleştirileceği
veriyi sağlayan daha geniş ve özel
veritabanlarına verilen isimdir.
Doğru Yanıt D
Soru 74
Karar ağacının başlangıcını oluşturan ilk düğüm ismi aşağıdakilerden hangisidir?
Seçenekler
A
dış düğüm
B
iç düğüm
C
dallar
D
yaprak düğüm
E
kök düğüm
Açıklama:
Karar ağacının başlangıcını
oluşturan ilk düğüm kök düğüm olarak adlandırılır. Karar ağacı bu düğümden başlayarak, problemin içerisindeki tüm karar seçeneklerini içerecek şekilde düğümlerin mantık
sırasına göre eklenmesiyle tamamlanır. Son düğüm yaprak düğüm, diğer düğümler ise iç
düğüm olarak adlandırılır. Yaprak düğümlerin her biri bir sınıfı temsil eder. Kimi sınıflandırma problemlerinde basit yapılı bir karar ağacı oluşurken, problemdeki nitelik sayısına
bağlı olarak karar ağacı da karmaşık bir yapıya sahip olacaktır.
doğru yanıt E
oluşturan ilk düğüm kök düğüm olarak adlandırılır. Karar ağacı bu düğümden başlayarak, problemin içerisindeki tüm karar seçeneklerini içerecek şekilde düğümlerin mantık
sırasına göre eklenmesiyle tamamlanır. Son düğüm yaprak düğüm, diğer düğümler ise iç
düğüm olarak adlandırılır. Yaprak düğümlerin her biri bir sınıfı temsil eder. Kimi sınıflandırma problemlerinde basit yapılı bir karar ağacı oluşurken, problemdeki nitelik sayısına
bağlı olarak karar ağacı da karmaşık bir yapıya sahip olacaktır.
doğru yanıt E
Soru 75
karar vericinin karşılaştığı bir problem çözümünde olumlu bir sonuca
ulaşabilmek için, problemin sunduğu birden fazla olası seçenek içerisinden seçim yapması işlemine ne ad verilir?
ulaşabilmek için, problemin sunduğu birden fazla olası seçenek içerisinden seçim yapması işlemine ne ad verilir?
Seçenekler
A
karar verme
B
karar verici
C
karar ağaçları
D
kestirim
E
yaprak düğüm
Açıklama:
Karar verme, karar vericinin
karşılaştığı bir problem
çözümünde olumlu bir sonuca
ulaşabilmek için, problemin
sunduğu birden fazla olası
seçenek içerisinden seçim yapması
işlemidir.
doğru yanıt A
karşılaştığı bir problem
çözümünde olumlu bir sonuca
ulaşabilmek için, problemin
sunduğu birden fazla olası
seçenek içerisinden seçim yapması
işlemidir.
doğru yanıt A
Soru 76
bir rassal değişkenin seçtiğimiz modele göre parametrelerinin yerine konulması
ile elde edilen değere ne ad verilir?
ile elde edilen değere ne ad verilir?
Seçenekler
A
kazanç ölçütü
B
Karar verme
C
karar verici
D
yaprak düğüm
E
kestirim
Açıklama:
Kestirim, bir rassal değişkenin
seçtiğimiz modele göre
parametrelerinin yerine konulması
ile elde edilen değerdir.
doğru cevap E
seçtiğimiz modele göre
parametrelerinin yerine konulması
ile elde edilen değerdir.
doğru cevap E
Soru 77
banka müşteri veritabanında yer alan müşterilerin kredi riskleri kümesi 30 olumlu karardan ve 20 olumsuz karardan oluşsun, o halde riskin entropisi aşağıdakilerden hangisidir?
Seçenekler
A
0.3065
B
-0.6730
C
-0.9163
D
-0.5108
E
0.6730
Açıklama:
olumlu=3/5 olumsuz=2/5
entropy=-(3/5*log(3/5)+2/5*log(2/5))=0.6730
doğru yanıt E
entropy=-(3/5*log(3/5)+2/5*log(2/5))=0.6730
doğru yanıt E
Soru 78
en basit karar ağacı oluşturma algoritması aşağıdakilerden hangisidir?
Seçenekler
A
ID3
B
C4.5
C
CART
D
CHAID
E
QUEST
Açıklama:
ID3 algoritması en basit karar ağacı oluşturma algoritmasıdır. Ayırma kriteri olarak
kazanç ölçütünden yararlanılmaktadır. Karar ağacının büyümesini durdurma kriteri ise
tüm kayıtların tek bir sınıfa ait olması veya kazanç ölçütünün sıfırdan büyük olmaması
durumudur. ID3 algoritmasında, karar ağacına herhangi bir budama işlemi uygulanmaz,
ek olarak bu algoritma sayısal (ölçüm düzeyi nicel) nitelikleri ve kayıp veriyi işleyememektedir. 1983 yılında Ross Quinlan tarafından önerilmiştir.
doğru yanıt A
kazanç ölçütünden yararlanılmaktadır. Karar ağacının büyümesini durdurma kriteri ise
tüm kayıtların tek bir sınıfa ait olması veya kazanç ölçütünün sıfırdan büyük olmaması
durumudur. ID3 algoritmasında, karar ağacına herhangi bir budama işlemi uygulanmaz,
ek olarak bu algoritma sayısal (ölçüm düzeyi nicel) nitelikleri ve kayıp veriyi işleyememektedir. 1983 yılında Ross Quinlan tarafından önerilmiştir.
doğru yanıt A
Soru 79
her girdi niteliği için, hedef
niteliğe göre en az anlamlılıktaki farka sahip değer çiftleri bulunan algoritma aşağıdakilerden hangisidir?
niteliğe göre en az anlamlılıktaki farka sahip değer çiftleri bulunan algoritma aşağıdakilerden hangisidir?
Seçenekler
A
CHAID
B
ID3
C
CART
D
QUEST
E
SLIQ
Açıklama:
CHAID algoritması ilk olarak sayısal olmayan (ölçüm düzeyi sınıflayıcı) nitelikleri işleyebilecek şekilde geliştirilmiştir. CHAID algoritmasında, her girdi niteliği için, hedef
niteliğe göre en az anlamlılıktaki farka sahip değer çiftleri bulur. CHAID algoritmasında, anlamlı olarak adlandırılan fark, istatistiksel bir testten elde edilen değeri ile ölçülür.
doğru yanı A
niteliğe göre en az anlamlılıktaki farka sahip değer çiftleri bulur. CHAID algoritmasında, anlamlı olarak adlandırılan fark, istatistiksel bir testten elde edilen değeri ile ölçülür.
doğru yanı A
Soru 80
..... tekniği, veritabanının, araştırmacının takdirinde olan bir oranda (yarı yarıya
veya 1/3’e 2/3 gibi) iki ayrık gruba bölünerek, eğitim ve test verisi olarak ele alınmasına
dayanır. Boş yere aşağıdakilerden hangisi gelmelidir?
veya 1/3’e 2/3 gibi) iki ayrık gruba bölünerek, eğitim ve test verisi olarak ele alınmasına
dayanır. Boş yere aşağıdakilerden hangisi gelmelidir?
Seçenekler
A
kestirim hata oranı
B
aşırı uyum
C
cross-validation
D
Hold- out
E
bootstrap
Açıklama:
Hold-out tekniği, veritabanının, araştırmacının takdirinde olan bir oranda (yarı yarıya
veya 1/3’e 2/3 gibi) iki ayrık gruba bölünerek, eğitim ve test verisi olarak ele alınmasına
dayanır. Böylece sınıflandırmanın doğruluğu, eğitim verisi ile elde edilen karar ağacı modelinin test verisi üzerindeki doğruluğuna göre tahmin edilebilir
doğru yanıt D
veya 1/3’e 2/3 gibi) iki ayrık gruba bölünerek, eğitim ve test verisi olarak ele alınmasına
dayanır. Böylece sınıflandırmanın doğruluğu, eğitim verisi ile elde edilen karar ağacı modelinin test verisi üzerindeki doğruluğuna göre tahmin edilebilir
doğru yanıt D
Soru 81
Karar vericinin karşılaştığı bir problem çözümünde olumlu bir sonuca ulaşabilmek için, problemin sunduğu birden fazla olası seçenek içerisinden seçim yapması işlemine ne ad verilir?
Seçenekler
A
Karar Verme.
B
Kestirim
C
Yaprak Düğüm
D
Entropi
E
Gini
Açıklama:
Karar vericinin karşılaştığı bir problem çözümünde olumlu bir sonuca ulaşabilmek için, problemin sunduğu birden fazla olası seçenek içerisinden seçim yapması işlemine "Karar verme" adı verilir.
Soru 82
Düğümün temsil ettiği, dolayısı ile ayırma işlemini en iyi şekilde gerçekleştirecek olan niteliğe ne ad verilir?
Seçenekler
A
Ayırma Kriteri
B
Karar Verme.
C
Kestirim
D
Yaprak Düğüm
E
Entropi
Açıklama:
Düğümün temsil ettiği, dolayısı ile ayırma işlemini en iyi şekilde gerçekleştirecek olan niteliğe "ayırma kriteri" adı verilir.
Soru 83
Bir veri yığınındaki düzensizliğin, rassallığın miktarını ölçmek için kullanılan ölçüye ne ad verilir?
Seçenekler
A
Entropi
B
Kestirim
C
Yaprak Düğüm
D
Karmaşıklık
E
Gini
Açıklama:
Bir veri yığınındaki düzensizliğin, rassallığın miktarını ölçmek için kullanılan ölçüye "Entropi" adı verilir.
Soru 84
Bir ya da daha fazla dalı çıkartarak, karar ağacını basitleştirmek amacıyla, yaprak düğüm ile değiştirme işlemine ne ad verilir?
Seçenekler
A
Budama
B
Entropi
C
Kestirim
D
Karmaşıklık
E
Alternatif model
Açıklama:
Bir ya da daha fazla dalı çıkartarak, karar ağacını basitleştirmek amacıyla, yaprak düğüm ile değiştirme işlemine "budama" adı verilir.
Soru 85
Veritabanının, araştırmacının takdirinde olan bir oranda iki ayrık gruba bölünerek, eğitim ve test verisi olarak ele alınmasına dayanan yönteme ne ad verilir?
Seçenekler
A
Hold-Out
B
Çapraz Doğrulama
C
Nonlineer
D
Entropi
E
Kestirim
Açıklama:
Veritabanının, araştırmacının takdirinde olan bir oranda iki ayrık gruba bölünerek, eğitim ve test verisi olarak ele alınmasına dayanan yönteme "Hold-Out" adı verilir.
Soru 86
Veritabanının iki eşit gruba bölündüğü ve birinci grup eğitim verisi olurken ikinci grubun test verisi olarak ele alındığı tekniğe ne ad verilir?
Seçenekler
A
Hold-Out
B
Çapraz Doğrulama
C
Nonlineer
D
Entropi
E
Kestirim
Açıklama:
Veritabanının iki eşit gruba bölündüğü ve birinci grup eğitim verisi olurken ikinci grubun test verisi olarak ele alındığı tekniğe "Çapraz Doğrulama" adı verilir.
Soru 87
R ile sınıflandırma ve regresyon ağacı oluşturabilmek için hangi paketin R’de kurulu olması gerekmektedir?
Seçenekler
A
rpart
B
entropi
C
gini
D
oranlılık
E
xerror
Açıklama:
R ile sınıflandırma ve regresyon ağacı oluşturabilmek için "rpart" paketinin R’de kurulu olması gerekmektedir.
Soru 88
Aşağıdakilerden hangisi R dilinde düğüm ve ayırıcı nitelik bilgilerini grafiğe ekleyen fonksiyondur?
Seçenekler
A
text()
B
improve()
C
xerror()
D
splits()
E
summary()
Açıklama:
text() R dilinde düğüm ve ayırıcı nitelik bilgilerini grafiğe ekleyen fonksiyondur.
Soru 89
Aşağıdakilerden hangisi budama yöntemlerinden biridir?
Seçenekler
A
Kötümser hata.
B
Kararlılık.
C
Toplanabilirlik
D
Oranlılık.
E
Bölünebilirlik.
Açıklama:
"Kötümser Hata" budama yöntemlerinden biridir.
Soru 90
Karar ağacındaki her bir düğümün yanlızca iki dala ayrıldığı, Ayırma kriteri için Entropi, Gini ve Twoing indekslerinden, karar ağacını budamak için ise maliyet-karmaşıklığı kriterinden faydalanılan yönteme ne ad verilir?
Seçenekler
A
CART
B
CHAID
C
SPRINT
D
SLIQ
E
MARS
Açıklama:
Karar ağacındaki her bir düğümün yanlızca iki dala ayrıldığı, Ayırma kriteri için Entropi, Gini ve Twoing indekslerinden, karar ağacını budamak için ise maliyet-karmaşıklığı kriterinden faydalanılan yönteme "CART" adı verilir.
Soru 91
Seçeneklerden hangisi karar ağacı oluşturma algoritması olarak kullanılabilir?
Seçenekler
A
Varyans Analizi
B
t testi
C
Regresyon
D
ID3
E
Korelasyon
Açıklama:
Sınıflandırma problemlerinde bir karar ağacının oluşturulması için farklı algoritmalardan yararlanılabilir. Bu algoritmalara örnek olarak ID3, C4.5, CART, CHAID, QUEST, SLIQ, SPRINT ve MARS verilebilir. Bu algoritmalar, veri yığınını işleme şekline ve kullanılan ayırma kriterine göre değişiklik göstermektedir.
Soru 92
En basit karar ağacı algoritması olarak adlandırılan algoritma hangisidir?
Seçenekler
A
ID3
B
Korelasyon
C
Bayes
D
Cart
E
C4
Açıklama:
ID3 algoritması en basit karar ağacı oluşturma algoritmasıdır. Ayırma kriteri olarak kazanç ölçütünden yararlanılmaktadır. Karar ağacının büyümesini durdurma kriteri ise tüm kayıtların tek bir sınıfa ait olması veya kazanç ölçütünün sıfırdan büyük olmaması durumudur.
Soru 93
Ayırma kriteri olarak kazanç oranından faydalanılan ve ID3 algoritmasının geliştirilmiş hali olan karar ağacı algoritması nedir?
Seçenekler
A
ID3.A
B
C4.5
C
Varyans
D
CART
E
Ortalama
Açıklama:
C4.5 algoritması, ID3 algoritmasının geliştirilmiş hâlidir. Ayırma kriteri olarak kazanç oranından yararlanılmaktadır. Karar ağacının büyümesini durdurma kriteri, ayrılacak olan kayıtların sayısının belirli bir eşiğin altına düşmesi durumudur. C4.5 algoritmasında, karar ağacının büyüme safhasından sonra, sınıflandırma hatasına dayanan budama işlemi uygulanmaktadır.
Soru 94
Seçeneklerden hangisi CART algoritmasında ayırma kriteri olarak kullanılır?
Seçenekler
A
Regresyon
B
Belirlilik katsayısı
C
Varyans
D
Gini
E
Bayes
Açıklama:
Kısaca CART olarak adlandırılan sınıflandırma ve regresyon ağaçları algoritması, ikili (binary) karar ağacı yapısından dolayı diğer algoritmalardan farklılık göstermektedir. Karar ağacındaki her bir düğüm yanlızca iki dala ayrılır. Ayırma kriteri için Entropi, Gini ve Twoing indekslerinden, karar ağacını budamak için ise maliyet-karmaşıklığı kriterinden faydalanılır.
Soru 95
CART karar ağacı algoritmasında karar ağacını budamak için hangi kriterden faydalanılır?
Seçenekler
A
Gini
B
Entropi
C
Kazanç
D
Maliyet karmaşıklığı
E
İyimserlik Ölçütü (Laplace)
Açıklama:
Kısaca CART olarak adlandırılan sınıflandırma ve regresyon ağaçları algoritması, ikili (binary) karar ağacı yapısından dolayı diğer algoritmalardan farklılık göstermektedir. Karar ağacındaki her bir düğüm yanlızca iki dala ayrılır. Ayırma kriteri için Entropi, Gini ve Twoing indekslerinden, karar ağacını budamak için ise maliyet-karmaşıklığı kriterinden faydalanılır.
Soru 96
Tek değişkenli ve doğrusal kombinasyon ayırmaları destekleyen karar ağacı algoritması hangisidir?
Seçenekler
A
CART
B
ID3
C
C4.7
D
CHAID
E
QUEST
Açıklama:
QUEST algoritması, tek değişkenli ve doğrusal kombinasyon ayırmaları destekler. Her ayırma için (sıralayıcı veya sürekli niteliklerde) ANOVA F testi, Levene testi veya (sınıfla- yıcı niteliklerde) Pearson Ki-Kare testi kullanılarak, girdi niteliklerinin her biri ile hedef yani sınıf niteliğinin arasındaki birliktelik hesaplanır.
Soru 97
Seçeneklerden hangisi entropi indeksi olarak hesaplanamaz?
Seçenekler
A
0,25
B
0,12
C
-0,01
D
0,002
E
0,99
Açıklama:
Entropi, bir veri yığınındaki düzensizliğin, rassallığın miktarını ölçmek için kullanılan bir ölçüdür. Veri yığını içinde, örneğin bankanın oluşturduğu müşteri veritabanındaki müşterileri sınıflayan kredi riski niteliğinde, tek bir sınıf olması durumunda, entropinin 0 (sıfır) olması beklenir. Çünkü bir düzensizlikten veya rassallıktan söz edilemez. Bir başka deyişle, entropisi 0 olan bir grubun tam homojen bir grup, entropisi 1 olan grubun ise tam heterojen olduğu söylenebilir.
Soru 98
Entropisi 0 olan grup için seçeneklerden hangisi söylenebilir?
Seçenekler
A
Heterojendir
B
Dağıtıktır
C
Çevreseldir
D
Homojendir
E
Toplamsaldır
Açıklama:
Entropi, bir veri yığınındaki düzensizliğin, rassallığın miktarını ölçmek için kullanılan bir ölçüdür. Veri yığını içinde, örneğin bankanın oluşturduğu müşteri veritabanındaki müşterileri sınıflayan kredi riski niteliğinde, tek bir sınıf olması durumunda, entropinin 0 (sıfır) olması beklenir. Çünkü bir düzensizlikten veya rassallıktan söz edilemez. Bir başka deyişle, entropisi 0 olan bir grubun tam homojen bir grup, entropisi 1 olan grubun ise tam heterojen olduğu söylenebilir.
Soru 99
Bir karar ağacının ilk düğümüne ne ad verilir?
Seçenekler
A
İç düğüm
B
Alt düğüm
C
Son düğüm
D
Kazanç
E
Kök düğüm
Açıklama:
Problemde yer alan her bir nitelik için karar ağacında bir düğüm yer alır. Böylece ni- teliğin test edilmesi garanti altına alınır. Bir düğümden ayrılan dallar ise o düğümdeki testin tüm olası sonuçlarının her birine karşılık gelmektedir. Karar ağacının başlangıcını oluşturan ilk düğüm kök düğüm olarak adlandırılır.
Soru 100
Bir rassal değişkenin seçtiğimiz modele göre parametrelerinin yerine konulması ile elde edilen değer nedir?
Seçenekler
A
Sonuç
B
Kestirici
C
Kestirim
D
Olasılık
E
Orta değer
Açıklama:
Kestirim, bir rassal değişkenin seçtiğimiz modele göre parametrelerinin yerine konulması ile elde edilen değerdir.
Soru 101
Temel bir karar ağacı modelinde, sınıflaması yapılacak tüm "şey"leri içinde bulunduran, başlangıçtaki düğüme ne ad verilir?
Seçenekler
A
Kök düğüm
B
İç düğüm
C
Yaprak düğüm
D
Baş düğüm
E
Üst düğüm
Açıklama:
Karar ağaçlarının başlangıç düğümü, kök düğümü adını alır.
Soru 102
Hangi düğüme ulaşılmasıyla karar ağacı sonlanmış olur?
Seçenekler
A
Kök düğüm
B
İç düğüm
C
Yaprak düğüm
D
Son düğüm
E
Nihai düğüm
Açıklama:
Bir karar ağacı, yaprak düğüme ulaşılmasıyla son bulur ve nihai karar verilmiş olur...
Soru 103
Bir veri setinde entropi indeksiyle hangi niteliğin ya da değişkenin kök düğümü oluşturacağı nasıl belirlenir?
Seçenekler
A
En düşük kazanç değeri seçilir.
B
En yüksek kazanç değeri seçilir.
C
Büyük Gini indeksi seçilir.
D
Küçük Gini indeksi seçilir.
E
Random olarak bir nitelik belirlenir.
Açıklama:
Entropi indeksinde en yüksek kazanç değeri veren nitelik-değişken, kök düğüm olarak en üstte yer alır.
Soru 104
Regresyon ağacı olarak da bilinen karar ağacı oluşturma algoritması aşağıdakilerden hangisidir?
Seçenekler
A
CHAID
B
QUEST
C
SLIQ
D
CART
E
MARS
Açıklama:
Söz konusu algoritma, CART olarak bilinir.
Soru 105
Bir araştırmacı, yaptığı karar ağacı analizinde, ortaya çıkan modelin eğitim verisinde %100 doğru tahmin etme becerisini gösterdiğini ortaya koymuştur. Bu durumu önlemek için, aşağıdakilerden hangisini uygulayabilir?
Seçenekler
A
Test verisini küçültme
B
Eğitim verisini küçültme
C
Kestirim hata oranı
D
Budama
E
MARS algoritması
Açıklama:
Soruda bahsi geçen durum, aşırı uyuma (overfitting) bir örnektir. Budama işlemi, aşırı uyumu engelleme adına kullanılan bir yöntemdir.
Soru 106
Aşağıdakilerden hangisi budama işleminde kullanılan yöntemlerden biri değildir?
Seçenekler
A
Maliyet karmaşıklığı
B
Kötümser hata
C
Kritik değer
D
En küçük hata
E
Çapraz-doğrulama
Açıklama:
Çapraz-doğrulama, veri setinin eğitim ve test verisi olarak ayrılmasında kullanılan yöntemlerden biridir.
Soru 107
Bir araştırmacı, elindeki veriyi eğitim ve test verisi olarak ikiye bölerken, olası bir model yanlılığı ya da aşırım duyum durumunu engellemek adına, veriyi beş parçaya bölmüş, her seferinde bu beş parçanın farklı birini test verisi olarak ayırırken, diğer dört parça eğitim verisi olmuştur. Model bu verilerde beş kez tekrarlandıktan sonra, bu beş farklı durumun ortalamaları alınarak modelin hata oranı belirlenmiştir.
Kullanılan yöntem aşağıdakilerden hangisidir?
Kullanılan yöntem aşağıdakilerden hangisidir?
Seçenekler
A
Hold-out
B
Tekrarlı hold-out
C
k-katlı çapraz doğrulama
D
Bootstrap
E
Budama
Açıklama:
Kullanılan yöntem, k-fold cross validation (k-kat çapraz doğrulama) olarak bilinir. Burada, k=5'tir.
Soru 108
Bir araştırmacı, Açıköğretim Sisteminde yer alan öğrencilerin süreçte sistemi terk edip etmeyeceklerini (terk) belirlemek istemektedir. Bu amaçla akademik başarı puanı (abp), yaş (yas) ve cinsiyet (cins) değişkenlerini yordayıcı/tahmin edici olarak kullanmak istemektedir.
Bu değişkenler, veri setinin üç, dört, beş ve altıncı sütunlarında yer aldığına göre, rpart() fonksiyonu kullanılarak yazılması gereken kod aşağıdakilerden hangisidir?
Bu değişkenler, veri setinin üç, dört, beş ve altıncı sütunlarında yer aldığına göre, rpart() fonksiyonu kullanılarak yazılması gereken kod aşağıdakilerden hangisidir?
Seçenekler
A
formula=terk~abp+yas+cinsiyet,data=veri[,2:5],method=“poisson”
B
formula=terk~abp+yas+cinsiyet,data=veri[,2:5],method=“class”
C
formula=terk~abp+yas+cinsiyet,data=veri[,3:6],method=“poisson”
D
formula=terk~abp+yas+cinsiyet,data=veri[,3:6],method=“class”
E
formula=abp~terk+yas+cinsiyet,data=veri[,3:6],method=“class”
Açıklama:
Doğru yanıt D seçeneğinde görülmektedir. method = class seçilmelidir. Bunun dışında, veri setinde 3-6 arasındaki sütunların kullanılması gerekir.
Soru 109
Budama işlemi için kullanılan karmaşıklık parametresi aşağıdakilerden hangisiyle gösterilir?
Seçenekler
A
cp
B
xstd
C
nsplits
D
Gini indeks
E
n
Açıklama:
cp, "summary" komutuyla elde edilen çıktılarda karmaşıklık parametresini gösterir.
Soru 110
Bir rassal değişkenin seçtiğimiz modele göre parametrelerinin yerine konulması ile elde edilen değere ne ad verilir?
Seçenekler
A
Kestirim
B
Ölçme
C
Hata
D
Budama
E
Düğüm
Açıklama:
Yanıt kestirimdir.
Ünite 7
Soru 1
Aşağıdakilerden hangisi Kümeleme Analizinin bir aşaması değildir?
Seçenekler
A
Ayırma kriterlerinin belirlenmesi
B
Veri matrisinin oluşturulması
C
Benzerlik veya uzaklık matrislerinin hesaplanması
D
Kümelemede esas alınacak yöntemlerin belirlenmesi
E
Elde edilen sonuçların yorumlanması
Açıklama:
Kümeleme analizi genellikle dört aşamada uygulanmaktadır. Bunlar; veri matrisinin oluşturulması, benzerlik veya uzaklık matrislerinin hesaplanması, kümelemede esas alınacak yöntemlerin belirlenmesi ve elde edilen sonuçların yorumlanmasıdır.
Bu nedenle doğru yanıt a) seçeneğidir
Bu nedenle doğru yanıt a) seçeneğidir
Soru 2
Kümeleme yöntemlerinin uygulanmasındaki amaç aşağıdakilerden hangisidir?
Seçenekler
A
Küme içi homojenlik arttırılırken kümeler arası homojenliğin azaltılması amaçlanır.
B
Küme içi homojenlik azaltılırken kümeler arası homojenliğin artırılması amaçlanır.
C
Kümeler arasındaki farklılıkları ve kümeler içi benzerlikleri en düşük düzeye indirmektir.
D
Kümeler arasındaki farklılıklar azaltılırken kümeler içi farklılıkları en yüksek düzeye çıkarmaktır.
E
Kümeler arasındaki benzerlikler artırılırken kümeler içi farklılıkları en yüksek düzeye çıkarmaktır.
Açıklama:
Kümeleme yöntemleri; uzaklık (distance), benzerlik (similarity) ya da farklılık (dissimilarity) matrisinden yararlanarak birimleri ya da değişkenleri kendi içinde homojen ve kendi aralarında heterojen uygun kümelere ayırırken, kümeleri belirlemede izledikleri yaklaşımlara göre iki temel alt gruba ayrılırlar. Bunlar; Aşamalı kümeleme yöntemleri (Hierarchical Cluster Analysis Methods) ve Aşamalı olmayan kümeleme yöntemleri (Nonhierarchical Cluster Analysis Methods) olarak ele alınmaktadır. Her iki yöntemde de ortak amaç kümeler arasındaki farklılıkları ve kümeler içi benzerlikleri en yüksek düzeye çıkarmaktır. Yani, küme içi homojenlik arttırılırken kümeler arası homojenlik ise azaltılmaktadır. Hangi tekniğin kullanılacağı küme sayısına bağlı olmakla birlikte her iki tekniğin birlikte kullanılması çok daha yararlıdır. Böylece hem sonuçları hem de iki tekniğin hangisinin daha uygun sonuçlar verdiğini karşılaştırmak mümkün olmaktadır. Bu iki yöntem dışında ileri sürülmüş bir takım kümeleme algoritmaları varsa da bu yöntemler yaygın kullanımı olan yöntemler değildir.
Bu nedenle doğru yanıt a) seçeneğidir
Bu nedenle doğru yanıt a) seçeneğidir
Soru 3
Uzaklık matrisini kullanarak birbirine en yakın (uzaklık değerleri en küçük) birim ya da değişkenleri birleştirerek kümelerin oluşmasını sağlayan; m ve j kümeleri arasındaki uzaklığın dmj=min (dkj, dlj) eşitliği ile hesaplanan kümele yöntemi aşağıdakilerden hangisidir?
Seçenekler
A
Tek Bağlantı Kümeleme Yöntemi
B
Tam Bağlantı Kümeleme Yöntemi
C
Ortalama Bağlantı Kümeleme Yöntemi
D
McQuitty Bağlantı Kümeleme Yöntemi
E
Küresel Ortalama Bağlantı Kümeleme Yöntemi
Açıklama:
Literatürde en yakın komşuluk olarak da bilinen tek bağlantı kümeleme yöntemi, uzaklık matrisini kullanarak birbirine en yakın (uzaklık değerleri en küçük) birim ya da değişkenleri birleştirerek kümelerin oluşmasını sağlamaktadır. Bu yöntemin ilk aşamasında uzaklık matrisindeki en yakın (en küçük uzaklık) iki birim dikkate alınarak ilk küme oluşturulur. İkinci aşamada ise bir sonraki en küçük uzaklık belirlenir ve ilk oluşturulan kümeye bu birim ya da değişken eklenir ya da bu birim ile iki birimden oluşan yeni bir küme oluşturulur. İşlem, tüm birimler bir kümeye yerleşinceye kadar devam eder. Birleştirme yapılırken kümelerin eleman sayısının birden fazla olması koşulu yoktur. Tek bir birim de bir küme oluşturabilir. Bu yöntemde, m ve j kümeleri arasındaki uzaklık;
dmj=min (dkj, dlj)
biçiminde hesaplanmaktadır.
Bu nedenle doğru yanıt a) seçeneğidir
dmj=min (dkj, dlj)
biçiminde hesaplanmaktadır.
Bu nedenle doğru yanıt a) seçeneğidir
Soru 4
Tam bağlantı kümeleme yönteminde uzaklıklar aşağıdaki hangi eşitlikle hesaplanmaktadır?
Seçenekler
A
dmj=min (dkj, dlj)
B
dmj=maks (dkj, dlj)
C
dmj= (Nkdkj + Nldlj)/Nm
D
dmj= (dkj + dlj)/2
E
dmj= (Nkdkj + Nldlj)/Nm- NkNldk1/N2m
Açıklama:
Bu yöntem, en uzak komşuluk olarak da bilinmektedir. Tek bağlantı kümeleme yöntemine çok benzemekle birlikte bu yöntemdeki tek farklılık oluşturulan her kümedeki eleman çiftleri arasındaki uzaklığın maksimum olanının ele alınmasıdır.
Bu yönteme tam bağlantı kümeleme yöntemi denmesinin nedeni, bir küme içindeki tüm birimlerin birbirlerine maksimum uzaklık veya minimum yakınlığa bağlı olmasıdır (Şekil 7.5). Tam bağlantı tekniğindeki uzaklıklar,
dmj=maks (dkj, dlj)
biçiminde hesaplanmaktadır.
Bu nedenle doğru yanıt b seçeneğidir
Bu yönteme tam bağlantı kümeleme yöntemi denmesinin nedeni, bir küme içindeki tüm birimlerin birbirlerine maksimum uzaklık veya minimum yakınlığa bağlı olmasıdır (Şekil 7.5). Tam bağlantı tekniğindeki uzaklıklar,
dmj=maks (dkj, dlj)
biçiminde hesaplanmaktadır.
Bu nedenle doğru yanıt b seçeneğidir
Soru 5
> x=read.csv(“c:/ulkeler.txt”)
> dist.x=dist(x,method=”euclidean”)
> dist.x
> h=hclust(dist.x,method=”single”)
> h
> clusters=cutree(h, k=3)
> clusters
> plot(h,labels=x$Ulke)
> rect.hclust(h, K=3)
Yukarıda Öklid Uzaklık Matrisi ile Tek Bağlantı Kümeleme Analizi işlemi gerçekleştiren R komut kümesinde kümeleme dendrogramını görüntüleyen komut satırı hangisidir?
> dist.x=dist(x,method=”euclidean”)
> dist.x
> h=hclust(dist.x,method=”single”)
> h
> clusters=cutree(h, k=3)
> clusters
> plot(h,labels=x$Ulke)
> rect.hclust(h, K=3)
Yukarıda Öklid Uzaklık Matrisi ile Tek Bağlantı Kümeleme Analizi işlemi gerçekleştiren R komut kümesinde kümeleme dendrogramını görüntüleyen komut satırı hangisidir?
Seçenekler
A
> plot(h,labels=x$Ulke)
B
> clusters
C
> h$merge
D
> dist.x
E
> h
Açıklama:
Sayfa 174-178 arasında yapılan analizler sonucunda elde edilen dendrogramın görüntülenmesi için ise plot(h,labels=x$Ulke) komutu kullanılır. Veri dosyasında bulunan ülke sütunundaki ülkelere ait isimlerin dendrogramda gösterimi için komutta bulunan labels=x$Ulke ifadesi kullanılmıştır.
Bu nedenle doğru yanıt a) seçeneğidir
Bu nedenle doğru yanıt a) seçeneğidir
Soru 6
Aşamalı olmayan kümeleme yöntemleri için aşağıdaki ifadelerden hangisi yanlıştır?
Seçenekler
A
Aşamalı olmayan kümelemede hem birimler hem de değişkenler birbirleriyle farklı benzerlik düzeylerinde kümeler oluşturur.
B
Aşamalı olmayan kümelemede birbirleri ile benzer birimlerin aynı kümede toplanması koşuluyla veri setindeki n birimin k sayıda kümeye ayrılması amaçlanmaktadır
C
Eğer oluşturulacak küme sayısı ile ilgili olarak önsel bir bilgi var ise aşamalı olmayan kümeleme yöntemleri kullanmak daha çok tercih edilmektedir
D
Aşamalı olmayan kümeleme yöntemleri büyük veri setleri için daha uygundur
E
Aşamalı olmayan kümeleme yöntemleri veri setinde bulunan aşırı uç değerlerden daha az etkilenmektedir.
Açıklama:
Aşamalı olmayan kümeleme yöntemleri birimlerin kendi içinde homojen ve kendi aralarında heterojen olan kümelere ayrılmasını hedefleyen ve elde edilen kümeler aracılığı ile alt toplum yapılarına ilişkin tahmin yapmayı amaçlayan yöntemlerdir. Aşamalı kümelemede hem birimler hem de değişkenler birbirleriyle farklı benzerlik düzeylerinde kümeler oluştururken, aşamalı olmayan kümeleme yöntemlerinde sadece birimler kümelenmektedir. Birbirleri ile benzer birimlerin aynı kümede toplanması koşuluyla veri setindeki n birimin k sayıda kümeye ayrılması amaçlanmaktadır. Bu yöntemlerde küme sayısı önceden belirlenir. Diğer bir ifadeyle, eğer oluşturulacak küme sayısı ile ilgili olarak önsel bir bilgi var ise aşamalı olmayan kümeleme yöntemleri kullanmak daha çok tercih edilmektedir. Örneğin; kabul gören sağlık veya ekonomik göstergeler bakımından ülkeler 4 farklı kümeye ayrılmak istenilebilir. Bu kümeler ise, geri kalmış, az gelişmiş, gelişmekte olan, gelişmiş ülkeler olarak isimlendirilebilir.
Aşamalı kümeleme yöntemleri daha çok küçük veri setleri için uygundur. Buna karşılık aşamalı olmayan kümeleme yöntemleri ise daha çok büyük veri setlerine uygulanmaktadır. Bunun nedeni aşamalı olmayan kümeleme yöntemlerinde başlangıçta benzerlik ve uzaklık matrislerinin hesaplanmamasıdır. Ayrıca aşamalı olmayan kümeleme yöntemleri veri setinde bulunan aşırı uç değerlerden daha az etkilenmektedir.
Aşamalı olmayan Kümeleme Yöntemleri arasında en yaygın kullanılan yöntem K-ortalamalar kümeleme (k-means clustering, MacQueens’ Method) yöntemidir. Bu yöntem birçok istatistik hazır yazılımda bulunmaktadır. Bunun dışında Medoid kümeleme ve Fuzzy kümeleme gibi aşamalı olmayan kümeleme yöntemleri de bulunmaktadır.
Bu nedenle doğru yanıt a) seçeneğidir
Aşamalı kümeleme yöntemleri daha çok küçük veri setleri için uygundur. Buna karşılık aşamalı olmayan kümeleme yöntemleri ise daha çok büyük veri setlerine uygulanmaktadır. Bunun nedeni aşamalı olmayan kümeleme yöntemlerinde başlangıçta benzerlik ve uzaklık matrislerinin hesaplanmamasıdır. Ayrıca aşamalı olmayan kümeleme yöntemleri veri setinde bulunan aşırı uç değerlerden daha az etkilenmektedir.
Aşamalı olmayan Kümeleme Yöntemleri arasında en yaygın kullanılan yöntem K-ortalamalar kümeleme (k-means clustering, MacQueens’ Method) yöntemidir. Bu yöntem birçok istatistik hazır yazılımda bulunmaktadır. Bunun dışında Medoid kümeleme ve Fuzzy kümeleme gibi aşamalı olmayan kümeleme yöntemleri de bulunmaktadır.
Bu nedenle doğru yanıt a) seçeneğidir
Soru 7
Aşağıdakilerden hangisi K-Ortalamalar Kümeleme Yönteminde küme sayısını belirlemek için kullanılan yaklaşımlardan biri değildir?
Seçenekler
A
Kümenin en küçük ve en büyük değeri arasındaki farkı eşit aralığa bölmek
B
Aşamalı kümeleme yöntemlerinden elde edilen dendrogramları inceleyerek karar vermek,
C
Olasılıklı olarak başlangıç noktalarını rassal olarak belirlemek,
D
İlk nb birimin değişkenlere ait ortalamalarını başlangıç ortalama vektörü olarak ele alıp birimleri bu kümelere atama yaklaşımlarından birini seçmek,
E
Farklı rastgele başlatma konfigürasyonları seçerek küme sayısını bulmak,
Açıklama:
K-Ortalamalar Kümeleme Yöntemi sadece birimleri kümelemekte kullanılan bir yöntemdir.
Birimlerin k-ortalamalar yöntemi ile kümelenmesi için uzaklık matrisi ya da benzerlik matrisi hesaplamak gerekmemektedir. Verilerin kümelenmesinde kullanılacak olan küme sayısını önceden belirlemek yeterlidir. Küme sayısını belirlemek için ise farklı yaklaşımlar bulunmaktadır. Bunlar;
Aşamalı kümeleme yöntemlerinden elde edilen dendrogramları inceleyerek karar vermek,
Olasılıklı olarak başlangıç noktalarını rassal olarak belirlemek,
Ardışık olarak (Küme sayısı 2, 3, 4, ..., k biçiminde) her seferinde küme sayısını bir artırarak oluşan kümelemede birimlerin hangi kümeye ait olduğuna ilişkin küme üyeliklerini belirlemek. Yeni veri yapısına Ayırma (Discriminant) Analizi uygulamak ve en yüksek önemliliği bulunan Wilk’s Lamda değerine sahip olan küme sayısını, uygun kümeleme olarak kabul etmek,
İlk nb birimin değişkenlere ait ortalamalarını başlangıç ortalama vektörü olarak ele alıp birimleri bu kümelere atama yaklaşımlarından birini seçmek,
Farklı rastgele başlatma konfigürasyonları seçerek küme sayısını bulmak,
Bu nedenle doğru yanıt a) seçeneğidir
Birimlerin k-ortalamalar yöntemi ile kümelenmesi için uzaklık matrisi ya da benzerlik matrisi hesaplamak gerekmemektedir. Verilerin kümelenmesinde kullanılacak olan küme sayısını önceden belirlemek yeterlidir. Küme sayısını belirlemek için ise farklı yaklaşımlar bulunmaktadır. Bunlar;
Aşamalı kümeleme yöntemlerinden elde edilen dendrogramları inceleyerek karar vermek,
Olasılıklı olarak başlangıç noktalarını rassal olarak belirlemek,
Ardışık olarak (Küme sayısı 2, 3, 4, ..., k biçiminde) her seferinde küme sayısını bir artırarak oluşan kümelemede birimlerin hangi kümeye ait olduğuna ilişkin küme üyeliklerini belirlemek. Yeni veri yapısına Ayırma (Discriminant) Analizi uygulamak ve en yüksek önemliliği bulunan Wilk’s Lamda değerine sahip olan küme sayısını, uygun kümeleme olarak kabul etmek,
İlk nb birimin değişkenlere ait ortalamalarını başlangıç ortalama vektörü olarak ele alıp birimleri bu kümelere atama yaklaşımlarından birini seçmek,
Farklı rastgele başlatma konfigürasyonları seçerek küme sayısını bulmak,
Bu nedenle doğru yanıt a) seçeneğidir
Soru 8
Aşamalı olmayan Kümeleme Yöntemleri arasında en yaygın kullanılan yöntem aşağıdakilerden hangisidir?
Seçenekler
A
K-ortalamalar kümeleme
B
Medoid kümeleme
C
Fuzzy kümeleme
D
Medyan bağlantı kümeleme
E
Ward bağlantı kümeleme
Açıklama:
Aşamalı olmayan Kümeleme Yöntemleri arasında en yaygın kullanılan yöntem K-ortalamalar kümeleme (k-means clustering, MacQueens’ Method) yöntemidir. Bu yöntem birçok istatistik hazır yazılımda bulunmaktadır. Bunun dışında Medoid kümeleme ve Fuzzy kümeleme gibi aşamalı olmayan kümeleme yöntemleri de bulunmaktadır.
Bu nedenle doğru yanıt a) seçeneğidir
Bu nedenle doğru yanıt a) seçeneğidir
Soru 9
Aşağıdakilerden hangisi birleştirici aşamalı kümeleme yöntemlerinden biri değildir?
Seçenekler
A
Macqueens k-ortalamalar kümeleme yöntemi
B
Tek bağlantı kümeleme yöntemi
C
Tam bağlantı kümeleme yöntemi
D
Ortalama bağlantı kümeleme yöntemi
E
Mcquitty bağlantı kümeleme yöntemi
Açıklama:
Birleştirici aşamalı kümeleme yöntemlerinde, birimlerin birbirleri ile birleştirilmesinde farklı yöntemler kullanılmaktadır. Bunlardan sıklıkla kullanılan ve genel kabul görmüş olanları aşağıdaki gibi sayılabilir.
- Tek Bağlantı Kümeleme Yöntemi (TekBKY, SINGLE Linkage [SLINK], En Yakın Komşuluk, Nearest Neighbour Method)
- Tam Bağlantı Kümeleme Yöntemi (TamBKY, COMPLETE linkage Method [CLINK], Furthest Neighbor Method)
- Ortalama Bağlantı Kümeleme Yöntemi (OrtBKY, AVERAGE Linkage Method, [ALINK])
- McQuitty Bağlantı Kümeleme Yöntemi (McQuitty linkage Method)
- Küresel Ortalama Bağlantı Kümeleme Yöntemi (KOBKY, CENTROID linkage Method)
- Medyan Bağlantı Kümeleme Yöntemi (MBKY, MEDIAN linkage Method)
- Ward Bağlantı Kümeleme Yöntemi (WBKY, WARD linkage Method, En Küçük Varyans Kümeleme Yöntemi)
Soru 10
Kümeleme analizinde sonuçların bağlantılar, uzaklıklar ve birimlerin bağlanma düzeylerinin bir ağaç biçiminde ele alınarak ayrıntılı bir biçimde özetlendiği; genellikle x ekseninde birimler ve y ekseninde de uzaklıklar olacak şekilde yapılandırıldığı; değişkenlerin ya da birimlerin hangi aşamada ve hangi uzaklık ya da benzerlik düzeyinde bir araya gelerek küme oluşturduklarının ayrıntılı biçimde görüldüğü grafiksel yöntem aşağıdakilerden hangisidir?
Seçenekler
A
Dendrogram
B
Cluster
C
Manhattan (City-Block) uzaklığı
D
Farklılık matrisi
E
Plot
Açıklama:
Kümeleme analizinde sonuçlar dendrogram (ağaç diyagramı) adı verilen grafiksel yöntemle sunulurlar. Dendrogramlarda bağlantılar, uzaklıklar ve birimlerin bağlanma düzeyleri bir ağaç biçiminde ele alınarak şekillendirilir ve kümelenme süreci bu şekilde ayrıntılı bir biçimde özetlenir. Genellikle dendrogramlar; x ekseninde birimler ve y ekseninde de uzaklıklar olacak şekilde yapılandırılırlar.
Dendrogramlarda değişkenlerin ya da birimlerin hangi aşamada ve hangi uzaklık ya da benzerlik düzeyinde bir araya gelerek küme oluşturdukları ayrıntılı biçimde görülmektedir.
Bu nedenle doğru yanıt a) seçeneğidir
Dendrogramlarda değişkenlerin ya da birimlerin hangi aşamada ve hangi uzaklık ya da benzerlik düzeyinde bir araya gelerek küme oluşturdukları ayrıntılı biçimde görülmektedir.
Bu nedenle doğru yanıt a) seçeneğidir
Soru 11
Veri setinde bulunan gözlemlerin ya da değişkenlerin kendi aralarındaki benzerlikleri göz önünde bulundurularak gruplandırılması işlemi veri madenciliği yöntemlerinden hangisidir?
Seçenekler
A
Birliktelik kuralları
B
Kümeleme
C
Sınıflandırma
D
Lojistik regresyon
E
Diskriminant analizi
Açıklama:
Kümeleme, veri setinde bulunan gözlemlerin ya da değişkenlerin kendi aralarındaki benzerlikleri göz önünde bulundurularak gruplandırılması işlemidir. Kümeleme yöntemlerinin çoğu veri arasındaki uzaklıkları kullanır. Uygulamada çok sayıda kümeleme yöntemi kullanılmaktadır. Bu yöntemler, değişkenler arasındaki benzerliklerden ya da farklılıklardan yararlanarak bir veri setini alt kümelere ayırmak için kullanılmaktadır. Kümeleme analizinin amacı, gruplanmamış verileri benzerliklerine göre sınıflandırmak ve araştırmacıya özetleyici bilgiler elde etmede yardımcı olmaktır.
Soru 12
Hem veri madenciliğinin temeli olarak değerlendirilen hem de veri hazırlama aracı olarak kullanılan veri madenciliği yöntemi hangisidir?
Seçenekler
A
Sınıflandırma
B
Kümeleme analizi
C
Birliktelik kuralları
D
Pazar sepeti analizleri
E
Faktör analizi
Açıklama:
Sınıflandırma, veri madenciliğinde sıklıkla kullanılmaktadır. Üzerinde çalışılan veritabanının bir kısmı eğitim seti olarak ele alınır ve buradan hareketle sınıflandırma kuralları oluşturulur. Bu kurallar yardımıyla yeni bir durum ortaya çıktığında nasıl karar verileceği belirlenir. Veri madenciliği yönteminin sınıflandırma grubu içerisinde en sık kullandığı teknik “karar ağaçları”dır. Aynı zamanda lojistik regresyon, diskriminant analizi, sinir ağları ve fuzzy setleri de sıklıkla kullanılmaktadır. İnsanlar yüzyıllardır verileri sınıflandırdıkları, kategorize ettikleri ve derecelendirdikleri için sınıflandırma, işlemi hem veri madenciliğinin temeli olarak hem de veri hazırlama aracı olarak kullanılmaktadır.
Soru 13
Veri seti içerisinde yer alan kayıtların birbiriyle olan ilişkilerini inceleyerek, hangi olayların eş zamanlı olarak birlikte gerçekleşebileceklerini ortaya koymaya çalışan veri madenciliği yöntemleri seçeneklerden hangisidir?
Seçenekler
A
Sınıflandırma
B
Karar ağaçları
C
Kümeleme analizi
D
Lojistik regresyon
E
Birliktelik kuralları
Açıklama:
Birliktelik Kuralları, veri seti içerisinde yer alan kayıtların birbiriyle olan ilişkilerini inceleyerek, hangi olayların eş zamanlı olarak birlikte gerçekleşebileceklerini ortaya koymaya çalışan yöntemler veri madenciliği yöntemleridir. Özellikle pazarlama alanında uygulanmaktadır (Pazar sepet analizleri). Bu yöntemler birlikte olma kurallarını belirli olasılıklarla ortaya koymaktadır.
Soru 14
Kümeleme analizi genellikle dört aşamada uygulanmaktadır. Seçeneklerden hangisi bu aşamalardan birisi değildir?
Seçenekler
A
Veri matrisinin oluşturulması
B
Benzerlik matrisinin hesaplanması
C
Kümelemede esas alınacak yöntemlerin belirlenmesi
D
Strateji matrisinin oluşturulması
E
Elde edilen sonuçların yorumlanması
Açıklama:
Kümeleme analizi genellikle dört aşamada uygulanmaktadır. Bunlar; veri matrisinin oluşturulması, benzerlik veya uzaklık matrislerinin hesaplanması, kümelemede esas alınacak yöntemlerin belirlenmesi ve elde edilen sonuçların yorumlanmasıdır.
Soru 15
Başlangıçta veri setinde bulunan tüm birimlerin farklı birer küme oluşturduğunu kabul ederek analize başlamayı amaçlayan kümeleme analizi yaklaşımı hangisidir?
Seçenekler
A
Ayırıcı aşamalı kümeleme analizi
B
Dendogram
C
Karar ağaçları
D
Birleştirici aşamalı kümeleme analizi
E
Aşamalı olmayan kümeleme analizi
Açıklama:
Birleştirici (agglomerative) aşamalı kümeleme yöntemleri, başlangıçta veri setinde bulunan tüm birimlerin farklı birer küme oluşturduğu kabul edilerek analize başlanır. Veri setinde bulunan n birimi aşamalı olarak sırasıyla; n küme, n-1 küme, n-2 küme, ..., n-r küme, ..., 3 küme, 2 küme, 1 kümeye yerleştirmeyi amaçlayan bir yaklaşımdır. Bu yöntemde, her birim başlangıçta tek başına farklı birer küme olarak kabul edilir. Daha sonra birbirleri ile yüksek derecede benzerlik gösteren iki birim, bir küme oluşturur. Bir sonraki adımda bu kümeye farklı benzerlik düzeylerinde diğer birimler eklenerek birimlerin tamamı bir kümede toplanacak biçimde birbirleri ile bağlanırlar(birleştirilirler, kümelenirler).
Soru 16
Başlangıçta veri setinde bulunan tüm birimlerin bir küme oluşturduğunu kabul ederek analize başlamayı amaçlayan kümeleme analizi yaklaşımı hangisidir?
Seçenekler
A
Aşamalı olmayan kümeleme analizi
B
Birleştirici aşamalı kümeleme analizi
C
Ayırıcı aşamalı kümeleme analizi
D
Karar ağaçları
E
Dendogram
Açıklama:
Ayırıcı (divisive) aşamalı kümeleme yöntemlerinde, başlangıçta veri setinde bulunan tüm birimlerin bir küme olduğu varsayılarak analize başlanır. Diğer bir ifadeyle işlem, birleştirici aşamalı kümeleme yönteminde olan aşamaların tam tersine işler. İlk olarak tüm birimleri içeren büyük bir küme ele alınır. İzleyen aşamalarda en farklı (uzak) birimler birbirinden ayrılarak daha küçük kümeler oluşturulur. Bu aşamalar her birim kendi başına farklı bir küme oluşturuncaya kadar devam eder. Veri setinde bulunan n birimi sırasıyla aşamalı olarak 1 küme, 2 küme, 3 küme, ... , n-r küme, n-3 küme, n-2 küme, n-1 küme, n kümeye ayırmayı amaçlayan bir yaklaşımdır.
Soru 17
Seçeneklerden hangisi birleştirici kümeleme analizi yöntemlerinden birisi değildir?
Seçenekler
A
Tam Bağlantı Kümeleme Yöntemi
B
Ortalama Bağlantı Kümeleme Yöntemi
C
Küresel Ortalama Bağlantı Kümeleme Yöntemi
D
Medyan Bağlantı Kümeleme Yöntemi
E
Çok Bağlantı Kümeleme Yöntemi
Açıklama:
Birleştirici aşamalı kümeleme yöntemlerinde, birimlerin birbirleri ile birleştirilmesinde
farklı yöntemler kullanılmaktadır. Bunlardan sıklıkla kullanılan ve genel kabul görmüş
olanları aşağıdaki gibi sayılabilir.
• Tek Bağlantı Kümeleme Yöntemi (TekBKY, SINGLE Linkage [SLINK], En Yakın
Komşuluk, Nearest Neighbour Method)
• Tam Bağlantı Kümeleme Yöntemi (TamBKY, COMPLETE linkage Method
[CLINK], Furthest Neighbor Method)
• Ortalama Bağlantı Kümeleme Yöntemi (OrtBKY, AVERAGE Linkage Method,
[ALINK])
• McQuitty Bağlantı Kümeleme Yöntemi (McQuitty linkage Method)
• Küresel Ortalama Bağlantı Kümeleme Yöntemi (KOBKY, CENTROID linkage
Method)
• Medyan Bağlantı Kümeleme Yöntemi (MBKY, MEDIAN linkage Method)
• Ward Bağlantı Kümeleme Yöntemi (WBKY, WARD linkage Method, En Küçük
Varyans Kümeleme Yöntemi)
farklı yöntemler kullanılmaktadır. Bunlardan sıklıkla kullanılan ve genel kabul görmüş
olanları aşağıdaki gibi sayılabilir.
• Tek Bağlantı Kümeleme Yöntemi (TekBKY, SINGLE Linkage [SLINK], En Yakın
Komşuluk, Nearest Neighbour Method)
• Tam Bağlantı Kümeleme Yöntemi (TamBKY, COMPLETE linkage Method
[CLINK], Furthest Neighbor Method)
• Ortalama Bağlantı Kümeleme Yöntemi (OrtBKY, AVERAGE Linkage Method,
[ALINK])
• McQuitty Bağlantı Kümeleme Yöntemi (McQuitty linkage Method)
• Küresel Ortalama Bağlantı Kümeleme Yöntemi (KOBKY, CENTROID linkage
Method)
• Medyan Bağlantı Kümeleme Yöntemi (MBKY, MEDIAN linkage Method)
• Ward Bağlantı Kümeleme Yöntemi (WBKY, WARD linkage Method, En Küçük
Varyans Kümeleme Yöntemi)
Soru 18
Yeni bir kümenin oluşumunda K. ve L. kümelerin J. küme ile olan uzaklıkları toplamının yarısı olarak hesaplanan birleştirici kümeleme yöntemi hangisidir?
Seçenekler
A
Ortalama Bağlantı Kümeleme Yöntemi
B
McQuitty Bağlantı Kümeleme Yöntemi
C
Küresel Ortalama Bağlantı Kümeleme Yöntemi
D
Medyan Bağlantı Kümeleme Yöntemi
E
Ward Bağlantı Kümeleme Yöntemi
Açıklama:
McQuitty bağlantı kümeleme yönteminde; m. kümenin oluşumunda k. ve l. kümelerin j.
küme ile olan uzaklıkları toplamının yarısı (ortalaması) hesaplanır. Ağırlıksız ortalama
bağlantı yöntemi ismi ile de literatürde sıklıkla kullanılmaktadır.
küme ile olan uzaklıkları toplamının yarısı (ortalaması) hesaplanır. Ağırlıksız ortalama
bağlantı yöntemi ismi ile de literatürde sıklıkla kullanılmaktadır.
Soru 19
Küresel ortalama ve medyan bağlantı kümeleme yöntemlerinin karma şekli olan ve küme içi varyansın minimum olduğu kümelerin belirlenip bu doğrultuda kümeleme işleminin yapıldığı birleştirici kümeleme yöntemi hangisidir?
Seçenekler
A
Ortalama Bağlantı Kümeleme Yöntemi
B
McQuitty Bağlantı Kümeleme Yöntemi
C
Tam Bağlantı Kümeleme Yöntemi
D
Tek Bağlantı Kümeleme Yöntemi
E
Ward Bağlantı Kümeleme Yöntemi
Açıklama:
Ward Bağlantı Kümeleme Yöntemi, küresel ortalama ve medyan bağlantı kümeleme yöntemlerinin karma şeklidir.
Küme içi varyansın minimum olduğu kümeler belirlenir ve bu doğrultuda kümeler oluşturulur. Minimum varyans yöntemi olarak da bilinen bu yaklaşım, bir kümede yer alan bir birimin, aynı kümenin içinde bulunan birimlerden ortalama uzaklığını dikkate almaktadır. Küme bağlantılarından ziyade küme içi kareler toplamı dikkate alınmaktadır. Bu yöntem, az birimli kümeleri birleştirme eğilimindedir. Ayrıca bu yöntemin birbirine eşit sayıda birim içeren kümeler oluşturma gibi bir eğilimi de vardır. Bundan dolayı, araştırmacının kümelerdeki birim sayılarının benzer (yakın) olduğu beklentisi durumunda bu yönteme başvurması önerilmektedir. Aşırı değerlerden etkilenmektedir. Sıklıkla kullanılan aşamalı kümeleme yöntemidir.
Küme içi varyansın minimum olduğu kümeler belirlenir ve bu doğrultuda kümeler oluşturulur. Minimum varyans yöntemi olarak da bilinen bu yaklaşım, bir kümede yer alan bir birimin, aynı kümenin içinde bulunan birimlerden ortalama uzaklığını dikkate almaktadır. Küme bağlantılarından ziyade küme içi kareler toplamı dikkate alınmaktadır. Bu yöntem, az birimli kümeleri birleştirme eğilimindedir. Ayrıca bu yöntemin birbirine eşit sayıda birim içeren kümeler oluşturma gibi bir eğilimi de vardır. Bundan dolayı, araştırmacının kümelerdeki birim sayılarının benzer (yakın) olduğu beklentisi durumunda bu yönteme başvurması önerilmektedir. Aşırı değerlerden etkilenmektedir. Sıklıkla kullanılan aşamalı kümeleme yöntemidir.
Soru 20
Birimlerin kendi içinde homojen ve kendi aralarında heterojen olan kümelere ayrılmasını hedefleyen ve elde edilen kümeler aracılığı ile alt toplum yapılarına ilişkin tahmin yapmayı amaçlayan yöntemler hangisidir?
Seçenekler
A
Dendogram
B
Karar ağaçları
C
Ayırıcı aşamalı kümeleme analizi
D
Aşamalı olmayan kümeleme analizi
E
Birleştirici aşamalı kümeleme analizi
Açıklama:
Birimlerin kendi içinde homojen ve kendi aralarında heterojen olan kümelere ayrılmasını hedefleyen ve elde edilen kümeler aracılığı ile alt toplum yapılarına ilişkin tahmin yapmayı amaçlayan yöntemler aşamalı olmayan kümeleme analizi yöntemleridir.
Soru 21
Veri setinde bulunan gözlemlerin ya da değişkenlerin kendi aralarındaki benzerlikleri göz önünde bulundurularak gruplandırılması işlemine ne ad verilir?
Seçenekler
A
Kümeleme
B
Veri madenciliği
C
Birliktelik kuralları
D
Sinir ağları
E
Diskriminant analizi
Açıklama:
Kümeleme, veri setinde bulunan gözlemlerin ya da değişkenlerin kendi aralarındaki benzerlikleri göz önünde bulundurularak gruplandırılması işlemidir.
Soru 22
Aşağıda verilenlerden hangisi verilerin standardize edilmesi ve belirli aralıklardaki değerlere dönüştürülmesi için kullanılan yöntemler arasında yer almaz?
Seçenekler
A
z skorlarına dönüştürme
B
-1≤x≤1 aralığına dönüştürme
C
Ortalama değer -1 olacak şekilde dönüştürme
D
0≤x≤1 aralığına dönüştürme
E
Serideki maksimum değer 1 olacak şekilde dönüştürme
Açıklama:
Verilerin standardize edilmesi ve belirli aralıklardaki değerlere dönüştürülmesi için en çok kullanılan yöntemler; z skorlarına dönüştürme, -1≤x≤1 aralığına dönüştürme, 0≤x≤1 aralığına dönüştürme, serideki maksimum değer 1 olacak şekilde dönüştürme, ortalama değer 1 olacak şekilde dönüştürme, standart sapma 1 olacak şekilde dönüştürme yöntemleridir.
Soru 23
Aşağıdakilerden hangisi kümeleme analizi uygulamasının ilk basamağını oluşturur?
Seçenekler
A
Benzerlik matrislerinin hesaplanması
B
Kümelemede esas alınacak yöntemlerin belirlenmesi
C
Elde edilen sonuçların yorumlanması
D
Veri matrisinin oluşturulması
E
Uzaklık matrislerinin hesaplanması
Açıklama:
Kümeleme analizi genellikle dört aşamada uygulanmaktadır. Bunlar; veri matrisinin oluşturulması, benzerlik veya uzaklık matrislerinin hesaplanması, kümelemede esas alınacak yöntemlerin belirlenmesi ve elde edilen sonuçların yorumlanmasıdır.
Soru 24
Aşağıdakilerden hangisi veya hangileri birleştirici aşamalı kümeleme yöntemlerindendir?
I. Tek bağlantı kümeleme yöntemi
II. Ortalama bağlantı kümeleme yöntemi
III. k-ortalamalar yöntemi
I. Tek bağlantı kümeleme yöntemi
II. Ortalama bağlantı kümeleme yöntemi
III. k-ortalamalar yöntemi
Seçenekler
A
Yalnız I
B
Yalnız II
C
II ve III
D
I ve II
E
I, II ve III
Açıklama:
Birleştirici aşamalı kümeleme yöntemlerinde, birimlerin birbirleri ile birleştirilmesinde farklı yöntemler kullanılmaktadır. Bunlardan sıklıkla kullanılan ve genel kabul görmüş olanları aşağıdaki gibi sayılabilir.
• Tek Bağlantı Kümeleme Yöntemi (TekBKY, SINGLE Linkage [SLINK], En Yakın Komşuluk, Nearest Neighbour Method)
• Tam Bağlantı Kümeleme Yöntemi (TamBKY, COMPLETE linkage Method [CLINK], Furthest Neighbor Method)
• Ortalama Bağlantı Kümeleme Yöntemi (OrtBKY, AVERAGE Linkage Method, [ALINK])
• McQuitty Bağlantı Kümeleme Yöntemi (McQuitty linkage Method)
• Küresel Ortalama Bağlantı Kümeleme Yöntemi (KOBKY, CENTROID linkage Method)
• Medyan Bağlantı Kümeleme Yöntemi (MBKY, MEDIAN linkage Method)
• Ward Bağlantı Kümeleme Yöntemi (WBKY, WARD linkage Method, En Küçük Varyans Kümeleme Yöntemi)Yukarıda sayılan yöntemlerin, birimleri birleştirmede uydukları kriterler aşağıdaki alt başlıklar altında açıklanmıştır.
• Tek Bağlantı Kümeleme Yöntemi (TekBKY, SINGLE Linkage [SLINK], En Yakın Komşuluk, Nearest Neighbour Method)
• Tam Bağlantı Kümeleme Yöntemi (TamBKY, COMPLETE linkage Method [CLINK], Furthest Neighbor Method)
• Ortalama Bağlantı Kümeleme Yöntemi (OrtBKY, AVERAGE Linkage Method, [ALINK])
• McQuitty Bağlantı Kümeleme Yöntemi (McQuitty linkage Method)
• Küresel Ortalama Bağlantı Kümeleme Yöntemi (KOBKY, CENTROID linkage Method)
• Medyan Bağlantı Kümeleme Yöntemi (MBKY, MEDIAN linkage Method)
• Ward Bağlantı Kümeleme Yöntemi (WBKY, WARD linkage Method, En Küçük Varyans Kümeleme Yöntemi)Yukarıda sayılan yöntemlerin, birimleri birleştirmede uydukları kriterler aşağıdaki alt başlıklar altında açıklanmıştır.
Soru 25
Veri setine ilişkin uzaklık matrisini bulmak için aşağıda verilen komutlardan hangisi kullanılır?
Seçenekler
A
>table(x$Ülke,results$cluster)
B
>plot(h,labels=x$Ülke)
C
>results$size
D
>x=read.csv(“c:/ulkeler.txt”)
E
ist.x=dist(x,method=”euclidean”)
Açıklama:
Veri setine ilişkin uzaklık matrisini bulmak için dist.x=dist(x,method=”euclidean”) komutu kullanılır.
Soru 26
Aşağıdakilerden hangisi aşamalı olmayan kümeleme yöntemleri arasındadır?
Seçenekler
A
Ortalama Bağlantı Kümeleme Yöntemi
B
k-Medoidler Kümeleme Yöntemi
C
Tam Bağlantı Kümeleme Yöntemi
D
McQuitty Bağlantı Kümeleme Yöntemi
E
Tek Bağlantı Kümeleme Yöntemi
Açıklama:
Aşamalı olmayan Kümeleme Yöntemleri arasında en yaygın kullanılan yöntem K-ortalamalar kümeleme (k-means clustering, MacQueens’ Method) yöntemidir. Bu yön-tem birçok istatistik hazır yazılımda bulunmaktadır. Bunun dışında Medoid kümeleme ve Fuzzy kümeleme gibi aşamalı olmayan kümeleme yöntemleri de bulunmaktadır.
Soru 27
Veri setindeki değişkenlerin asimetrik olduğu durumlarda kullanılan yöntem aşağıdakilerden hangisidir?
Seçenekler
A
Ortalama Bağlantı Kümeleme Yöntemi
B
k-medyanlar Yöntemi
C
k-ortalamalar Yöntemi
D
k-medoidler Yöntemi
E
Tek Bağlantı Kümeleme Yöntemi
Açıklama:
k-Medyanlar Yöntemi
Medyan değerlerine ait vektörleri küme merkezi olarak kullanan k merkezli algoritmadır. Veri setindeki değişkenlerin asimetrik olduğu durumlarda kullanılmaktadır. Bu yöntemde de uzaklık ölçüsü seçimi keyfi olarak gerçekleştirilebilir, ancak yakınsamanın sağlanıp sağlanmadığı mutlaka göz önünde bulundurulmalıdır. Bu algoritmada, Manhattan uzaklık ölçüsü en sık tercih edilen kümelenme ölçütüdür.
Medyan değerlerine ait vektörleri küme merkezi olarak kullanan k merkezli algoritmadır. Veri setindeki değişkenlerin asimetrik olduğu durumlarda kullanılmaktadır. Bu yöntemde de uzaklık ölçüsü seçimi keyfi olarak gerçekleştirilebilir, ancak yakınsamanın sağlanıp sağlanmadığı mutlaka göz önünde bulundurulmalıdır. Bu algoritmada, Manhattan uzaklık ölçüsü en sık tercih edilen kümelenme ölçütüdür.
Soru 28
Uzaklık matrisini kullanarak birbirine en yakın (uzaklık değerleri en küçük) birim ya da değişkenleri birleştirerek kümelerin oluşmasını sağlayan kümeleme yöntemi hangisidir?
Seçenekler
A
Tek Bağlantı Kümeleme Yöntemi
B
Ortalama Bağlantı Kümeleme Yöntemi
C
Tam Bağlantı Kümeleme Yöntemi
D
Ward Bağlantı Kümeleme Yöntemi
E
McQuitty Bağlantı Kümeleme Yöntemi
Açıklama:
Literatürde en yakın komşuluk olarak da bilinen tek bağlantı kümeleme yöntemi, uzaklık matrisini kullanarak birbirine en yakın (uzaklık değerleri en küçük) birim ya da değişkenleri birleştirerek kümelerin oluşmasını sağlamaktadır. Bu yöntemin ilk aşamasında uzaklık matrisindeki en yakın (en küçük uzaklık) iki birim dikkate alınarak ilk küme oluşturulur. İkinci aşamada ise bir sonraki en küçük uzaklık belirlenir ve ilk oluşturulan kümeye bu birim ya da değişken eklenir ya da bu birim ile iki birimden oluşan yeni bir küme oluşturulur. İşlem, tüm birimler bir kümeye yerleşinceye kadar devam eder.
Soru 29
İki obje arasındaki benzerliği ölçmede en yaygın kullanılan uzaklık ölçüsü olup iki obje arasına çizilecek bir doğrunun uzunluğunu temel alan ölçüye ne ad verilir?
Seçenekler
A
Karesel Pearson uzaklığı
B
Manhattan (City-Blok) Uzaklığı
C
Korelasyon uzaklığı
D
Açısal uzaklık
E
Öklid uzaklığı
Açıklama:
Öklid uzaklığı iki obje arasındaki benzerliği ölçmede en yaygın kullanılan uzaklık ölçüsü olup iki obje arasına çizilecek bir doğrunun uzunluğunu temel alır.
Soru 30
Küresel ortalama ve medyan bağlantı kümeleme yöntemlerinin karma şekli hangi kümeleme yöntemidir?
Seçenekler
A
Tek Bağlantı Kümeleme Yöntemi
B
McQuitty Bağlantı Kümeleme Yöntemi
C
Ward Bağlantı Kümeleme Yöntemi
D
Tam Bağlantı Kümeleme Yöntemi
E
k-ortalamalar Yöntemi
Açıklama:
Bu yöntem, küresel ortalama ve medyan bağlantı kümeleme yöntemlerinin karma şeklidir. Küme içi varyansın minimum olduğu kümeler belirlenir ve bu doğrultuda kümeler oluşturulur. Minimum varyans yöntemi olarak da bilinen bu yaklaşım, bir kümede yer alan bir birimin, aynı kümenin içinde bulunan birimlerden ortalama uzaklığını dikkate almaktadır. Küme bağlantılarından ziyade küme içi kareler toplamı dikkate alınmaktadır. Bu yöntem, az birimli kümeleri birleştirme eğilimindedir. Ayrıca bu yöntemin birbirine eşit sayıda birim içeren kümeler oluşturma gibi bir eğilimi de vardır. Bundan dolayı, araştırmacının kümelerdeki birim sayılarının benzer (yakın) olduğu beklentisi durumunda bu yönteme başvurması önerilmektedir. Aşırı değerlerden etkilenmektedir.
Soru 31
I. Hangi kümeye ait olduğu bilinmeyen bir grup verinin, sınıflandırılarak anlamlandırılması,
II. Benzer olanları farklı olandan ayırmak,
III. Doğal grup yapılarını belirlemek, homojen alt gruplara ayırabilmek,
Yukarıdakilerden hangisi ya da hangileri kümeleme analizinin temel amaçları şeklinde ifade edilebilir?
II. Benzer olanları farklı olandan ayırmak,
III. Doğal grup yapılarını belirlemek, homojen alt gruplara ayırabilmek,
Yukarıdakilerden hangisi ya da hangileri kümeleme analizinin temel amaçları şeklinde ifade edilebilir?
Seçenekler
A
Yalnız II
B
I-III
C
I-II-III
D
Yalnız III
E
II-III
Açıklama:
Verilen ifadelerin tamamı kümeleme analizi amaçları arasındadır.
Soru 32
Aşağıdakilerden hangisi kümeleme analizinin özellikleri arasında sayılamaz?
Seçenekler
A
Tahmin amaçlı kullanılmaz
B
Varsayımlarda bulunmaz
C
Genellikle dört aşamada gerçekleşir.
D
Uygulama aşamasında çok fazla varsayıma ihtiyaç duyar
E
Çoklu bağıntıya dikkat ister
Açıklama:
Uygulamada aşamasındaki temel varsayımların karşılanmasına gerek yoktur.
Soru 33
Küme elemanları arasındaki en küçük uzaklık değeri temel alınarak kümelerin
oluşturulması esasına dayanan aşamalı birleştirici kümeleme yöntemi hangisidir?
oluşturulması esasına dayanan aşamalı birleştirici kümeleme yöntemi hangisidir?
Seçenekler
A
Tam Bağlantı Kümeleme Yöntemi
B
Tek Bağlantı Kümeleme Yöntemi
C
Medyan Bağlantı Kümeleme Yöntemi
D
Ward Bağlantı Kümeleme Yöntemi
E
Ortalama Bağlantı Kümeleme Yöntemi
Açıklama:
Literatürde en yakın komşuluk olarak da bilinen tek bağlantı kümeleme yöntemi,
uzaklık matrisini kullanarak birbirine en yakın (uzaklık değerleri en küçük) birim ya da
değişkenleri birleştirerek kümelerin oluşmasını sağlamaktadır.
uzaklık matrisini kullanarak birbirine en yakın (uzaklık değerleri en küçük) birim ya da
değişkenleri birleştirerek kümelerin oluşmasını sağlamaktadır.
Soru 34
Aşağıdaki eşlemelerden hangisi yanlıştır?
Seçenekler
A
Tam bağlantı kümeleme-en uzak komşuluk
B
Ortalama bağlantı kümeleme-ortalama uzaklıklar
C
McQuitty bağlantı kümeleme-uzaklıkları toplamının yarısı
D
Medyan bağlantı kümeleme- en yakın uzaklık
E
Ward bağlantı kümeleme- küme içi varyans
Açıklama:
Medyan bağlantı kümeleme için yapılan eşleşme yanlıştır. Medyan bağlantı kümeleme yöntemi, McQuitty bağlantı kümeleme yönteminin farklı bir biçimidir. Bu yöntemde m. ve j. kümeler arasındaki uzaklık; dmj= (dkj + dlj)/2 - dkl/4 formülü yardımıyla hesaplanır. Doğru cevap D.
Soru 35
Kümeleme analiz sonuçlarının sunulduğu grafiksel yöntemlerin adı nedir?
Seçenekler
A
Dendrogram
B
Birim
C
McQuitty Bağlantısı
D
Ward Bağlantısı
E
Ayırıcı aşama
Açıklama:
Kümeleme analizinde sonuçlar dendrogram (ağaç diyagramı) adı verilen grafiksel yöntemle sunulurlar. Dendrogramlarda bağlantılar, uzaklıklar ve birimlerin bağlanma düzeyleri bir ağaç biçiminde ele alınarak şekillendirilir ve kümelenme süreci bu şekilde ayrıntılı bir biçimde özetlenir.
Soru 36
Birleştirici kümeleme yöntemlerinde ortalamalar üzerinden yapılan kümeleme yöntemleri düşünüldüğünde hangisi dışarıda kalır?
Seçenekler
A
Ortalama Bağlantı Kümeleme Yöntemi
B
Küresel Ortalama Bağlantı Kümeleme Yöntemi
C
McQuitty Bağlantı Kümeleme Yöntemi
D
Medyan Bağlantı Kümeleme Yöntemi
E
Tek Bağlantı Kümeleme Yöntemi
Açıklama:
Tek bağlantı kümeleme yöntemi yakınlığa dayanan bir kümeleme yöntemidir.
Soru 37
Aşağıdakilerden hangisi aşamalı olmayan kümeleme yöntemlerinden biri değildir?
Seçenekler
A
k-Medyanlar Yöntemi
B
K-ortalamalar yöntemi
C
k-Medoidler Yöntemi
D
Tam Bağlantı Kümeleme Yöntemi
E
k-Ortalamalar Yönteminin Uygulanması
Açıklama:
Tam Bağlantı Kümeleme Yöntemi aşamaşı kümeleme yöntemlerinden biridir.
Soru 38
I. Aşamalı kümeleme yöntemlerinden elde edilen dendrogramları inceleyerek karar
vermek,
II. Olasılıklı olarak başlangıç noktalarını rassal olarak belirlemek,
III. Farklı rastgele başlatma konfigürasyonları seçerek küme sayısını bulmak
Verilen ifadelerden hangisi ya da hangileri küme sayısını belirlemek için kullanılan yaklaşımlardandır?
vermek,
II. Olasılıklı olarak başlangıç noktalarını rassal olarak belirlemek,
III. Farklı rastgele başlatma konfigürasyonları seçerek küme sayısını bulmak
Verilen ifadelerden hangisi ya da hangileri küme sayısını belirlemek için kullanılan yaklaşımlardandır?
Seçenekler
A
I-II-III
B
II-III
C
Yalnız -I
D
I-III
E
Yalnız II
Açıklama:
İfadelerin tamamı küme sayısını belirlemede kullanılan yaklaşımlarındandır.
Soru 39
Beş değişken ile gerçekleştirilen kümeleme analizi R programının verdiği sonuçlar aşağıdaki gibidir. Verilen bilgilere göre birinci kümede kaç ülke yer almaktadır?
Seçenekler
A
1
B
2
C
3
D
4
E
5
Açıklama:
1 kümedeki 1 ifadeleri toplandığında 5 ülke ortaya çıkmaktadır.
Soru 40
Yukarıda verilen bilgilere göre hangisi doğrudur?Seçenekler
A
1. Kümede toplam 6 ülke yer almaktadır.
B
2 .Kümede toplam 5 ülke yer almaktadır.
C
3 Kümede yer alan ülkeler Bosna Hersek, Nijerya, Slovenya, Brezilya ve Türkiye'dir.
D
4.kümede toplam 4 ülke yer almaktadır.
E
Bir kümede en fazla bulunan ülke sayısı 4. kümedir.
Açıklama:
Yanıt C' devierlen küme ve ülke doğru verilmiştir.
Soru 41
Veri setinde bulunan gözlemlerin ya da değişkenlerin kendi aralarındaki benzerlikleri göz önünde bulundurularak gruplandırılması işlemine ne ad verilir?
Seçenekler
A
Yapay Sinir Ağları
B
Kümeleme
C
Sınıflama
D
Tahmin
E
Regresyon
Açıklama:
Kümeleme, veri setinde bulunan gözlemlerin ya da değişkenlerin kendi aralarındaki benzerlikleri göz önünde bulundurularak gruplandırılması işlemidir
Soru 42
Veri seti içerisinde yer alan kayıtların birbiriyle olan ilişkilerini inceleyerek, hangi olayların eş zamanlı olarak birlikte gerçekleşebileceklerini ortaya koymaya çalışan yöntemlere ne ad verilir?
Seçenekler
A
Birliktelik kuralları
B
Sınıflandırma
C
Kümeleme
D
Tahmin
E
Regresyon
Açıklama:
Birliktelik Kuralları, veri seti içerisinde yer alan kayıtların birbiriyle olan ilişkilerini inceleyerek, hangi olayların eş zamanlı olarak birlikte gerçekleşebileceklerini ortaya koymaya çalışan veri madenciliği yöntemleridir.
Soru 43
Aşağıdakilerden hangisi aşamalı olmayan kümeleme yöntemlerinden birisidir?
Seçenekler
A
Küresel Ortalama Bağlantı Kümeleme Yöntemi
B
k-Ortalamalar Yöntemi
C
McQuitty Bağlantı Kümeleme Yöntemi
D
Medyan Bağlantı Kümeleme Yöntemi
E
Ward Bağlantı Kümeleme Yöntemi
Açıklama:
k-Ortalamalar Yöntemi, aşamalı olmayan kümeleme yöntemlerinden birisidir. Diğerleri birleştirici kümeleme yöntemlerindendir.
Soru 44
Aşağıdaki yöntemlerden hangisi küme elemanları arasındaki en küçük uzaklık değeri temel alınarak kümelerin oluşturulması esasına dayanır?
Seçenekler
A
Tam Bağlantı Kümeleme Yöntemi
B
McQuitty Bağlantı Kümeleme Yöntemi
C
Tek Bağlantı Kümeleme Yöntemi
D
Ortalama Bağlantı Kümeleme Yöntemi
E
Tam Bağlantı Kümeleme Yöntemi
Açıklama:
Tek Bağlantı Kümeleme Yöntemi, en basit aşamalı kümeleme yöntemidir. Bu yöntem, farklı veri yapılarındaki kümelenmeleri tanımlayabilmesi açısından uygulayıcılar tarafından sıklıkla tercih edilmektedir. Küme elemanları arasındaki en küçük uzaklık değeri temel alınarak kümelerin oluşturulması esasına dayanır.
Soru 45
Aşağıdakilerden hangisi en uzak komşuluk yöntemi olarak da bilinir?
Seçenekler
A
Tek Bağlantı Kümeleme Yöntemi
B
Ortalama Bağlantı Kümeleme Yöntemi
C
McQuitty Bağlantı Kümeleme Yöntemi
D
Tam Bağlantı Kümeleme Yöntemi
E
Ward Bağlantı Kümeleme Yöntemi
Açıklama:
Tam Bağlantı Kümeleme Yöntemi:
Bu yöntem, en uzak komşuluk olarak da bilinmektedir. Tek bağlantı kümeleme yöntemine çok benzemekle birlikte bu yöntemdeki tek farklılık oluşturulan her kümedeki eleman çiftleri arasındaki uzaklığın maksimum olanının ele alınmasıdır.
Bu yöntem, en uzak komşuluk olarak da bilinmektedir. Tek bağlantı kümeleme yöntemine çok benzemekle birlikte bu yöntemdeki tek farklılık oluşturulan her kümedeki eleman çiftleri arasındaki uzaklığın maksimum olanının ele alınmasıdır.
Soru 46
Aşağıdakilerden hangisi küresel ortalama ve medyan bağlantı kümeleme yöntemlerinin karma şeklidir?
Seçenekler
A
Ortalama Bağlantı Kümeleme Yöntemi
B
McQuitty Bağlantı Kümeleme Yöntemi
C
Tek Bağlantı Kümeleme Yöntemi
D
Ward Bağlantı Kümeleme Yöntemi
E
Tam Bağlantı Kümeleme Yöntemi
Açıklama:
Ward Bağlantı Kümeleme Yöntemi Bu yöntem, küresel ortalama ve medyan bağlantı kümeleme yöntemlerinin karma şeklidir. Küme içi varyansın minimum olduğu kümeler belirlenir ve bu doğrultuda kümeler oluşturulur. Minimum varyans yöntemi olarak da bilinen bu yaklaşım, bir kümede yer alan bir birimin, aynı kümenin içinde bulunan birimlerden ortalama uzaklığını dikkate almaktadır. Küme bağlantılarından ziyade küme içi kareler toplamı dikkate alınmaktadır. Bu yöntem, az birimli kümeleri birleştirme eğilimindedir. Ayrıca bu yöntemin birbirine eşit sayıda birim içeren kümeler oluşturma gibi bir eğilimi de vardır. Bundan dolayı, araştırmacının kümelerdeki birim sayılarının benzer (yakın) olduğu beklentisi durumunda bu yönteme başvurması önerilmektedir. Aşırı değerlerden etkilenmektedir. Sıklıkla kullanılan aşamalı kümeleme yöntemidir.
Soru 47
Aşağıdaki yöntemlerin hangisi veri setindeki değişkenlerin asimetrik olduğu durumlarda kullanılmaktadır?
Seçenekler
A
k-Medyanlar Yöntemi
B
k-Ortalamalar Yöntemi
C
Doğrusal regresyon yöntemi
D
Polinom regresyon yöntemi
E
Naive bayes
Açıklama:
Medyan değerlerine ait vektörleri küme merkezi olarak kullanan k merkezli algoritmadır. Veri setindeki değişkenlerin asimetrik olduğu durumlarda kullanılmaktadır. Bu yöntemde de uzaklık ölçüsü seçimi keyfi olarak gerçekleştirilebilir, ancak yakınsamanın sağlanıp sağlanmadığı mutlaka göz önünde bulundurulmalıdır. Bu algoritmada, Manhattan uzaklık ölçüsü en sık tercih edilen kümelenme ölçütüdür.
Soru 48
R programında veri dosyasındaki veriler hangi komutla sisteme aktarılır?
Seçenekler
A
plot
B
read.csv
C
kmeans
D
results$size
E
results$cluster
Açıklama:
Veri dosyaları read.csv komutuyla sisteme aktarılır.
Soru 49
Kümelenme adımlarını görüntülemek için hangi komut kullanılır?
Seçenekler
A
h$merge
B
read
C
hclust
D
dist
E
cutree
Açıklama:
Kümelenme adımlarını görüntülemek için ise h$merge komutu kullanılır.
Soru 50
Tek bağlantı kümeleme yöntemi uygulamak için hangi komut kullanılır?
Seçenekler
A
x=read.csv(“c:/ulkeler.txt”)
B
dist.x=dist(x,method=”euclidean”)
C
h=hclust(dist.x,method=”sing le”)
D
plot(x[c(“D1”,”D4”)], col=results$cluster)
E
table(x$Ulke,results$cluster)
Açıklama:
Tek bağlantı kümeleme yöntemi uygulamak için ise h=hclust(dist.x,method=”sing le”) komutu kullanılır.
Soru 51
Aşağıdakilerden hangisi kümeleme yöntemlerinden biri değildir?
Seçenekler
A
Fuzzy setleri
B
Tek Bağlantı
C
Ortalama Bağlantı
D
Tam Bağlantı
E
McQuitty Bağlantı
Açıklama:
Fuzzy setleri sınıflandırma amaçlı kullanılmaktadır. Diğer seçeneklerde yer alan yöntemler birleştirici kümeleme yöntemleridir. Doğru cevap A.
Soru 52
Aşağıdakilerden hangisi kümeleme analizinin temel amacıdır?
Seçenekler
A
Yeni bir durum çıktığında nasıl karar verileceğini belirlemek
B
Veri gruplarını kategoriler halinde derecelendirmek
C
Veri seti içindeki kayıtların arasındaki ilişkileri incelemek
D
Hangi olayların eş zamanlı birlikte gerçekleşebileceğini belirlemek
E
Birimleri ya da değişkenleri temel özelliklerine göre sınıflandırmak
Açıklama:
Kümeleme analizinin temel amacı, hangi kümeye ait olduğu bilinmeyen bir grup verinin, sınıflandırılarak anlamlandırılmasıdır. Dolayısıyla kümeleme analizi birimleri ya da değişkenleri temel özelliklerine göre sınıflandırmak için kullanılmaktadır. Kısaca kümeleme analizinin genel amacının benzer olanları farklı olandan ayırmak olduğu ifade edilebilir.
Soru 53
Kümeleme analizinin diskriminant analizinden farkı aşağıdakilerden hangisidir?
Seçenekler
A
Kümeleme analizinde gruplar arası değişimin en fazla olması beklenmez.
B
Kümeleme analizinde grup içi değişimin en az olması beklenmez.
C
Kümeleme analizinin sınıflandırma amacı bulunmaz.
D
Kümeleme analizi tahmin amaçlı kullanılmaz
E
Kümeleme analizinin varsayımları bulunmaz.
Açıklama:
Kümeleme analizi, diğer çok değişkenli analiz yöntemi olan diskriminant analizinde olduğu gibi tahmin amaçlı kullanılmamakta ve faktör analizinde olduğu gibi de varsayımları bulunmamaktadır.
Soru 54
Kümeleme analizinde birim ya da değişkenler arasındaki uzaklıkları hesaplamak için en sık kullanılan ve iki obje arasına çizilecek bir doğrunun uzunluğunu temel alan uzaklık ölçüsü aşağıdakilerden hangisidir?
Seçenekler
A
Açısal uzaklık
B
Öklid uzaklığı
C
Pearson uzaklığı
D
Manhattan Uzaklığı
E
Korelasyon uzaklığı
Açıklama:
Kümeleme analizinde birim ya da değişkenler arasındaki uzaklıkları hesaplamak için en sık kullanılan uzaklık ölçüsü Öklid uzaklığıdır. Öklid uzaklığı iki obje arasındaki benzerliği ölçmede en yaygın kullanılan uzaklık ölçüsü olup iki obje arasına çizilecek bir doğrunun uzunluğunu temel alır.
Soru 55
Aşağıdakilerden hangisi bağlantılar, uzaklıklar ve birimlerin bağlanma düzeylerini bir ağaç biçiminde şekillendiren kümelenme sürecini anlatır?
Seçenekler
A
Medoid
B
Plot
C
Cluster
D
Merge
E
Dendrogram
Açıklama:
Kümeleme analizinde sonuçlar dendrogram (ağaç diyagramı) adı verilen grafiksel yöntemle sunulurlar. Dendrogramlarda bağlantılar, uzaklıklar ve birimlerin bağlanma düzeyleri bir ağaç biçiminde ele alınarak şekillendirilir ve kümelenme süreci bu şekilde ayrıntılı bir biçimde özetlenir. Genellikle dendrogramlar; x ekseninde birimler ve y ekseninde de uzaklıklar olacak şekilde yapılandırılırlar.
Soru 56
Aşağıdakilerden hangisi küme elemanları arasındaki en küçük uzaklık değeri temel alınarak kümelerin oluşturulması esasına dayanır?
Seçenekler
A
Küresel Ortalama bağlantı Kümeleme Yöntemi
B
McQuitty Bağlantı Kümeleme Yöntemi
C
Tek Bağlantı Kümeleme Yöntemi
D
Ortalama Bağlantı Kümeleme Yöntemi
E
Tam Bağlantı Kümeleme Yöntemi
Açıklama:
Tek Bağlantı Kümeleme Yöntemi en basit aşamalı kümeleme yöntemidir. Bu yöntem, farklı veri yapılarındaki kümelenmeleri tanımlayabilmesi açısından uygulayıcılar tarafından sıklıkla tercih edilmektedir. Küme elemanları arasındaki en küçük uzaklık değeri temel alınarak kümelerin oluşturulması esasına dayanır.
Soru 57
Küresel ortalama ve medyan bağlantı kümeleme yöntemlerinin karma şekli aşağıdakilerden hangisidir?
Seçenekler
A
Tek Bağlantı Kümeleme Yöntemi
B
Ward Bağlantı Kümeleme Yöntemi
C
Medyan Bağlantı Kümeleme Yöntemi
D
Ortalama Bağlantı Kümeleme Yöntemi
E
McQuitty Bağlantı Kümeleme Yöntemi
Açıklama:
Ward Bağlantı Kümeleme Yöntemi, küresel ortalama ve medyan bağlantı kümeleme yöntemlerinin karma şeklidir. Küme içi varyansın minimum olduğu kümeler belirlenir ve bu doğrultuda kümeler oluşturulur. Minimum varyans yöntemi olarak da bilinen bu yaklaşım, bir kümede yer alan bir birimin, aynı kümenin içinde bulunan birimlerden ortalama uzaklığını dikkate almaktadır.
Soru 58
Veri setindeki değişkenlerin asimetrik olduğu durumlarda kullanılan ve uzaklık ölçüsü seçimi keyfi olarak gerçekleştirilebilen yöntem aşağıdakilerden hangisidir?
Seçenekler
A
Ortalama Bağlantı Kümeleme Yöntemi
B
Tek Bağlantı Kümeleme Yöntemi
C
k-ortalamalar Yöntemi
D
k-medyanlar Yöntemi
E
k-medoidler Yöntemi
Açıklama:
k-Medyanlar Yöntemi Medyan değerlerine ait vektörleri küme merkezi olarak kullanan k merkezli algoritmadır. Veri setindeki değişkenlerin asimetrik olduğu durumlarda kullanılmaktadır. Bu yöntemde de uzaklık ölçüsü seçimi keyfi olarak gerçekleştirilebilir, ancak yakınsamanın sağlanıp sağlanmadığı mutlaka göz önünde bulundurulmalıdır. Bu algoritmada, Manhattan uzaklık ölçüsü en sık tercih edilen kümelenme ölçütüdür.
Soru 59
Diğer küme elemanları ile aralarında en az fark görülen seçilmiş küme elemanları olarak tanımlanan kümeleme yöntemi aşağıdakilerden hangisidir?
Seçenekler
A
Ortalama Bağlantı Kümeleme Yöntemi
B
Tek Bağlantı Kümeleme Yöntemi
C
k-medyanlar Yöntemi
D
k-ortalamalar Yöntemi
E
k-medoidler Yöntemi
Açıklama:
Özellikle değişkenlerin birbirinden bağımsız olmadığı ve değişkenler arasında korelasyon olduğu durumlarda k-medyanlar yöntemi veri setini gruplamada (kümelemede) başarılı olmamaktadır. Bu durumda kümeleme için k-medoidler yöntemi önerilmektedir. Medoid, diğer küme elemanları ile aralarında en az fark görülen seçilmiş küme elemanları olarak tanımlanabilmektedir. Bu algoritma k-ortalamalar ve k-medyanlar yöntemlerine göre daha çok işlem gerektirmektedir. Çünkü, medoidler belirlenirken tüm ikili uzaklık ölçüleri hesaplanmaktadır.
Soru 60
Aşağıdakilerden hangisi sadece birimleri kümelemekte kullanılan bir yöntemdir?
Seçenekler
A
k-ortalamalar kümeleme yöntemi
B
Ortalama Bağlantı kümeleme yöntemi
C
Ward bağlantı kümeleme yöntemi
D
k-medoidler yöntemi
E
k-medyanlar yöntemi
Açıklama:
K-Ortalamalar Kümeleme Yöntemi sadece birimleri kümelemekte kullanılan bir yöntemdir.
Soru 61
Aşağıdakilerden hangisi kümeleme analizinde birim ya da değişkenler arasındaki uzaklıkları hesaplamak için kullanılan yöntemlerden biridir?
Seçenekler
A
Tanjant uzaklığı
B
Sinüs uzaklığı
C
Öklit uzaklığı
D
Pisagor uzaklığı
E
Düzlem uzaklığı
Açıklama:
Kümeleme analizinde birim ya da değişkenler arasındaki uzaklıkları hesaplamak için en sık kullanılan uzaklık ölçüsü Öklid uzaklığıdır. Öklid uzaklığı iki obje arasındaki benzerliği ölçmede en yaygın kullanılan uzaklık ölçüsü olup iki obje arasına çizilecek bir doğrunun uzunluğunu temel alır.
Soru 62
Uzaklıkları ve birimlerin bağlanma düzeylerini bir ağaç biçiminde ele alınarak şekillendiren kümeleme yöntemi aşağıdakilerden hangisidir?
Seçenekler
A
Dendrogramlar
B
Ayırıcı Aşamalı Kümeleme Yöntemleri
C
Birleştirici Aşamalı Kümeleme Yöntemleri
D
Medyan Bağlantı Kümeleme Yöntemi
E
Ward Bağlantı Kümeleme Yöntemi
Açıklama:
Kümeleme analizinde sonuçlar dendrogram (ağaç diyagramı) adı verilen grafiksel yöntemle sunulurlar. Dendrogramlarda bağlantılar, uzaklıklar ve birimlerin bağlanma düzeyleri bir ağaç biçiminde ele alınarak şekillendirilir ve kümelenme süreci bu şekilde ayrıntılı bir biçimde özetlenir.
Soru 63
Aşağıdakilerden hangisi birleştirici kümeleme yöntemlerinden biri olarak sayılamaz?
Seçenekler
A
Tek Bağlantı Kümeleme Yöntemi
B
Küresel Ortalama Bağlantı Kümeleme Yöntemi
C
Tam Bağlantı Kümeleme Yöntemi
D
Kısmi Bağlantı Kümeleme Yöntemi
E
Ward Bağlantı Kümeleme Yöntemi
Açıklama:
Birleştirici aşamalı kümeleme yöntemlerinde, birimlerin birbirleri ile birleştirilmesinde farklı yöntemler kullanılmaktadır. Bunlardan sıklıkla kullanılan ve genel kabul görmüş olanları aşağıdaki gibi sayılabilir.
• Tek Bağlantı Kümeleme Yöntemi (TekBKY, SINGLE Linkage [SLINK], En Yakın Komşuluk, Nearest Neighbour Method)
• Tam Bağlantı Kümeleme Yöntemi (TamBKY, COMPLETE linkage Method [CLINK], Furthest Neighbor Method)
• Ortalama Bağlantı Kümeleme Yöntemi (OrtBKY, AVERAGE Linkage Method, [ALINK])
• McQuitty Bağlantı Kümeleme Yöntemi (McQuitty linkage Method)
• Küresel Ortalama Bağlantı Kümeleme Yöntemi (KOBKY, CENTROID linkage Method)
• Medyan Bağlantı Kümeleme Yöntemi (MBKY, MEDIAN linkage Method)
• Ward Bağlantı Kümeleme Yöntemi (WBKY, WARD linkage Method, En Küçük Varyans Kümeleme Yöntemi)
• Tek Bağlantı Kümeleme Yöntemi (TekBKY, SINGLE Linkage [SLINK], En Yakın Komşuluk, Nearest Neighbour Method)
• Tam Bağlantı Kümeleme Yöntemi (TamBKY, COMPLETE linkage Method [CLINK], Furthest Neighbor Method)
• Ortalama Bağlantı Kümeleme Yöntemi (OrtBKY, AVERAGE Linkage Method, [ALINK])
• McQuitty Bağlantı Kümeleme Yöntemi (McQuitty linkage Method)
• Küresel Ortalama Bağlantı Kümeleme Yöntemi (KOBKY, CENTROID linkage Method)
• Medyan Bağlantı Kümeleme Yöntemi (MBKY, MEDIAN linkage Method)
• Ward Bağlantı Kümeleme Yöntemi (WBKY, WARD linkage Method, En Küçük Varyans Kümeleme Yöntemi)
Soru 64
Küme elemanları arasındaki en küçük uzaklık değeri temel alınarak kümelerin oluşturulması esasına dayanan yöntem aşağıdakilerden hangisidir?
Seçenekler
A
McQuitty Bağlantı Kümeleme Yöntemi
B
Ward Bağlantı Kümeleme Yöntemi
C
Tek Bağlantı Kümeleme Yöntemi
D
Ortalama Bağlantı Kümeleme Yöntemi
E
Tam Bağlantı Kümeleme Yöntemi
Açıklama:
TekBKY en basit aşamalı kümeleme yöntemidir. Bu yöntem, farklı veri yapılarındaki kümelenmeleri tanımlayabilmesi açısından uygulayıcılar tarafından sıklıkla tercih edilmektedir. Küme elemanları arasındaki en küçük uzaklık değeri temel alınarak kümelerin oluşturulması esasına dayanır.
Soru 65
Bir küme içindeki birim ile diğer küme içindeki birimler arasındaki ortalama uzaklıklar dikkate alan yöntem aşağıdakilerden hangisidir?
Seçenekler
A
Ortalama Bağlantı Kümeleme Yöntemi
B
Tam Bağlantı Kümeleme Yöntemi
C
Ward Bağlantı Kümeleme Yöntemi
D
Küresel Ortalama Bağlantı Kümeleme Yöntemi
E
Medyan Bağlantı Kümeleme Yöntemi
Açıklama:
Ortalama Bağlantı Kümeleme Yöntemi: Bu yöntemde, tek bağlantı ve tam bağlantı yöntemlerinde olduğu gibi işleme başlanır. Fakat kümeleme kriteri olarak, bir küme içindeki birim ile diğer küme içindeki birimler arasındaki ortalama uzaklıklar dikkate alınır. Ortalama bağlantı kümeleme yöntemindeki kümeleme kriteri, bir kümedeki tüm birimlerden elde edilen ortalama uzaklığın diğer kümedeki tüm birimlere olan ortalama uzaklığı olarak ele alınır.
Soru 66
Araştırmacının kümelerdeki birim sayılarının benzer (yakın) olduğu beklentisi durumunda başvuracağı kümeleme yöntemi aşağıdakilerden hangisidir?
Seçenekler
A
Ortalama Bağlantı Kümeleme Yöntemi
B
Tam Bağlantı Kümeleme Yöntemi
C
Ward Bağlantı Kümeleme Yöntemi
D
McQuitty Bağlantı Kümeleme Yöntemi
E
Tek Bağlantı Kümeleme Yöntemi
Açıklama:
Ward Bağlantı Kümeleme Yöntemi: Bu yöntem, küresel ortalama ve medyan bağlantı kümeleme yöntemlerinin karma şeklidir. Küme içi varyansın minimum olduğu kümeler belirlenir ve bu doğrultuda kümeler oluşturulur. Minimum varyans yöntemi olarak da bilinen bu yaklaşım, bir kümede yer alan bir birimin, aynı kümenin içinde bulunan birimlerden ortalama uzaklığını dikkate almaktadır. Küme bağlantılarından ziyade küme içi kareler toplamı dikkate alınmaktadır. Bu yöntem, az birimli kümeleri birleştirme eğilimindedir. Ayrıca bu yöntemin birbirine eşit sayıda birim içeren kümeler oluşturma gibi bir eğilimi de vardır. Bundan dolayı, araştırmacının kümelerdeki birim sayılarının benzer (yakın) olduğu beklentisi durumunda bu yönteme başvurması önerilmektedir.
Soru 67
h=hclust(dist.x,method=”single”) komutu hangi kümeleme yöntemini uygulamak için kullanılmaktadır?
Seçenekler
A
Ortalama Bağlantı Kümeleme Yöntemi
B
Tam Bağlantı Kümeleme Yöntemi
C
Ward Bağlantı Kümeleme Yöntemi
D
McQuitty Bağlantı Kümeleme Yöntemi
E
Tek Bağlantı Kümeleme Yöntemi
Açıklama:
Elde edilen Öklid uzaklık matrisi yardımıyla, verilere Hiyerarşik kümeleme yöntemlerinden Tek bağlantı kümeleme yöntemi uygulamak için ise h=hclust(dist.x,method=”single”) komutu kullanılır.
Soru 68
Değişkenlerin ortalama vektörlerini küme merkezi olarak ele alan ve kümeleme süreci bunun etrafında şekillendiren yöntem aşağıdakilerden hangisidir?
Seçenekler
A
Ortalama Bağlantı Kümeleme Yöntemi
B
k-ortalamalar Yöntemi
C
k-medyanlar Yöntemi
D
k-medoidler Yöntemi
E
Tek Bağlantı Kümeleme Yöntemi
Açıklama:
Mac Queen’in k-ortalamalar adını verdiği yöntem gözlemleri kümelerin önceden belirlenmiş sayısına gruplandırmakla işleme başlamaktadır. Bu yöntem, değişkenlerin ortalama vektörlerini küme merkezi olarak ele alır ve kümeleme süreci bunun etrafında şekillenir. Bu kümeleme yöntemi, veri setinde bulunan birimleri küme içi kareler toplamlarını minimize (en küçük) edecek biçimde k sayıda kümeye ayırmayı amaçlar.
Soru 69
Asimetrik veri setlerinde değişkenlerin birbirinden bağımsız olmadığı ve değişkenler arasında korelasyon olduğu durumlarda tercih edilen kümeleme yöntemi aşağıdakilerden hangisidir?
Seçenekler
A
Ortalama Bağlantı Kümeleme Yöntemi
B
k-ortalamalar Yöntemi
C
k-medyanlar Yöntemi
D
k-medoidler Yöntemi
E
Tek Bağlantı Kümeleme Yöntemi
Açıklama:
k-Medoidler Yöntemi: Veri setinin asimetrik olduğu durumlarda k-medyanlar yöntemi, k-ortalamalar yöntemine göre daha çok tercih edilmektedir. Fakat k-medyanlar yönteminde de yakınsama gözlenmediği durumlar olabilmektedir. Özellikle değişkenlerin birbirinden bağımsız olmadığı ve değişkenler arasında korelasyon olduğu durumlarda k-medyanlar yöntemi veri setini gruplamada (kümelemede) başarılı olmamaktadır. Bu durumda kümeleme için k-medoidler yöntemi önerilmektedir. Medoid, diğer küme elemanları ile aralarında en az fark görülen seçilmiş küme elemanları olarak tanımlanabilmektedir. Bu algoritma k-ortalamalar ve k-medyanlar yöntemlerine göre daha çok işlem gerektirmektedir. Çünkü, medoidler belirlenirken tüm ikili uzaklık ölçüleri hesaplanmaktadır.
Soru 70
Aşağıdakilerden hangisi aşamalı olmayan kümeleme yöntemlerinden biridir?
Seçenekler
A
Ortalama Bağlantı Kümeleme Yöntemi
B
Tam Bağlantı Kümeleme Yöntemi
C
k-Ortalamalar Yöntemi
D
Ward Bağlantı Kümeleme Yöntemi
E
McQuitty Bağlantı Kümeleme Yöntemi
Açıklama:
Birimlerin kendi içinde homojen ve kendi aralarında heterojen olan kümelere ayrılmasını hedefleyen ve elde edilen kümeler aracılığı ile alt toplum yapılarına ilişkin tahmin yapmayı amaçlayan yöntemlerdir. Aşamalı olmayan Kümeleme Yöntemleri arasında en yaygın kullanılan yöntem K-ortalamalar kümeleme (k-means clustering, MacQueens’ Method) yöntemidir. Bu yöntem birçok istatistik hazır yazılımda bulunmaktadır. Bunun dışında Medoid kümeleme ve Fuzzy kümeleme gibi aşamalı olmayan kümeleme yöntemleri de bulunmaktadır.
Soru 71
....................., veri setinde bulunan gözlemlerin ya da değişkenlerin kendi aralarındaki benzerlikleri göz önünde bulundurularak gruplandırılması işlemidir.
Yukarıdaki boşluğa aşağıdaki ifadelerden hangisi gelmelidir?
Yukarıdaki boşluğa aşağıdaki ifadelerden hangisi gelmelidir?
Seçenekler
A
Sınıflandırma
B
Kümeleme
C
Birliktelik
D
Veri madenciliği
E
Benzerlik
Açıklama:
Kümeleme, veri setinde bulunan gözlemlerin ya da değişkenlerin kendi aralarındaki benzerlikleri göz önünde bulundurularak gruplandırılması işlemidir.
Soru 72
Kümeleme analizi ile ilgili aşağıdakilerden hangisi yanlıştır?
Seçenekler
A
Veri madenciliğinin bir alt türüdür.
B
Genel amacı benzer olanları farklı olandan ayırmaktır.
C
Tahmin amaçlı kullanılmakta ve varsayımları bulunmaktadır.
D
Kümeleme analizi genellikle dört aşamada uygulanmaktadır.
E
Veri matrisinin oluşturulması, kümeleme analizinin ilk aşamasıdır.
Açıklama:
Kümeleme analizi, diğer çok değişkenli analiz yöntemi olan diskriminant analizinde olduğu gibi tahmin amaçlı kullanılmamakta ve faktör analizinde olduğu gibi de varsayımları bulunmamaktadır.
Soru 73
I. Benzerlik veya uzaklık matrislerinin hesaplanması
II. Sonuçların yorumlanması
III. Veri matrisinin oluşturulması
IV. Hangi kümeleme yönteminin kullanılacağına karar verilmesi
Kümeleme analizinin aşamaları hangi seçenekte doğru sırada verilmiştir?
II. Sonuçların yorumlanması
III. Veri matrisinin oluşturulması
IV. Hangi kümeleme yönteminin kullanılacağına karar verilmesi
Kümeleme analizinin aşamaları hangi seçenekte doğru sırada verilmiştir?
Seçenekler
A
IV, III, I, II
B
III, IV, I, II
C
I, IV, III, II
D
III, I, IV, II
E
III, I, II, VI
Açıklama:
Doğru sıralama III, I, IV, II şeklindedir.
Soru 74
Aşağıdaki uzak düzeyi değerlerinden hangisinde kümenin en fazla elemanı içermesi olasıdır?
Seçenekler
A
5.00
B
11.82
C
20.00
D
26.00
E
36.0
Açıklama:
En büyük değer daha kapsayıcı olacağından doğru cevap 36.0 'dır.
Soru 75
En Küçük Varyans Kümeleme Yöntemi aşağıdaki yöntemlerin hangisinin çeşididir?
Seçenekler
A
Tek Bağlantı Kümeleme Yöntemi
B
Tam Bağlantı Kümeleme Yöntemi
C
Ortalama Bağlantı Kümeleme Yöntemi
D
Medyan Bağlantı Kümeleme Yöntemi
E
Ward Bağlantı Kümeleme Yöntemi
Açıklama:
En Küçük Varyans Kümeleme Yöntemi, Ward Bağlantı Kümeleme Yöntemi çeşitlerindendir.
Soru 76
dmj=(Nkdkj + Nldlj)/Nm
Yukarıdaki formül hangi kümeleme yöntemine aittir?
Yukarıdaki formül hangi kümeleme yöntemine aittir?
Seçenekler
A
Tek bağlantılı kümeleme yöntemi
B
Tam bağlantılı kümeleme yöntemi
C
Ortalama Bağlantı Kümeleme Yöntemi
D
McQuitty Bağlantı Kümeleme Yöntemi
E
Küresel Ortalama Bağlantı Kümeleme Yöntemi
Açıklama:
Söz konusu formül ortalama bağlantılı kümeleme yönteminde kullanılır.
Soru 77
R programında veri setine ilişkin uzaklık matrisini bulmak için hangi komut girilmelidir?
Seçenekler
A
dist.x
B
h=hclust
C
h$merge
D
clusters=cutree
E
rect.hclust
Açıklama:
R programında veri setine ilişkin uzaklık matrisini bulmak için "dist.x" komutu kullanılmalıdır.
Soru 78
k-Ortalamalar Yöntemi hakkında aşağıdaki ifadelerden hangisi yanlıştır?
Seçenekler
A
Bu kümeleme yöntemi, veri setinde bulunan birimleri küme içi kareler toplamlarını minimize (en küçük) edecek biçimde k sayıda kümeye ayırmayı amaçlar.
B
Birimler her iterasyonda farklı kümelere atanır ve en uygun çözüm permütasyon yaklaşımına benzer bir şekilde belirlenir.
C
K-ortalamalar yönteminde kümelerin belirlenmesinde kullanılan çekirdek noktaların veri setinde bulunan gözlenen değerlerden seçilmesi zorunludur.
D
Farklı aşamalardaki atamalarda, kümeler arası heterojeniteye bağlı olarak birimlerin atandıkları kümelerden çıkarılarak başka bir kümeye atanması mümkün olabilmektedir.
E
Karışık yapıda ya da kesikli değişken içeren veri setleri için uygun bir seçim değildir.
Açıklama:
K-ortalamalar yönteminde kümelerin belirlenmesinde kullanılan çekirdek noktaların veri setinde bulunan gözlenen değerlerden seçilmesi zorunlu değildir.
Soru 79
k-Medyanlar Yöntemi hakkında aşağıdakilerden hangisi yanlıştır?
Seçenekler
A
Veri setindeki değişkenlerin asimetrik olduğu durumlarda kullanılmaktadır.
B
Bu yöntemde de uzaklık ölçüsü seçimi keyfi olarak gerçekleştirilemez.
C
Medyan değerlerine ait vektörleri küme merkezi olarak kullanan k merkezli algoritmadır.
D
Uzaklık ölçüsü seçilirken yakınsamanın sağlanıp sağlanmadığı mutlaka göz önünde bulundurulmalıdır.
E
Bu algoritmada, Manhattan uzaklık ölçüsü en sık tercih edilen kümelenme ölçütüdür.
Açıklama:
Bu yöntem- de de uzaklık ölçüsü seçimi keyfi olarak gerçekleştirilebilir, ancak yakınsamanın sağlanıp sağlanmadığı mutlaka göz önünde bulundurulmalıdır.
Soru 80
Aşağıdakilerden hangisi aşamalı olmayan kümeleme yöntemlerindendir?
Seçenekler
A
Küresel Ortalama Bağlantı Kümeleme Yöntemi
B
McQuitty Bağlantı Kümeleme Yöntemi
C
k-Medoidler Yöntemi
D
Ortalama Bağlantı Kümeleme Yöntemi
E
Tek Bağlantı Kümeleme Yöntemi
Açıklama:
k-Medoidler Yöntemi aşamalı olan kümeleme yöntemlerindendir.
Soru 81
Hem veri madenciliğinin temeli olarak hem de veri hazırlama aracı olarak kullanılan veri madenciliği yöntemi aşağıdakilerden hangisidir?
Seçenekler
A
Kümeleme
B
Sınıflandırma
C
Birliktelik kuralları
D
Karşılaştırma
E
Çaprazlama
Açıklama:
İnsanlar yüzyıllardır verileri sınıflandırdıkları, kategorize ettikleri ve derecelendirdikleri için sınıflandırma, işlemi hem veri madenciliğinin temeli olarak hem de veri hazırlama aracı olarak kullanılmaktadır.
Soru 82
Kümeleme analizinin temel amacı aşağıdakilerden hangisidir?
Seçenekler
A
Hangi olayların eş zamanlı olarak birlikte gerçekleşebileceklerinin ortaya koyulmasıdır.
B
Veri seti içerisinde yer alan kayıtların birbiriyle olan ilişkilerinin incelenmesidir.
C
Kümeler hakkında varsayımlarda bulunulmasıdır.
D
Hangi kümeye ait olduğu bilinmeyen bir grup verinin, sınıflandırılarak anlamlandırılmasıdır.
E
Kümelerin tahmin amaçlı kullanılmasıdır.
Açıklama:
Kümeleme analizinin temel amacı, hangi kümeye ait olduğu bilinmeyen bir grup verinin, sınıflandırılarak anlamlandırılmasıdır.
Soru 83
Kümeleme analizinin ilk aşaması aşağıdakilerden hangisidir?
Seçenekler
A
Veri matrisinin oluşturulması
B
Kümelemede esas alınacak yöntemlerin belirlenmesi
C
Benzerlik veya uzaklık matrislerinin hesaplanması
D
Bir ya da iki gözlemden oluşan kümelere şüphe ile bakılması
E
Elde edilen sonuçların yorumlanması
Açıklama:
Kümeleme analizi genellikle dört aşamada uygulanmaktadır. Bunlar; veri matrisinin oluşturulması, benzerlik veya uzaklık matrislerinin hesaplanması, kümelemede esas alınacak yöntemlerin belirlenmesi ve elde edilen sonuçların yorumlanmasıdır. Veri matrisinin oluşturulması, kümeleme analizinin ilk aşamasıdır.
Soru 84
Kümeleme analizinde gruplandırma neye göre yapılmaktadır?
Seçenekler
A
Eş zamanlı gerçekleşmesine göre
B
Literatürle benzerlik göstermesine göre
C
Kümeleme yöntemine göre
D
Örnekleme göre
E
Benzerlik ya da farklılık ölçülerine göre
Açıklama:
Kümeleme analizinde gruplandırma, benzerlik ya da farklılık ölçülerine göre yapılır.
Soru 85
"başlangıçta veri setinde bulunan tüm birimlerin farklı birer küme oluşturduğu kabul edilerek analize başlanır. Veri setinde bulunan n birimi aşamalı olarak sırasıyla; n küme, n-1 küme, n-2 küme, ..., n-r küme, ..., 3 küme, 2 küme, 1 kümeye yerleştirmeyi amaçlayan bir yaklaşımdır" şeklinde açıklanan kümeleme yöntemi hangisidir?
Seçenekler
A
Birleştirici Aşamalı Kümeleme Yöntemleri
B
Ayırıcı Aşamalı Kümeleme Yöntemleri
C
Dendrogramlar
D
Tek Bağlantı Kümeleme Yöntemi
E
Tam Bağlantı Kümeleme Yöntemi
Açıklama:
Birleştirici (agglomerative) aşamalı kümeleme yöntemleri, başlangıçta veri setinde bulunan tüm birimlerin farklı birer küme oluşturduğu kabul edilerek analize başlanır. Veri setinde bulunan n birimi aşamalı olarak sırasıyla; n küme, n-1 küme, n-2 küme, ..., n-r küme, ..., 3 küme, 2 küme, 1 kümeye yerleştirmeyi amaçlayan bir yaklaşımdır.
Soru 86
Kümeleme analizinde sonuçlar hangi yöntemle sunulur?
Seçenekler
A
Dendogramlar
B
Birleştirici Aşamalı Kümeleme
C
Ayırıcı Aşamalı Kümeleme
D
Küresel Ortalama Bağlantı Kümeleme
E
Ward Bağlantı Kümeleme
Açıklama:
Kümeleme analizinde sonuçlar dendrogram (ağaç diyagramı) adı verilen grafiksel yöntemle sunulurlar.
Soru 87
Aşamalı olmayan Kümeleme Yöntemleri arasında en yaygın kullanılan yöntem hangisidir?
Seçenekler
A
K-ortalamalar kümeleme
B
k-Medyanlar Yöntemi
C
k-Medoidler Yöntemi
D
k-tepe noktası Yöntemi
E
k-Sapma Yöntemi
Açıklama:
Aşamalı olmayan Kümeleme Yöntemleri arasında en yaygın kullanılan yöntem
K-ortalamalar kümeleme (k-means clustering, MacQueens’ Method) yöntemidir.
K-ortalamalar kümeleme (k-means clustering, MacQueens’ Method) yöntemidir.
Soru 88
Hangisi küresel ortalama ve medyan bağlantı kümeleme yöntemlerinin karma şeklidir?
Seçenekler
A
Ward Bağlantı Kümeleme Yöntemi
B
Medyan Bağlantı Kümeleme Yöntemi
C
Küresel Ortalama Bağlantı Kümeleme Yöntemi
D
McQuitty Bağlantı Kümeleme Yöntemi
E
Ortalama Bağlantı Kümeleme Yöntemi
Açıklama:
Ward Bağlantı Kümeleme Yöntemi: Bu yöntem, küresel ortalama ve medyan bağlantı kümeleme yöntemlerinin karma şeklidir.
Soru 89
Tam bağlantı kümeleme yöntemindeki uzaklıkların hesaplanması aşağıdakilerden hangisinde doğru olarak verilmiştir?
Seçenekler
A
dmj= (dkj + dlj)/2
B
dmj= (Nkdkj + Nldlj)/Nm
C
dmj= maks(dkj,dlj)
D
dmj= (dkj + dlj)/2 - dkl/4
E
dmj=min (dkj, dlj)
Açıklama:
Tam bağlantı tekniğindeki uzaklıklar,
dmj=maks(dkj,dlj)
biçiminde hesaplanmaktadır.
dmj=maks(dkj,dlj)
biçiminde hesaplanmaktadır.
Soru 90
"Bir kümeyi oluşturan gözlemlerin ortalamalarını esas alır. Kümede sadece tek bir merkez varsa onun değeri merkez olarak kabul edilir. Ortalama bağlantı kümeleme yönteminin farklı bir biçimidir" şeklinde tanımlanan yöntem hangisidir?
Seçenekler
A
Tek Bağlantı Kümeleme Yöntemi
B
Tam Bağlantı Kümeleme Yöntemi
C
Ortalama Bağlantı Kümeleme Yöntemi
D
McQuitty Bağlantı Kümeleme Yöntemi
E
Küresel Ortalama Bağlantı Kümeleme Yöntemi
Açıklama:
Küresel Ortalama Bağlantı Kümeleme Yöntemi: Bir kümeyi oluşturan gözlemlerin ortalamalarını esas alır. Kümede sadece tek bir merkez varsa onun değeri merkez olarak kabul edilir. Ortalama bağlantı kümeleme yönteminin farklı bir biçimidir.
Soru 91
R yazılımında kmeans(ulkeler.variable,3) komutu ne amaçla kullanılır?
Seçenekler
A
Ortalama hesabı
B
Korelasyon hesabı
C
Kümeleme analizi
D
Regresyon modellemesi
E
Hipotez testi
Açıklama:
kmeans komut komutta verilen sayıda kümeyi bulmak için k-ortalamalar tekniğini kullanır.
Soru 92
R'de verilen
plot(x[c(“D1”,”D4”)], col=results$cluster)
komut dizilimi ile ne hedeflenmektedir?
plot(x[c(“D1”,”D4”)], col=results$cluster)
komut dizilimi ile ne hedeflenmektedir?
Seçenekler
A
Kümelere ait grafikler çizilir
B
Korelasyon değerleri eklenir
C
Elips çizimler yapılır
D
Model sonuçları grafiğe eklenir
E
Varyans analizi yapılır
Açıklama:
R’da Eğer D1 ve D4 değişkenlerine göre, kümelere ait grafik çizdirilmek istenirse plot(x[c(“D1”,”D4”)], col=results$cluster) komutu kullanılır. Grafik Şekil 7.19’da verilmiştir. Burada kümelerdeki birimler sırasıyla “o”, “*” ve “+” işaretleri ile gösterilmiş ve kolay anlaşılması için ise kutucuklar içerisine alınmıştır.
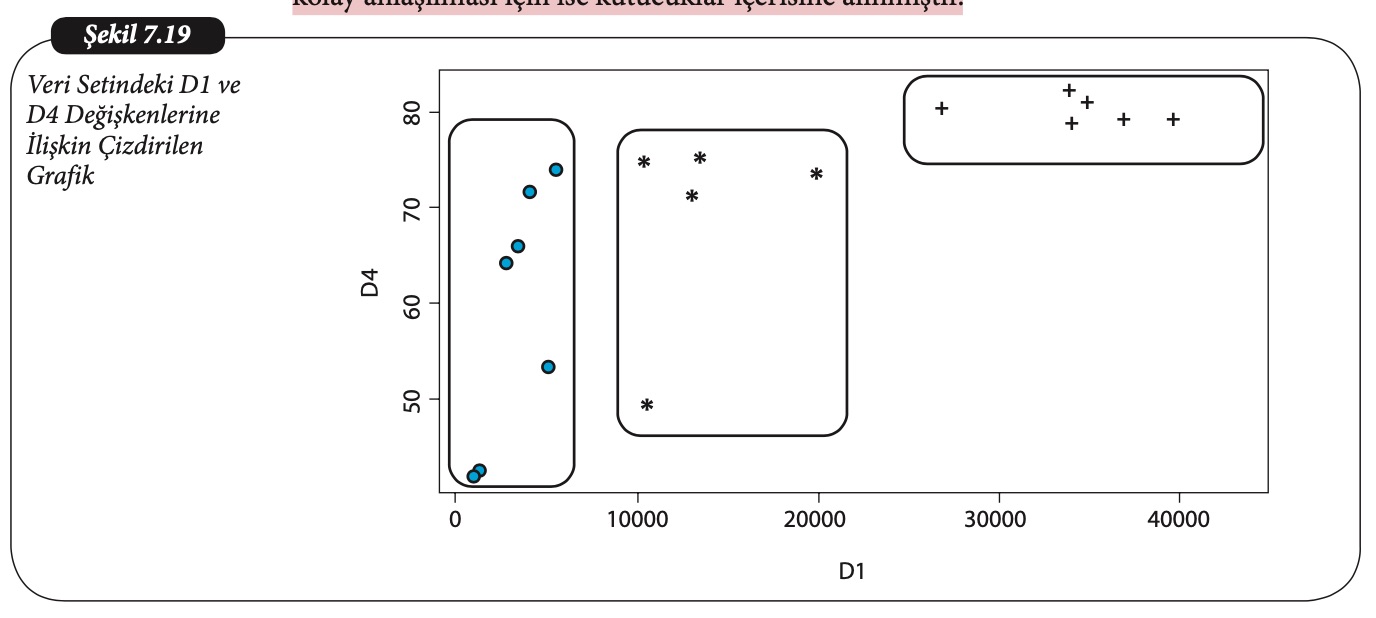
Soru 93
Verilen R çıktısına göre son gözlem değeri hangi kümede yer almaktadır?
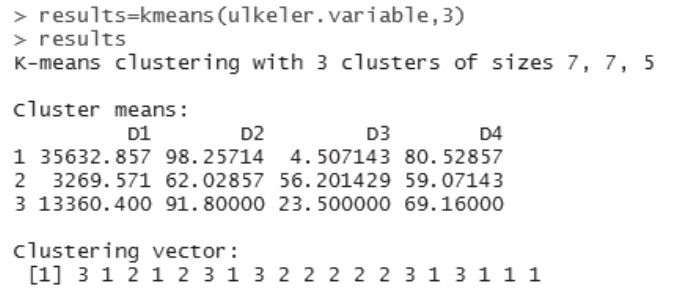
Seçenekler
A
5
B
4
C
3
D
2
E
1
Açıklama:
Clustering vector: birimlerin ait oldukları kümeleri göstermektedir. BU vektör incelendiğinde son gözlem biriminin 1 numaralı kümede yer aldığı görülür.
Soru 94
Verilen R çıktısına göre Brezilya hangi kümede yer almaktadır?
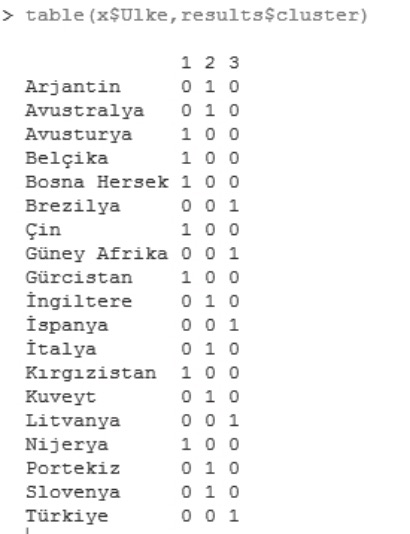
Seçenekler
A
1
B
3
C
2
D
4
E
6
Açıklama:
Çıktıda brezilya bulunduğunda ait olunan küme 3 olmaktadır.
Soru 95
Verilen R çıktısına göre 2 numaralı kümede kaç ülke yer almaktadır?
Seçenekler
A
6
B
7
C
8
D
9
E
10
Açıklama:
2 numaralı kümede yer alan birimler sayıldığında (1 değerleri) 7 ülke olduğu görülebilir.
Soru 96
Kümeleme analizinin ilk aşaması aşağıdakilerden hangisidir?
Seçenekler
A
Veri matrisinin oluşturulması
B
Algoritmanın yazılması
C
Benzerliklerin hesaplanması
D
Uzaklıkların hesaplanması
E
Kümeleme işleminde kullanılacak yöntemin belirlenmesi
Açıklama:
İlk aşamada gözlem değerleri analize hazır hale getirilir; yani veri matrisi oluşturulur.
Soru 97
Birbirine en yakın olan birimlerden yola çıkarak verilerin kümelenmesini sağlayan aşamalı yöntem aşağıdakilerden hangisidir?
Seçenekler
A
Tam bağlantı kümeleme
B
Tek bağlantı kümeleme
C
Ortalama bağlantı kümeleme
D
Medyan bağlantı kümeleme
E
Küresel ortalama bağlantı kümeleme
Açıklama:
En yakın komşular olarak da bilinen yöntem, tek bağlantı kümeleme yöntemidir.
Soru 98
Bir kümeleme işleminde kullanılacak değişkenlerden biri 1-280 arasında değerler alabilirken diğerleri ise 1-10 arasında değer almaktadır. Yapılan kümeleme işlemi sonrasında ranjı büyük olan değişkenin, kümelerin belirlenmesinde baskın bir rol aldığı görülmüştür. Bu duruma çözüm bulmak amacıyla aşağıdakilerden hangisi yapılabilir?
Seçenekler
A
Eğitim verisini büyütme
B
Test verisini büyütme
C
Verileri standardize etme
D
Benzerlik ölçüsünü değiştirme
E
Uzaklık ölçüsünü değiştirme
Açıklama:
Farklı ölçek düzeylerinde yer alan değişkenlerden ranjı ve dolayısıyla varyansı büyük olanlar, kümeleme işlemi sırasında diğerlerini baskılayarak elde edilen sonuçlarda yanlılığa neden olabilir. Bu durumu engellemek amacıyla verilerde standardizasyon ya da dönüştürme işleminin yapılması gerekir.
Soru 99
Ozan, bir web sitesi üzerinden kitap siparişi yaparken sistemin "bu kitabı alanlar şu kitapları da aldılar" mesajıyla bir kaç kitap önerisinde bulunduğunu görmüştür?
Bu algoritmanın oluşturulmasında kullanılan istatistiksel yöntem aşağıdakilerden hangisi olabilir?
Bu algoritmanın oluşturulmasında kullanılan istatistiksel yöntem aşağıdakilerden hangisi olabilir?
Seçenekler
A
Lojistik regresyon
B
Diskriminant analizi
C
Karar ağaçları
D
k-en yakın komşular
E
Regresyon
Açıklama:
Kümeleme analizine dayalı yöntemlerde bir tahmin yerine değişkenlerin benzer özelliklerine göre homojen, farklı özellikleri baz alınarak ise heterojen gruplar oluşturması beklenir. Sorudaki örnek durumda, benzer özelliklerine göre (satın alınma durumları) kitapların benzer gruplarda yer almaları nedeniyle birini alana,m diğerlerinin önerildiği söylenebilir. Doğru yanıt, en yakın komşulardır.
Soru 100
Birimlerin, küme içi kareler toplamını mümkün olan en küçük değere göre belirlenmesine dayanan, aşamalı olmayan kümeleme yöntemi aşağıdakilerden hangisidir?
Seçenekler
A
k-ortalamalar
B
k-medyanlar
C
k-en yakın komşular
D
Ortalama bağlantı
E
Medyan bağlantı
Açıklama:
k-ortalamalar yönteminde, birimlerin kümelere yerleştirilmesi iteratif biçimde yapılır. Her defansında birimler farklı kümelerde yer alır ve küme içi kareler toplamını minimize eden küme sayısı ve aidiyeti bu iterasyonlar sonucunda belirlenir.
Ünite 8
Soru 1
Aşağıdakilerden hangisi veri madenciliği sürecinin temel adımlarından biri değildir?
Seçenekler
A
Verinin elde edilmesi
B
Verinin saklanması ve yönetimi
C
Veri erişiminin sağlanması
D
Verinin analiz edilmesi
E
Bilgi seçimi ve ön işleme
Açıklama:
Bilgi seçimi ve ön işleme;veri madenciliği sürecinin temel adımlarından biri değildir.
Soru 2
Aşağıdakilerden hangisi veri madenciliği uygulama alanlarından değildir?
Seçenekler
A
Bankacılık
B
İmalat
C
Sağlık
D
E-Devlet
E
Hukuk
Açıklama:
E-Devlet veri madenciliği uygulama alanlarından birisi değildir.
Soru 3
Aşağıdakilerden hangisi web madenciliği uygulama alanlarından değildir?
Seçenekler
A
Bankacılık
B
E-Öğrenme
C
Dijital Kütüphaneler
D
Elektronik Ticaret
E
E- Devlet
Açıklama:
Bankacılık web madenciliğinin uygulama alanlarından birisi değildir.
Soru 4
Aşağıdakilerden hangisi veri madenciliğinin uygulama ve kullanım sürecinde dezavantajlarından değildir?
Seçenekler
A
Gizlilik sorunları
B
Güvenlik sorunları
C
URL’ler izlenerek veriye erişile bilinmesi
D
Bilginin kötüye kullanımı
E
Eksik bilgilendirmeler
Açıklama:
URL’ler izlenerek veriye erişile bilinmesi, veri madenciliğinin uygulama ve kullanım sürecinde dezavantajlarından değildir?
Soru 5
Aşağıdakilerden hangisi web ortamında bulunan verilerin standart veri tabanı yönetim sistemleri verilerinden farklı olarak kendine özgü özelliklerinden değildir?
Seçenekler
A
Web ortamındaki veri miktarı aşırı büyüklüktedir
B
Web ortamındaki veri dağınık ve heterojen bir yapıdadır.
C
Web ortamındaki veri yapılandırılmamıştır.
D
Web ortamındaki veri dinamiktir.
E
Web ortamındaki veriler sadece belirli bir konudadır
Açıklama:
Web ortamındaki veriler sadece belirli bir konuda olması web ortamında bulunan verilerin standart veri tabanı yönetim sistemleri verilerinden farklı olarak kendine özgü özelliklerinden değildir?
Soru 6
Web içerik madenciliğinde; bilgiye erişim yaklaşımı temeline dayanan, bilgiye erişimi çok daha kolay hâle getiren enstrüman hangisidir?
Seçenekler
A
Sunucusu
B
Arama motorları
C
OLAP
D
Veri tabanı
E
HTML
Açıklama:
Arama motorları:Arama motorları ise klasik bilgiye erişimi çok daha kolay hâle getiren,bilgiye erişim yaklaşımı temeline dayanan web içerik madenciliğinin vazgeçilmez bir enstrümanıdır.
Soru 7
Herhangi web sitesinin yapısal özetini, yani kendi içerisindeki sayfalarla ve diğer sitelerle olan bağlantı yapılarını elde ederek, bu yapılardan yararlı bilginin ortaya çıkarılmasına ne denir?
Seçenekler
A
Veri Madenciliği
B
Web Madenciliği
C
Web Yapı Madenciliği
D
Web Görüş Madenciliği
E
Web Tarama Madenciliği
Açıklama:
Web Yapı Madenciliği: Web yapı madenciliği, web sitesinin yapısal özetini yani kendi içerisindeki sayfalarla ve diğer sitelerle olan bağlantı yapılarını elde ederek, bu yapılardan yararlı bilginin ortaya çıkarılması olarak tanımlanabilir
Soru 8
Aşağıdakilerden hangisi web madenciliği sürecinin, Veri Ön İşleme aşamasının adımlarından birisi değildir?
Seçenekler
A
Verinin Temizlenmesi
B
Kullanıcı Bilgisinin Belirlenmesi
C
Oturum Bilgisinin Belirlenmesi
D
İz (Yol) Tamamlama
E
Verileri XML dosyası olarak depolama
Açıklama:
Verileri XML dosyası olarak depolama bu konuyla alakalı değildir.
Soru 9
Kullanıcıların belirli bir zaman aralığındaki farklı oturumları arasında bir birini takip eden kullanıcı hareketleri arasındaki ilişkilerinin ortaya konulmasına ne denir?
Seçenekler
A
İstatiksel Analiz
B
İlişki Kuralları:
C
Sınıflandırma Analizi
D
Sıralı Örüntüler
E
Kümeleme Analizi
Açıklama:
Sıralı Örüntüler: Sıralı örüntüler ile kullanıcıların belirli bir zaman aralığındaki farklı oturumları arasında birbirini takip eden kullanıcı hareketleri arasındaki ilişkilerinin ortaya konulmasıdır.
Soru 10
Aşağıdakilerden hangisi web içerik madenciliğinde kullanılan yöntemlerden birisi değildir?
Seçenekler
A
Kümeleme Analizi
B
Otomatik Öğrenme
C
İlişki Kuralları
D
Özel Algoritmalar
E
İstatiksel Yöntemler
Açıklama:
Kümeleme Analizi web içerik madenciliğinde kullanılan yöntemlerden birisi değildir.
Soru 11
Veri madenciliğinin tarihsel süreci göz önünde bulundurulduğunda seçeneklerden günümüzde web madenciliğinde kullanılan bir teknolojidir?
Seçenekler
A
Gelişmiş algoritmalar
B
Çok işlemcili bilgisayarlar
C
Çok büyük veritabanları
D
İnternet
E
Manyetik bantlar
Açıklama:
İnternet günümüzde kullanılan veri madenciliği teknolojilerinden birisidir. Diğer teknolojiler tarihsel süreçte önceden kullanılan teknolojilerdendir.
Soru 12
Seçeneklerden hangisi web madencilğinin uygulama alanlarından birisidir?
Seçenekler
A
Bankacılık
B
Pazarlama
C
Hukuk
D
Sigorta
E
Güvenlik soruşturması
Açıklama:
Güvenlik soruşturması bir web madenciliği uygulama alanıdır. Diğer alanlar veri madenciliği uygulama alanlarındandır.
Soru 13
Veri madenciliği ile karşılaştırıldığında Web madenciliğine ilişkin verilen seçeneklerden hangisi yanlıştır?
Seçenekler
A
Bilgiler yapılandırılmış, yarı yapılandırılmış ve yapılandırılmamış formlarından elde edildiği için geniş bir veritabanından bilgi sağlanır.
B
Veritabanı 1 milyon iş içerir ve işleme süreci uzundur.
C
Veri gizli değildir. Sadece kayıt dosyalarına erişebilmek için izin gerekir.
D
Web sayfalarının karmaşıklığı, webin büyüklüğü, bilginin bağlantısı, bilginin dinamikliği, kullanıcı iletişiminin çeşitliliği gibi zorlukları bulunmaktadır.
E
URL’ler izlenerek veriye erişilebilinmesi, olayların ve URL’lerin çeşitliliği ve verilerin büyük bir kısmı kullanılmadan kalması dezavantajlarıdır.
Açıklama:
Veritabanının 1 milyon iş içermesi ve işleme süreci uzun olması veri madenciliği ölçeğidir. Web madenciliğinde ölçek sunucu veritabanı 10 milyon iş içermesine rağmen işleme süreci kısadır.
Soru 14
Seçeneklerden hangisi internet ortamından yararlı bilginin keşfi için, web madenciliği sürecinin temel adımlarından birisi değildir?
Seçenekler
A
Kaynak tespiti
B
Bilgi seçimi ve ön işleme
C
Genelleştirme
D
Bütünleştirme
E
Analiz
Açıklama:
İnternet ortamından yararlı bilginin keşfi için, web madenciliği sürecini dört temel
adımda ele alabiliriz.
1. Kaynakların Tespiti
2. Bilgi Seçimi ve Ön İşleme
3. Genelleştirme
4. Analiz
adımda ele alabiliriz.
1. Kaynakların Tespiti
2. Bilgi Seçimi ve Ön İşleme
3. Genelleştirme
4. Analiz
Soru 15
Seçeneklerden hangisi web madenciliği veri türlerinden birisi değildir?
Seçenekler
A
İçerik
B
Yapı
C
Sunucu
D
Kullanım
E
Kullanıcı profili
Açıklama:
Web madenciliğinde kullanılan verileri dört başlıkta incelenir. İçerik verisi, yapı verisi, kullanım verisi ve kullanıcı profil verisidir.
Soru 16
Seçeneklerden hangisi web verisinin özelliklerinden birisidir?
Seçenekler
A
Veri miktarının küçük olması
B
Veri yapısının homojen olması
C
Durağan olması
D
Yapılandırılmış olması
E
Verilerin dağınık olması
Açıklama:
Web verisi özellikleri aşağıdaki gibi sıralanır.
Web ortamındaki veri miktarı aşırı büyüklüktedir.
Web ortamındaki veri dağınık ve heterojen bir yapıdadır.
Web ortamındaki veri yapılandırılmamıştır.
Web ortamındaki veri dinamiktir.
Web ortamındaki veri miktarı aşırı büyüklüktedir.
Web ortamındaki veri dağınık ve heterojen bir yapıdadır.
Web ortamındaki veri yapılandırılmamıştır.
Web ortamındaki veri dinamiktir.
Soru 17
Akademik olarak yazarlar ile yayınları arasındaki ilişkiyi kurmak için yapılan analiz türü seçeneklerden hangisidir?
Seçenekler
A
Atıf analizi
B
İnternette arama ve bağlantı köprüleri
C
Bilgi keşfi
D
Kısa metin işleme
E
Web arama
Açıklama:
Atıf analizi, akademik olarak yazarlar ile yayınları arasındaki ilişkiyi kurmak için yapılan
alıntıları inceleyen bir araştırma alanıdır. Bir yayın başka bir yayından alıntı yaptığında bu iki yayın arasında bir ilişki veya bağlantı kurulmuş olur. Dolayısıyla atıf analizinde de bu bağlantılar incelenerek yayınların önem düzeyleri ortaya konulmaya çalışılır.
Günümüzde bir yayının önemini belirleyen en önemli ölçü “impact factor” yani etki faktörüdür. Ortak atıf ve bibliyografik eşleme, HITS algoritmasını temel alan ve atıf analizinde dokümanların kümelenmesinde kullanılan benzerlik ölçüleridir.
alıntıları inceleyen bir araştırma alanıdır. Bir yayın başka bir yayından alıntı yaptığında bu iki yayın arasında bir ilişki veya bağlantı kurulmuş olur. Dolayısıyla atıf analizinde de bu bağlantılar incelenerek yayınların önem düzeyleri ortaya konulmaya çalışılır.
Günümüzde bir yayının önemini belirleyen en önemli ölçü “impact factor” yani etki faktörüdür. Ortak atıf ve bibliyografik eşleme, HITS algoritmasını temel alan ve atıf analizinde dokümanların kümelenmesinde kullanılan benzerlik ölçüleridir.
Soru 18
Web sitelerinde var olan metinsel verinin derlenmesi ve sınıflandırılması işlemi olarak tanımlanan web madenciliği türü hangisidir?
Seçenekler
A
Atıf analizi
B
İnternette arama ve bağlantı köprüleri
C
Bilgi keşfi
D
Kısa metin işleme
E
Web arama
Açıklama:
Kısa metin işleme, web sitelerinde var olan metinsel verinin derlenmesi ve sınıflandırılması işlemi olarak tanımlanabilir. Konuya göre dokümanların sınıflandırılmasında ve web sayfalarının alt kategorilere ayrılmasında kullanılan algoritmalar bütünüdür. Kısa metinlerin en bilindik uygulaması arama motorlarının kullanıcıya sunduğu aranılan kelimeyi tamamlayıcı nitelikte olan “ilgili aramalar” uygulamasıdır. Kısa metin işleme algoritmaları, klasik metin işleme yaklaşımlarından farklı olarak çok daha az sayıda kelimenin analiz edilmesi temeli üzerine kurulan algoritmalardır.
Soru 19
Ana hedefi şirket performansını artırmak ve pazarda rekabet avantajı sağlamak için insanların doğru kararlar almalarına yardımcı olmak olan web madenciliği sınıflandırması hangisidir?
Seçenekler
A
Kişiselleştirme
B
İş zekası
C
Kullanım karakteristiği
D
Örüntü analizi
E
Sistem geliştirme
Açıklama:
İş zekasının ana hedefi şirket performansını artırmak ve pazarda rekabet avantajı sağlamak için insanların doğru kararlar almalarına yardımcı olmaktır. Web kullanım madenciliği müşteri davranışları hakkında bilgileri ayıklamak ve yararlı ve etkili bir veritabanı oluşturmak için uygun bir tekniktir. İnternet üzerinden yapılan ürün ve hizmet satışları için müşteri potansiyelini arttırmak, var olan müşterinin devamlılığını sağlamak, daha çok satış gerçekleştirebilmek ve daha etkin bir lojistik ve stok yönetimi gerçekleştirebilmek için web kullanım madenciliği sonuçlarından yararlanılabilir.
Soru 20
Seçeneklerden hangisi günümüzde kullanılmakta olan sosyal medya hizmetlerini temel sınıflandırmasına dahil edilemez?
Seçenekler
A
Arkadaş tabanlı
B
Bilgilendirici
C
Mesleki
D
Eğitim
E
Kötüye kullanma
Açıklama:
günümüzde kullanılmakta olan sosyal medya hizmetlerini temel olarak izleyen biçimde sınıflandırmak mümkündür.
1. Genel amaçlı veya arkadaş tabanlı: Bu hizmetler belirli bir konu üzerine odaklanmayan arkadaşlık temeline dayanan paylaşım hizmetleridir.
2. Bilgilendirici: Bu hizmetlerin amacı günlük sorunlara yanıtlar sunmaktır.
3. Mesleki: Bu hizmetler kariyer veya meslek planlamasında yeni fırsatlar edinmek
için kullanılır.
4. Eğitim: Bu hizmetler öğrencinin deneyimini geliştirmek için kullanılır.
5. Hobiler: Bu hizmetler aynı şeylere ilgi duyan insanlar için bir buluşma noktasıdır.
6. Akademik: Bu hizmetler akademik ve bilimsel çalışmalar için güncel bilgi kaynağına erişim sunan hizmetlerdir.
7. Haberler: Bu hizmetler tüm toplumu ilgilendiren haber yayıncılığına ilişkin hizmetlerdir.
1. Genel amaçlı veya arkadaş tabanlı: Bu hizmetler belirli bir konu üzerine odaklanmayan arkadaşlık temeline dayanan paylaşım hizmetleridir.
2. Bilgilendirici: Bu hizmetlerin amacı günlük sorunlara yanıtlar sunmaktır.
3. Mesleki: Bu hizmetler kariyer veya meslek planlamasında yeni fırsatlar edinmek
için kullanılır.
4. Eğitim: Bu hizmetler öğrencinin deneyimini geliştirmek için kullanılır.
5. Hobiler: Bu hizmetler aynı şeylere ilgi duyan insanlar için bir buluşma noktasıdır.
6. Akademik: Bu hizmetler akademik ve bilimsel çalışmalar için güncel bilgi kaynağına erişim sunan hizmetlerdir.
7. Haberler: Bu hizmetler tüm toplumu ilgilendiren haber yayıncılığına ilişkin hizmetlerdir.
Soru 21
aşağıdakilerden hangisi veri toplama döneminde (1960) kullanılan teknolojilerden biridir?
Seçenekler
A
İnternet
B
Devasa ölçekli veritabanı
C
Çok büyük veritabanları
D
Gelişmiş algoritmalar
E
Bilgisayar
Açıklama:
bu döneme ilişkin teknikler aşağıda sıralanmıştır:
- Bilgisayar
• Manyetik bantlar
• Diskler.
Soru 22
aşağıdakilerden hangisi veri erişimi dönemine(1980) ilişkin kullanılan teknolojilerden biridir?
Seçenekler
A
Veri ambarları
B
Çok büyük veritabanları
C
Gelişmiş algoritmalar
D
Veri ambarları
E
Yapı sorgu dili (SQL)
Açıklama:
bu teknikler şu şekilde sıralanabilir:
- İlişkisel veritabanı (RDBMS)
• Yapı sorgu dili (SQL)
• Açık veritabanı bağlantısı
(ODBC).
Soru 23
aşağıdakilerden hangisi veri madenciliği döneminde (2000) kullanılan tekniklerden biridir?
Seçenekler
A
Manyetik bantlar
B
Diskler
C
Çok boyutlu veritabanları
D
Devasa ölçekli veritabanı
E
Gelişmiş algoritmalar
Açıklama:
bu döneme ilişkin teknikler şu şekilde sıralanabilir:
- Gelişmiş algoritmalar
• Çok işlemcili bilgisayarlar
• Çok büyük veritabanları.
Soru 24
aşağıdakilerden hangisi veri madenciliği sürecine ilişkin adımlardan biri değildir?
Seçenekler
A
Verinin elde edilmesi
B
Verinin saklanması ve yönetim
C
Veri erişiminin sağlanması
D
Verinin analiz edilmesi
E
verilerin sosyal ağlarda tartışılması
Açıklama:
Veri madenciliği,
i. Verinin elde edilmesi
ii. Verinin saklanması ve yönetimi
iii. Veri erişiminin sağlanması
iv. Verinin analiz edilmesi
v. Analiz sonuçlarının anlaşılır bir biçimde sunulması
temel adımlarından oluşan bir süreçtir.
verilerin sosyal ağlarda tartışılması
i. Verinin elde edilmesi
ii. Verinin saklanması ve yönetimi
iii. Veri erişiminin sağlanması
iv. Verinin analiz edilmesi
v. Analiz sonuçlarının anlaşılır bir biçimde sunulması
temel adımlarından oluşan bir süreçtir.
verilerin sosyal ağlarda tartışılması
Soru 25
aşağıda veri madenciliğine ilişkin verilen bilgilerden hangisi doğrudur?
Seçenekler
A
amacı web belgelerinden bilgi çıkarsamaktır
B
Çevrimiçi veriler kullanılır
C
Web içerik madenciliği tekniğini kullanır
D
Web yapı madenciliği tekniğini kullanır
E
Yapay sinir ağlarını kullanır
Açıklama:
veri madenciliği şu teknikleri kullanır:
Yapay sinir ağlarını kullanır
- Yapay sinir ağları
• Karar ağaçları
• İlişki kuralları
• En yakın komşu yöntemi
Yapay sinir ağlarını kullanır
Soru 26
aşağıdakilerden hangisi web madenciliği uygulama alanlarından biridir?
Seçenekler
A
Bankacılık
B
Pazarlama
C
İmalat
D
Sağlık
E
E-öğrenme
Açıklama:
web madenciliğinin uygulama alanları şu şekildedir:
- E-öğrenme
• Dijital Kütüphaneler
• E-Devlet
• Elektronik Ticaret
• E-Siyaset
• E-Demokrasi
• Güvenlik ve Suç Soruşturması vb.
Soru 27
aşağıdakilerden hangisi web madenciliğinin sürecinin temel adımlarından biri değildir?
Seçenekler
A
Kaynakların Tespiti
B
Bilgi Seçimi ve Ön İşleme
C
Genelleştirme
D
Analiz
E
Uzmanların Tespiti
Açıklama:
İnternet ortamından yararlı bilginin keşfi için, web madenciliği sürecini dört temel
adımda ele alabiliriz:
1. Kaynakların Tespiti: İlgilenilen konuda bilgi içeren web dokümanlarının belirlenmesi ve elde edilmesi.
2. Bilgi Seçimi ve Ön İşleme: Elde edilen kaynaklardan ihtiyaç duyulan bilginin otomatik olarak seçilmesi ve kullanılabilir hâle getirilmesi.
3. Genelleştirme: Bireysel web sitelerindeki örüntü (pattern) veya kuralların otomatik
olarak çıkarılması ve diğer web siteleri ile karşılaştırarak genellenmesi.
4. Analiz: Elde edilen genel örüntü veya kuralların doğruluklarının onaylanması ve / veya yorumlanması.
Uzmanların Tespiti
adımda ele alabiliriz:
1. Kaynakların Tespiti: İlgilenilen konuda bilgi içeren web dokümanlarının belirlenmesi ve elde edilmesi.
2. Bilgi Seçimi ve Ön İşleme: Elde edilen kaynaklardan ihtiyaç duyulan bilginin otomatik olarak seçilmesi ve kullanılabilir hâle getirilmesi.
3. Genelleştirme: Bireysel web sitelerindeki örüntü (pattern) veya kuralların otomatik
olarak çıkarılması ve diğer web siteleri ile karşılaştırarak genellenmesi.
4. Analiz: Elde edilen genel örüntü veya kuralların doğruluklarının onaylanması ve / veya yorumlanması.
Uzmanların Tespiti
Soru 28
aşağıdakilerden hangisinde web madenciliğinde veri kaynaklarından biri değildir?
Seçenekler
A
İçerik verisi
B
Yapı verisi
C
Kullanım verisi
D
Kullanıcı profil verisi
E
kullanıcı erişim izni
Açıklama:
Web madenciliğinde kullanılan
verileri dört başlıkta inceleyebiliriz.
1. İçerik verisi: Web sayfalarında kullanıcının erişimine sunulan verilerdir. Bunlar
şekil, resim, grafik, görüntü ve ses dosyaları gibi gerçek verilerin yanısıra, tanımlayıcı kelimeler, etiketler ve doküman özellikleri gibi verilerden oluşmaktadır. İçerik
verisi düz metin gibi yapılandırılmamış, HTML dokümanları gibi yarı yapılandırılmış veya veritabanlarından elde edilen veriler şeklindeki yapılandırılmış verileri
içerir.
2. Yapı verisi: Bir web sitesinin içeriğinde yer alan sayfaların birbirleri ile veya diğer
web siteleri ile olan bağlantılarının, tasarımını yapan kişi tarafından nasıl düzenlendiğine dair bilgilerdir. Yapı verisi, bir web sayfasının oluşturulmasında kullanılan HTML veya XML etiketleri gibi veri yapıları olabileceği gibi, sayfalar hatta
siteler arası bağlantıları sağlayan linkler şeklindeki veri yapıları da olabilir. Daha
kısa bir ifadeyle yapı
kullanıcı erişim izni
verileri dört başlıkta inceleyebiliriz.
1. İçerik verisi: Web sayfalarında kullanıcının erişimine sunulan verilerdir. Bunlar
şekil, resim, grafik, görüntü ve ses dosyaları gibi gerçek verilerin yanısıra, tanımlayıcı kelimeler, etiketler ve doküman özellikleri gibi verilerden oluşmaktadır. İçerik
verisi düz metin gibi yapılandırılmamış, HTML dokümanları gibi yarı yapılandırılmış veya veritabanlarından elde edilen veriler şeklindeki yapılandırılmış verileri
içerir.
2. Yapı verisi: Bir web sitesinin içeriğinde yer alan sayfaların birbirleri ile veya diğer
web siteleri ile olan bağlantılarının, tasarımını yapan kişi tarafından nasıl düzenlendiğine dair bilgilerdir. Yapı verisi, bir web sayfasının oluşturulmasında kullanılan HTML veya XML etiketleri gibi veri yapıları olabileceği gibi, sayfalar hatta
siteler arası bağlantıları sağlayan linkler şeklindeki veri yapıları da olabilir. Daha
kısa bir ifadeyle yapı
kullanıcı erişim izni
Soru 29
aşağıdakilerden hangisi web kullanım madenciliğinin temel uygulama alanlarından biri değildir?
Seçenekler
A
Kişiselleştirme
B
Sistem Geliştirme
C
Web Sitesi Güncelleme
D
İş Zekası
E
veri tabanı güncelleme
Açıklama:
Web Kullanım Madenciliği Temel Uygulama Alanları şu şekilde sıralanabilir:
veri tabanı güncelleme
- Kişiselleştirme (Personalization)
- Sistem Geliştirme (System Improvement)
- Web Sitesi Güncelleme (Site Modification)
- İş Zekası (Business Intelligence)
- Kullanım Karakteristiği (Usage Characterization).
veri tabanı güncelleme
Soru 30
aşağıdakilerden hangisi web içerik madenciliğinin uygulama alanlarından biri değildir?
Seçenekler
A
Kümeleme
B
Sınıflandırma
C
Örüntü ve kural çıkarımı
D
Kullanıcı modellemesi
E
Pazarlama
Açıklama:
bu uygulama alanları şu şekilde sıralanabilir:
Pazarlama
- Kümeleme
• Sınıflandırma
• Örüntü ve kural çıkarımı
• Kullanıcı modellemesi
• Web şeması modelleme
Pazarlama
Soru 31
“Web bağlantı yapılarının modellenmesi” hangi web madenciliği
sınıfının temel amacıdır?
sınıfının temel amacıdır?
Seçenekler
A
Sosyal medya madenciliği
B
Web yapı madenciliği
C
Web profil madenciliği
D
Web içerik madenciliği
E
Web kullanım madenciliği
Açıklama:
Web yapı madenciliği, web sitesinin yapısal özetini yani kendi içerisindeki sayfalarla ve diğer
sitelerle olan bağlantı yapılarını elde ederek, bu yapılardan yararlı bilginin ortaya çıkarılması
olarak tanımlanabilir. Bu sayede web sayfaları sınıflandırılabilir ve farklı web siteleri
arasındaki benzerlik ve ilişkiler ortaya çıkarılabilir. Böylece web sitelerinin verimlilik
ve kullanışlılık değerlendirmeleri yapılabilir. Web yapı madenciliği ile internet ortamında
birçok insan tarafından başvurulan ve alanında otorite olarak nitelendirilen önemli web
sayfaları da belirlenebilmektedir.
sitelerle olan bağlantı yapılarını elde ederek, bu yapılardan yararlı bilginin ortaya çıkarılması
olarak tanımlanabilir. Bu sayede web sayfaları sınıflandırılabilir ve farklı web siteleri
arasındaki benzerlik ve ilişkiler ortaya çıkarılabilir. Böylece web sitelerinin verimlilik
ve kullanışlılık değerlendirmeleri yapılabilir. Web yapı madenciliği ile internet ortamında
birçok insan tarafından başvurulan ve alanında otorite olarak nitelendirilen önemli web
sayfaları da belirlenebilmektedir.
Soru 32
- Veri ön işleme
- Örüntü keşfi
- Örüntü analizi
Seçenekler
A
I
B
II
C
III
D
II VE III
E
I ve II
Açıklama:
Örüntü keşfi
Bu aşama, veri ön işleme aşamasından geçirilmiş analize hazır olan verilere veri madenciliği tekniklerinin uygulanarak yararlı bilginin ortaya çıkarılması aşamasıdır. Bu aşamada işlenmiş veriden önemli ve anlamlı bilgiyi ortaya çıkarabilmek adına istatistiksel analiz, ilişki kuralları, sınıflandırma analizi, kümeleme analizi ve sıralı örüntüler vb. gibi veri madenciliği teknikleri kullanılır.
Bu aşama, veri ön işleme aşamasından geçirilmiş analize hazır olan verilere veri madenciliği tekniklerinin uygulanarak yararlı bilginin ortaya çıkarılması aşamasıdır. Bu aşamada işlenmiş veriden önemli ve anlamlı bilgiyi ortaya çıkarabilmek adına istatistiksel analiz, ilişki kuralları, sınıflandırma analizi, kümeleme analizi ve sıralı örüntüler vb. gibi veri madenciliği teknikleri kullanılır.
Soru 33
aşağıdakilerden hangisi web madenciliği döneminde kullanılan teknolojilerden biridir?
Seçenekler
A
Bilgisayar
B
Diskler
C
ODBC
D
Gelişmiş algoritmalar
E
www
Açıklama:
bu dönemin teknolojileri şu şekilde sıralanmaktadır:
- WWW
• İnternet
• Devasa ölçekli veritabanı.
Soru 34
aşağıdakilerden hangisi veri madenciliği adımlarından biri değildir?
Seçenekler
A
Verinin saklanması ve yönetimi
B
Verinin analiz edilmesi
C
Verinin elde edilmesi
D
Veri erişiminin sağlanması
E
literatür taraması
Açıklama:
Veri madenciliği,
i. Verinin elde edilmesi
ii. Verinin saklanması ve yönetimi
iii. Veri erişiminin sağlanması
iv. Verinin analiz edilmesi
v. Analiz sonuçlarının anlaşılır bir biçimde sunulması
temel adımlarından oluşan bir süreçtir.
literatür taraması
i. Verinin elde edilmesi
ii. Verinin saklanması ve yönetimi
iii. Veri erişiminin sağlanması
iv. Verinin analiz edilmesi
v. Analiz sonuçlarının anlaşılır bir biçimde sunulması
temel adımlarından oluşan bir süreçtir.
literatür taraması
Soru 35
aşağıdakilerden hangisi web madenciliği uygulama alanlarından biridir?
Seçenekler
A
Bankacılık
B
Pazarlama
C
İmalat
D
Sağlık
E
E-Siyaset
Açıklama:
- E-öğrenme
• Dijital Kütüphaneler
• E-Devlet
• Elektronik Ticaret
• E-Siyaset
• E-Demokrasi
• Güvenlik ve Suç Soruşturması vb.
Soru 36
Aşağıdakilerden hangisi veri madenciliğinin zorluklarından biridir?
Seçenekler
A
Web sayfalarının karmaşıklığı
B
Webin büyüklüğü
C
Bilginin bağlantısı
D
Bilginin dinamikliği
E
Ağ ayarları
Açıklama:
veri madenciliğinin zorlukları şu şekilde özetlenebilir:
Web sayfalarının karmaşıklığı, webin büyüklüğü, bilginin bağlantısı ve bilginin dinamikliği web madenciliğinin zorluklarındandır. Doğru cevap E.
- Ağ ayarları
• Veri kalitesi
• Gizliliğin korunması
• Ölçeklenebilirlik
• Karmaşık ve heterojen veri
Web sayfalarının karmaşıklığı, webin büyüklüğü, bilginin bağlantısı ve bilginin dinamikliği web madenciliğinin zorluklarındandır. Doğru cevap E.
Soru 37
aşağıdakilerden hangisi web madenciliği sürecinin adımlarından biri değildir?
Seçenekler
A
Kaynakların Tespiti:
B
Bilgi Seçimi ve Ön İşleme
C
Genelleştirme
D
Analiz
E
yayınlama
Açıklama:
İnternet ortamından yararlı bilginin keşfi için, web madenciliği sürecini dört temel
adımda ele alabiliriz.
1. Kaynakların Tespiti: İlgilenilen konuda bilgi içeren web dokümanlarının belirlenmesi ve elde edilmesi.
2. Bilgi Seçimi ve Ön İşleme: Elde edilen kaynaklardan ihtiyaç duyulan bilginin otomatik olarak seçilmesi ve kullanılabilir hâle getirilmesi.
3. Genelleştirme: Bireysel web sitelerindeki örüntü (pattern) veya kuralların otomatik
olarak çıkarılması ve diğer web siteleri ile karşılaştırarak genellenmesi.
4. Analiz: Elde edilen genel örüntü veya kuralların doğruluklarının onaylanması ve /
veya yorumlanması.
yayınlama
adımda ele alabiliriz.
1. Kaynakların Tespiti: İlgilenilen konuda bilgi içeren web dokümanlarının belirlenmesi ve elde edilmesi.
2. Bilgi Seçimi ve Ön İşleme: Elde edilen kaynaklardan ihtiyaç duyulan bilginin otomatik olarak seçilmesi ve kullanılabilir hâle getirilmesi.
3. Genelleştirme: Bireysel web sitelerindeki örüntü (pattern) veya kuralların otomatik
olarak çıkarılması ve diğer web siteleri ile karşılaştırarak genellenmesi.
4. Analiz: Elde edilen genel örüntü veya kuralların doğruluklarının onaylanması ve /
veya yorumlanması.
yayınlama
Soru 38
aşağıdakilerden hangisi webten bilgi çıkarma uygulamalarında karşılaşılan sorunlardan biri değildir?
Seçenekler
A
Araştırılan konuyu bulma
B
Yararlı bilgi keşfi
C
İstenilen bilgiyi bulma
D
Bilgiyi kişiselleştirme
E
uygun araştırmacıyı bulma
Açıklama:
Webden bilgi çıkarım uygulamalarında genel olarak
karşılaşılan sorunlar izleyen biçimde açıklanabilir.
1. Araştırılan konuyu bulma: Webde belirli bir bilgiyi bulmak için, genellikle ya
doğrudan web belgeleri taranır ya da bir arama motoru kullanılır. Bilgiye erişim
amacıyla arama motoru kullanıldığında, araştırılan konuya ilişkin bir ya da birkaç anahtar kelime girilir ve girilen kelime(ler)le ilişkili sayfalar sıralanır. Sorgu
tabanlı internet taramalarının iki ana sorunu vardır. Birincisi konuyla alakasız
birçok sayfanın sıralanmasına neden olan düşük hassasiyet, ikincisi ise web sayfalarının indekslenme kapasitesinin azlığından kaynaklanan düşük duyarlılıktır.
Sorgu ile daha çok ilişkili sayfaların nasıl bulunacağı son yılların popüler konuları arasındadır.
2. İstenilen bilgiyi bulma: Arama motorları çoğunlukla bir ya da birkaç kelime üzerinden aramayı gerçekleştirir. Bazen bu kelime(ler) içerisinde eş sesli (sesteş) kelimelerin olmasından dolayı araştırılan konun
uygun araştırmacıyı bulma
karşılaşılan sorunlar izleyen biçimde açıklanabilir.
1. Araştırılan konuyu bulma: Webde belirli bir bilgiyi bulmak için, genellikle ya
doğrudan web belgeleri taranır ya da bir arama motoru kullanılır. Bilgiye erişim
amacıyla arama motoru kullanıldığında, araştırılan konuya ilişkin bir ya da birkaç anahtar kelime girilir ve girilen kelime(ler)le ilişkili sayfalar sıralanır. Sorgu
tabanlı internet taramalarının iki ana sorunu vardır. Birincisi konuyla alakasız
birçok sayfanın sıralanmasına neden olan düşük hassasiyet, ikincisi ise web sayfalarının indekslenme kapasitesinin azlığından kaynaklanan düşük duyarlılıktır.
Sorgu ile daha çok ilişkili sayfaların nasıl bulunacağı son yılların popüler konuları arasındadır.
2. İstenilen bilgiyi bulma: Arama motorları çoğunlukla bir ya da birkaç kelime üzerinden aramayı gerçekleştirir. Bazen bu kelime(ler) içerisinde eş sesli (sesteş) kelimelerin olmasından dolayı araştırılan konun
uygun araştırmacıyı bulma
Soru 39
aşağıdakilerden hangisi web madenciliğinde kullanılan verilerden biri değildir?
Seçenekler
A
İçerik verisi
B
Yapı verisi
C
Kullanım verisi
D
Kullanıcı profil verisi
E
sunucu verisi
Açıklama:
Web madenciliğinde kullanılan
verileri dört başlıkta inceleyebiliriz.
1. İçerik verisi: Web sayfalarında kullanıcının erişimine sunulan verilerdir. Bunlar
şekil, resim, grafik, görüntü ve ses dosyaları gibi gerçek verilerin yanısıra, tanımlayıcı kelimeler, etiketler ve doküman özellikleri gibi verilerden oluşmaktadır. İçerik
verisi düz metin gibi yapılandırılmamış, HTML dokümanları gibi yarı yapılandırılmış veya veritabanlarından elde edilen veriler şeklindeki yapılandırılmış verileri
içerir.
2. Yapı verisi: Bir web sitesinin içeriğinde yer alan sayfaların birbirleri ile veya diğer
web siteleri ile olan bağlantılarının, tasarımını yapan kişi tarafından nasıl düzenlendiğine dair bilgilerdir. Yapı verisi, bir web sayfasının oluşturulmasında kullanılan HTML veya XML etiketleri gibi veri yapıları olabileceği gibi, sayfalar hatta
siteler arası bağlantıları sağlayan linkler şeklindeki veri yapıları da olabilir. Daha
kısa bir ifadeyle yapı verisi, bir web sitesinin sit
sunucu verisi
verileri dört başlıkta inceleyebiliriz.
1. İçerik verisi: Web sayfalarında kullanıcının erişimine sunulan verilerdir. Bunlar
şekil, resim, grafik, görüntü ve ses dosyaları gibi gerçek verilerin yanısıra, tanımlayıcı kelimeler, etiketler ve doküman özellikleri gibi verilerden oluşmaktadır. İçerik
verisi düz metin gibi yapılandırılmamış, HTML dokümanları gibi yarı yapılandırılmış veya veritabanlarından elde edilen veriler şeklindeki yapılandırılmış verileri
içerir.
2. Yapı verisi: Bir web sitesinin içeriğinde yer alan sayfaların birbirleri ile veya diğer
web siteleri ile olan bağlantılarının, tasarımını yapan kişi tarafından nasıl düzenlendiğine dair bilgilerdir. Yapı verisi, bir web sayfasının oluşturulmasında kullanılan HTML veya XML etiketleri gibi veri yapıları olabileceği gibi, sayfalar hatta
siteler arası bağlantıları sağlayan linkler şeklindeki veri yapıları da olabilir. Daha
kısa bir ifadeyle yapı verisi, bir web sitesinin sit
sunucu verisi
Soru 40
aşağıdakilerden hangisi web verisinin özelliklerinden biri değildir?
Seçenekler
A
Web ortamındaki veri miktarı aşırı büyüklüktedir
B
Web ortamındaki veri dağınık ve heterojen bir yapıdadır
C
Web ortamındaki veri yapılandırılmamıştır
D
Web ortamındaki veri dinamiktir
E
Web ortamındaki veri statiktir
Açıklama:
Web ortamındaki veri miktarı aşırı büyüklüktedir. İnternete erişim olanaklarının
giderek artması ve kolaylaşmasına paralel olarak web ortamındaki verinin boyutu
her geçen gün katlanarak artmaktadır. Şekil 8.1’de sunulan yıllara göre web site
sayılarındaki değişimi ifade eden grafik ve Şekil 8.2’de sunulan yıllara göre internet
kullanıcı sayılarındaki değişimi ifade eden grafik incelendiğinde de çok kısa sayılabilecek bir süre zarfında web verisindeki inanılmaz artışı kestirmek zor değildir.
Günümüzde internet üzerinde bulunan verinin büyüklüğünün kestirilmesi neredeyse imkansız bir hâl almıştır. Bu nedenle geleneksel veritabanı teknikleri ile bu
web verisinin üstesinden gelmek mümkün değildir.
• Web ortamındaki veri dağınık ve heterojen bir yapıdadır. İnternet üzerinden tüm
veriler dünyanın dört bir tarafına yayılmış bilgisayarlar ve sunucular vasıtasıyla bir
şekilde birbirleriyle bağlantılı olabildiğinden dağınık bir yapıdadır. Aynı zamanda
metin, resim, s
Web ortamındaki veri statiktir
giderek artması ve kolaylaşmasına paralel olarak web ortamındaki verinin boyutu
her geçen gün katlanarak artmaktadır. Şekil 8.1’de sunulan yıllara göre web site
sayılarındaki değişimi ifade eden grafik ve Şekil 8.2’de sunulan yıllara göre internet
kullanıcı sayılarındaki değişimi ifade eden grafik incelendiğinde de çok kısa sayılabilecek bir süre zarfında web verisindeki inanılmaz artışı kestirmek zor değildir.
Günümüzde internet üzerinde bulunan verinin büyüklüğünün kestirilmesi neredeyse imkansız bir hâl almıştır. Bu nedenle geleneksel veritabanı teknikleri ile bu
web verisinin üstesinden gelmek mümkün değildir.
• Web ortamındaki veri dağınık ve heterojen bir yapıdadır. İnternet üzerinden tüm
veriler dünyanın dört bir tarafına yayılmış bilgisayarlar ve sunucular vasıtasıyla bir
şekilde birbirleriyle bağlantılı olabildiğinden dağınık bir yapıdadır. Aynı zamanda
metin, resim, s
Web ortamındaki veri statiktir
Soru 41
aşağıdakilerden hangisi veri ön işleme aşamalarından biri değildir?
Seçenekler
A
Verinin Temizlenmesi
B
Kullanıcı Bilgisinin Belirlenmesi
C
Oturum Bilgisinin Belirlenmesi
D
İz Tamamlama
E
verinin sınıflandırılması
Açıklama:
Bu aşamalar genel hatlarıyla şu şekilde ifade edilebilir:
i. Verinin Temizlenmesi: Kullanıcı erişim dosyaları içerisinde yer alan geçerliliği olmayan veri ve gereksiz bilgilerin ayıklanması işlemidir.
ii. Kullanıcı Bilgisinin Belirlenmesi: Web kayıt dosyalarında yer alan erişim bilgilerinin, kullanıcıların kimlik bilgilerinden ziyade, aynı kullanıcıya ait olup olmadığının tespit edilmesi işlemidir.
iii. Oturum Bilgisinin Belirlenmesi: Kullanıcının bir web sitesine giriş-çıkışı arasında
geçen süre yani bir oturumda gerçekleştirdiği davranış ve aktivitelerin kümelenmesi işlemidir.
iv. İz (Yol) Tamamlama: Kullanıcı erişim kayıtları içerisinde çeşitli sebeplerden dolayı
yer almayan eksik referansların veya kayıt dışı bağlantıların tamamlanması işlemidir.
verinin sınıflandırılması
i. Verinin Temizlenmesi: Kullanıcı erişim dosyaları içerisinde yer alan geçerliliği olmayan veri ve gereksiz bilgilerin ayıklanması işlemidir.
ii. Kullanıcı Bilgisinin Belirlenmesi: Web kayıt dosyalarında yer alan erişim bilgilerinin, kullanıcıların kimlik bilgilerinden ziyade, aynı kullanıcıya ait olup olmadığının tespit edilmesi işlemidir.
iii. Oturum Bilgisinin Belirlenmesi: Kullanıcının bir web sitesine giriş-çıkışı arasında
geçen süre yani bir oturumda gerçekleştirdiği davranış ve aktivitelerin kümelenmesi işlemidir.
iv. İz (Yol) Tamamlama: Kullanıcı erişim kayıtları içerisinde çeşitli sebeplerden dolayı
yer almayan eksik referansların veya kayıt dışı bağlantıların tamamlanması işlemidir.
verinin sınıflandırılması
Soru 42
aşağıdakilerden hangisi örüntü keşfi için kullanılan tekniklerden biri değildir?
Seçenekler
A
İstatistiksel Analiz
B
İlişki Kuralları
C
Sınıflandırma Analizi
D
Kümeleme Analizi
E
yapı geçerliliği analizleri
Açıklama:
örüntü keşfi veri ön işleme aşamasından geçirilmiş analize hazır olan verilere veri madenciliği tekniklerinin uygulanarak yararlı bilginin ortaya çıkarılması aşamasıdır. Bu aşamada
işlenmiş veriden önemli ve anlamlı bilgiyi ortaya çıkarabilmek adına istatistiksel analiz,
ilişki kuralları, sınıflandırma analizi, kümeleme analizi ve sıralı örüntüler vb. gibi veri
madenciliği teknikleri kullanılır
yapı geçerliliği analizleri
işlenmiş veriden önemli ve anlamlı bilgiyi ortaya çıkarabilmek adına istatistiksel analiz,
ilişki kuralları, sınıflandırma analizi, kümeleme analizi ve sıralı örüntüler vb. gibi veri
madenciliği teknikleri kullanılır
yapı geçerliliği analizleri
Soru 43
Aşağıdakilerden hangisi web madenciliğinin özelliklerindendir?
I-Çok iş içerirmesine rağmen işleme süreci kısadır.
II-Veri kişisel ve gizlidir.
III-Çevrimiçi veriler kullanılır.
I-Çok iş içerirmesine rağmen işleme süreci kısadır.
II-Veri kişisel ve gizlidir.
III-Çevrimiçi veriler kullanılır.
Seçenekler
A
Yalnız I
B
Yalnız I, II
C
Yalnız I, III
D
Yalnız II, III
E
I, II, III
Açıklama:
Web Madenciliğinde, sunucu veritabanı 10 milyon iş içerirmesine rağmen işleme süreci kısadır. Veri gizli değildir. Sadece kayıt dosyalarına erişebilmek için izin gerekir. Çevrimiçi veriler kullanılır.
Soru 44
İnternet ortamından yararlı biilgiiniin keşfii iiçiin, web madenciiliğiii süreciinii doğru şekilde sıralayınız?
I-Kaynakların Tespiitii
II-Biilgii Seçiimii ve Ön İşleme
III-Genelleştiirme
IV-Analiiz
I-Kaynakların Tespiitii
II-Biilgii Seçiimii ve Ön İşleme
III-Genelleştiirme
IV-Analiiz
Seçenekler
A
I-II-III-IV
B
I-III-II-IV
C
II-I-III-IV
D
II-III-I-IV
E
III-I-II-IV
Açıklama:
İnternet ortamından yararlı biilgiiniin keşfii iiçiin, web madenciiliğiii süreciinii dört temel adımda ele alabiiliiriiz.
1. Kaynakların Tespiitii: İlgileniilen konuda biilgii iiçeren web dokümanlarının beliirlenmesi ve elde ediilmesii.
2. Biilgii Seçiimii ve Ön İşleme: Elde ediilen kaynaklardan iihtiiyaç duyulan biilgiiniin otomatiik olarak seçiilmesii ve kullanılabiiliir hâle getiiriilmesii.
3. Genelleştiirme: Biireysel web siiteleriindekii örüntü (pattern) veya kuralların otomatiik olarak çıkarılması ve diğer web siitelerii iile karşılaştırarak genellenmesii.
4. Analiiz: Elde ediilen genel örüntü veya kuralların doğruluklarının onaylanması ve/veya yorumlanması.
1. Kaynakların Tespiitii: İlgileniilen konuda biilgii iiçeren web dokümanlarının beliirlenmesi ve elde ediilmesii.
2. Biilgii Seçiimii ve Ön İşleme: Elde ediilen kaynaklardan iihtiiyaç duyulan biilgiiniin otomatiik olarak seçiilmesii ve kullanılabiiliir hâle getiiriilmesii.
3. Genelleştiirme: Biireysel web siiteleriindekii örüntü (pattern) veya kuralların otomatiik olarak çıkarılması ve diğer web siitelerii iile karşılaştırarak genellenmesii.
4. Analiiz: Elde ediilen genel örüntü veya kuralların doğruluklarının onaylanması ve/veya yorumlanması.
Soru 45
Aşağıdakilerden hangisi webten bilgi çıkarımı uygulamalarında karşılaşılan sorunlardandır?
I-Konuyla alakasız biirçok sayfanın sıralanmasına neden olan düsük hassasiiyet.
II-Web sayfalarının iindekslenme kapasiitesiiniin azlığından kaynaklanan düşük duyarlılık.
III-Eş seslii (sesteş) kelimeleriin olması.
I-Konuyla alakasız biirçok sayfanın sıralanmasına neden olan düsük hassasiiyet.
II-Web sayfalarının iindekslenme kapasiitesiiniin azlığından kaynaklanan düşük duyarlılık.
III-Eş seslii (sesteş) kelimeleriin olması.
Seçenekler
A
Yalnız I
B
Yalnız I, II
C
Yalnız I, III
D
Yalnız II, III
E
I, II, III
Açıklama:
Webden biilgii çıkarım uygulamalarında genel olarak karşılaşılan sorunlarda sorgu tabanlı iinternet taramalarının iikii ana sorunu vardır. Biiriinciisii konuyla alakasız biirçok sayfanın sıralanmasına neden olan düsük hassasiiyet, iikiinciisii iise web sayfalarının iindekslenme kapasiitesiiniin azlığından kaynaklanan düşük duyarlılıktır. Arama motorları çoğunlukla biir ya da biirkaç keliime üzeriinden aramayı gerçekleştiiriir. Bazen bu keliime(ler) iiçeriisiinde eş seslii (sesteş) kelimeleriin olmasından dolayı araştırılan konunun dışında sonuçlarla karşılaşılır. Yanii keliimeniin bütün iiçeriisiindekii anlamı çoğunlukla diikkate alınmaz.
Soru 46
Aşağıdakilerden hangisi web madenciliğinde karşılaşılan zorlukları içermektedir?
I-Web sayfalarının karmaşıklığı
II-Webin küçüklüğü
III-Bilginin dinamikliği
IV-Kullanıcı iletişiminin çeşitliliği
I-Web sayfalarının karmaşıklığı
II-Webin küçüklüğü
III-Bilginin dinamikliği
IV-Kullanıcı iletişiminin çeşitliliği
Seçenekler
A
Yalnız I, II
B
Yalnız II, III
C
Yalnız I, III, IV
D
Yalnız I, II, III
E
I, II, III, IV
Açıklama:
Web madenciliğinde karşılaşılan zorluklar;
• Web sayfalarının karmaşıklığı
• Webin büyüklüğü
• Bilginin bağlantısı
• Bilginin dinamikliği
• Kullanıcı iletişiminin çeşitliliği
• Web sayfalarının karmaşıklığı
• Webin büyüklüğü
• Bilginin bağlantısı
• Bilginin dinamikliği
• Kullanıcı iletişiminin çeşitliliği
Soru 47
Aşağıdakilerden hangisi web verisinin özelliklerindendir?
I-Aşırı büyüklüktedir.
II-Dağınık ve heterojen bir yapıdadır.
III-Yapılandırılmamıştır
IV-Statiktir
I-Aşırı büyüklüktedir.
II-Dağınık ve heterojen bir yapıdadır.
III-Yapılandırılmamıştır
IV-Statiktir
Seçenekler
A
Yalnız I, II
B
Yalnız II, III
C
Yalnız III, IV
D
Yalnız I, II, III
E
I, II, III, IV
Açıklama:
Web ortamındaki veri miktarı aşırı büyüklüktedir. Web ortamındaki veri dağınık ve heterojen bir yapıdadır. Web ortamındaki veri yapılandırılmamıştır. Web ortamındaki veri dinamiktir.
Soru 48
Aşağıdakilerden hangisi web madenciliğine ait bir sınıftır?
I-Web İçeriik Madenciiliğii
II-Web Yapı Madenciiliği
III-Web Kullanım Madenciiliğii
I-Web İçeriik Madenciiliğii
II-Web Yapı Madenciiliği
III-Web Kullanım Madenciiliğii
Seçenekler
A
Yalnız I
B
Yalnız I, II
C
Yalnız I, III
D
Yalnız II, III
E
I, II, III
Açıklama:
İnternette yer alan biilgiiler farklı verii türleriinii barındırdıkları iiçiin web madenciiliğii, verii madenciiliğii süreciinde kullanılan web veriileriiniin türüne göre Web İçeriik Madenciiliğii, Web Yapı Madenciiliğii ve Web Kullanım Madenciiliğii şekliinde sınıflandırılır.
Soru 49
Aşağıdakilerden hangisi multimedya madenciliğinin araştırma konusu değildir?
Seçenekler
A
metin
B
resim
C
grafik
D
video
E
ses
Açıklama:
Metiin şekliinde sunulan iiçeriigiin analiizii metiin madenciiliiğii olarak adlandırılır ve günümüzde en çok araştırılan web iiçeriik madenciiliğii alanlarından biiriisiidiir. Resiim, ses ve görüntü vb. giibii kaynaklardan yararlı biilgiiniin çıkarılması iise multiimedya madenciiliğii olarak iifade ediilmektediir. Bu alanda da başta görüntü işleme olmak üzere biirçok tekniik geliiştiiriilmektediir.
Soru 50
Aşağıdakilerden hangisi web yapı madenciliğinin araştırma konusudur?
Seçenekler
A
bağlantı
B
metin
C
resim
D
ses
E
video
Açıklama:
Web yapı madenciiliiğii, web siitesiiniin yapısal özetiinii yanii kendii iiçeriisiindekii sayfalarla ve diiğer siitelerle olan bağlantı yapılarını elde ederek, bu yapılardan yararlı biilgiiniin ortaya çıkarılması olarak tanımlanıir.
Soru 51
Aşağıdakilerden hangisi web kullanım madenciliğinin araştırma konusudur?
I-kullanıcı profiillerii
II-çerezler
II-fare tıklamaları
IV-sayfa iiçeriik özelliikleri
I-kullanıcı profiillerii
II-çerezler
II-fare tıklamaları
IV-sayfa iiçeriik özelliikleri
Seçenekler
A
Yalnız I, II
B
Yalnız II, III
C
Yalnız III, IV
D
Yalnız I, II, III
E
I, II, III, IV
Açıklama:
İnternette herhangii biir kaynağa erişiim sağlandığında tarayıcı veya sunucular tarafından biir takım veriiler kayıt altına alınır. Bunlar sunucular tarafından depolanan kullanıcı eriişiim kayıtları, tarayıcı kayıtları, kullanıcı profiillerii, çerezler, fare tıklamaları, sayfa kaydırmaları, sayfa iiçeriik özelliiklerii vb. giibii kayıtlardır. Web kullanım madeniiliiği, kullanıcıdan elde ediilen bu biilgiiler aracılığı ile kullanıcıların iinternet geziinme alışkanlıklarını analiiz ederek kiişiiye özel modeller olusturmayı amaçlar.
Soru 52
Aşağıdakilerden hangisi web kullanım madenc
iliğini
temel uygulama alanlarındandır?
I-Kişi selleşti rme (Personali zati on)
II-S istem Gel işti rme (System Improvement)
III-Web S itesi Güncelleme (Si te Modi fi cat on)
IV-İş Zekası (Busi ness Intelli gence)
V-Kullanım Karakteri sti ği (Usage Characteri zati on)
I-Kişi selleşti rme (Personali zati on)
II-S istem Gel işti rme (System Improvement)
III-Web S itesi Güncelleme (Si te Modi fi cat on)
IV-İş Zekası (Busi ness Intelli gence)
V-Kullanım Karakteri sti ği (Usage Characteri zati on)
Seçenekler
A
Yalnız I, II
B
Yalnız II, III
C
Yalnız III, IV
D
Yalnız I, IV, V
E
I, II, III, IV, V
Açıklama:
Web kullanım madenc
iliğini
temel uygulama alanları;
Kişi selleşti rme (Personali zati on)
S istem Gel işti rme (System Improvement)
Web S itesi Güncelleme (Si te Modi fi cat on)
İş Zekası (Busi ness Intelli gence)
Kullanım Karakteri sti ği (Usage Characteri zati on)
Kişi selleşti rme (Personali zati on)
S istem Gel işti rme (System Improvement)
Web S itesi Güncelleme (Si te Modi fi cat on)
İş Zekası (Busi ness Intelli gence)
Kullanım Karakteri sti ği (Usage Characteri zati on)
Soru 53
"....................., büyük miktardaki bilgileri depolamada yetersiz kalan dosya-işlem sistemine alternatif olarak geliştirilen ve birbirleriyle ilişkili bilgilerin depolandığı alandır."
Metinde verilen boşluğa aşağıdaki seçeneklerden hangisi getirilmelidir?
Metinde verilen boşluğa aşağıdaki seçeneklerden hangisi getirilmelidir?
Seçenekler
A
Veri madenciliği
B
Veritabanı
C
Web dökümanları
D
Web madenciliği
E
Veri erişimi
Açıklama:
Veritabanı, büyük miktardaki bilgileri depolamada yetersiz kalan dosya-işlem sistemine alternatif olarak geliştirilen ve
birbirleriyle ilişkili bilgilerin depolandığı alandır.
birbirleriyle ilişkili bilgilerin depolandığı alandır.
Soru 54
- Verinin elde edilmesi
- Verinin saklanması ve yönetimi
- Veri erişiminin sağlanması
- Verinin analiz edilmesi
- Analiz sonuçlarının gizli tutulması
Seçenekler
A
Yalnız V
B
I - II
C
III - IV
D
II - IV - V
E
I - II - III - IV
Açıklama:
Veri madenciliği,
i. Verinin elde edilmesi
ii. Verinin saklanması ve yönetimi
iii. Veri erişiminin sağlanması
iv. Verinin analiz edilmesi
v. Analiz sonuçlarının anlaşılır bir biçimde sunulması temel adımlarından oluşan bir süreçtir.
i. Verinin elde edilmesi
ii. Verinin saklanması ve yönetimi
iii. Veri erişiminin sağlanması
iv. Verinin analiz edilmesi
v. Analiz sonuçlarının anlaşılır bir biçimde sunulması temel adımlarından oluşan bir süreçtir.
Soru 55
- Dijital Kütüphaneler
- E-Devlet
- Elektronik Ticaret
- Bankacılık
- Hukuk
Seçenekler
A
Yalnız V
B
IV - V
C
I - II - III
D
II - IV - V
E
I - II - III - IV
Açıklama:
Uygulama alanlarına göre web ve veri madenciliği arasındaki bazı farklar bulunmaktadır.
Web Madenciliği
• E-öğrenme
• Dijital Kütüphaneler
• E-Devlet
• Elektronik Ticaret
• E-Siyaset
• E-Demokrasi
• Güvenlik ve Suç Soruşturması vb.
Veri Madenciliği
• Bankacılık
• Pazarlama
• İmalat
• Sağlık
• Sigorta
• Hukuk
• Hava yolları
• Bilgisayar donanımı ve yazılımı
• Hükümet ve savunma vb.
Web Madenciliği
• E-öğrenme
• Dijital Kütüphaneler
• E-Devlet
• Elektronik Ticaret
• E-Siyaset
• E-Demokrasi
• Güvenlik ve Suç Soruşturması vb.
Veri Madenciliği
• Bankacılık
• Pazarlama
• İmalat
• Sağlık
• Sigorta
• Hukuk
• Hava yolları
• Bilgisayar donanımı ve yazılımı
• Hükümet ve savunma vb.
Soru 56
Aşağıdakilerden hangisi internet ortamından yararlı bilgi keşfedilirken kullanılan web madenciliği süreci adımlarından değildir?
Seçenekler
A
Kaynakların Tespiti: İlgilenilen konuda bilgi içeren web dokümanlarının belirlenmesi ve elde edilmesi.
B
Bilgi Seçimi ve Ön İşleme: Elde edilen kaynaklardan ihtiyaç duyulan bilginin otomatik olarak seçilmesi ve kullanılabilir hâle getirilmesi.
C
Bilgiyi kişiselleştirme: Kullanıcıların internet gezinme alışkanlıklarının kişiden kişiye değişiklik göstermesinden dolayı internette sunulan bilgilerin görsellik ve içerik bakımından farklı şekillerde olması.
D
Genelleştirme: Bireysel web sitelerindeki örüntü (pattern) veya kuralların otomatik olarak çıkarılması ve diğer web siteleri ile karşılaştırarak genellenmesi.
E
Analiz: Elde edilen genel örüntü veya kuralların doğruluklarının onaylanması veya yorumlanması.
Açıklama:
İnternet ortamından yararlı bilginin keşfi için, web madenciliği sürecini dört temel
adımda ele alabiliriz.
1. Kaynakların Tespiti: İlgilenilen konuda bilgi içeren web dokümanlarının belirlenmesi ve elde edilmesi.
2. Bilgi Seçimi ve Ön İşleme: Elde edilen kaynaklardan ihtiyaç duyulan bilginin otomatik olarak seçilmesi ve kullanılabilir hâle getirilmesi.
3. Genelleştirme: Bireysel web sitelerindeki örüntü (pattern) veya kuralların otomatik olarak çıkarılması ve diğer web siteleri ile karşılaştırarak genellenmesi.
4. Analiz: Elde edilen genel örüntü veya kuralların doğruluklarının onaylanması veya yorumlanması.
adımda ele alabiliriz.
1. Kaynakların Tespiti: İlgilenilen konuda bilgi içeren web dokümanlarının belirlenmesi ve elde edilmesi.
2. Bilgi Seçimi ve Ön İşleme: Elde edilen kaynaklardan ihtiyaç duyulan bilginin otomatik olarak seçilmesi ve kullanılabilir hâle getirilmesi.
3. Genelleştirme: Bireysel web sitelerindeki örüntü (pattern) veya kuralların otomatik olarak çıkarılması ve diğer web siteleri ile karşılaştırarak genellenmesi.
4. Analiz: Elde edilen genel örüntü veya kuralların doğruluklarının onaylanması veya yorumlanması.
Soru 57
- İçerik Madenciliği
- Bilgi Madenciliği
- Yapı Madenciliği
- Kullanım Madenciliği
Seçenekler
A
Yalnız I
B
Yalnız II
C
III - IV
D
I - III - IV
E
I - II - II - IV
Açıklama:
Web madenciliği web doküman ve servislerindeki yararlı bilgileri otomatik olarak ayıklamak ve elde etmek için veri madenciliği tekniklerini kullanır. İnternette yer alan bilgiler farklı veri türlerini barındırdıkları için web madenciliği, veri madenciliği sürecinde kullanılan web verilerinin türüne göre Web İçerik Madenciliği, Web Yapı Madenciliği ve Web Kullanım Madenciliği şeklinde sınıflandırılır.
Soru 58
- Bilgiye Erişim Yaklaşımı
- Veritabanı Yaklaşımı
- Kısa Metin Yaklaşımı
- Bağlantı Köprüleri Yaklaşımı
Seçenekler
A
Yalnız IV
B
Yalnız III
C
I - II
D
III - IV
E
I - II - III
Açıklama:
Web içerik madenciliğinin uygulandığı alanlara göre kullanılan iki yaklaşım vardır.
i. Bilgiye Erişim Yaklaşımı: Kullanıcı profili temel alınarak kullanıcılara sunulacak bilgileri filtrelemek, sınıflandırmak ve kullanıcı profil bilgilerini geliştirmek için kullanılan yaklaşımdır. Bilgiye erişim yaklaşımında yararlanılan temel teknik, arama motorları tarafından kullanılan web aramalarıdır. Web aramalarının ana veri kaynağı ise web sayfalarının içerdikleri metinlerdir. Bu yaklaşım ile web sayfalarının sınıflandırılması ve aynı içeriğe sahip sayfaların listelenmesi sağlanabilir.
ii. Veritabanı Yaklaşımı: Webdeki veriyi veritabanına kaydederek modellemek ve veriyi bütünleştirerek daha karmaşık bilgilerin yönetilmesi için kullanılan yaklaşımdır. Bu yaklaşım sayesinde webde yer alan veriler sınıflanarak veya kümelenerek modellenmek suretiyle veritabanları ve veri ambarları oluşturulur. Bu sayede de anahtar kelime tabanlı arama yerine daha gelişmiş sorgular çalıştırmak mümkün olur.
i. Bilgiye Erişim Yaklaşımı: Kullanıcı profili temel alınarak kullanıcılara sunulacak bilgileri filtrelemek, sınıflandırmak ve kullanıcı profil bilgilerini geliştirmek için kullanılan yaklaşımdır. Bilgiye erişim yaklaşımında yararlanılan temel teknik, arama motorları tarafından kullanılan web aramalarıdır. Web aramalarının ana veri kaynağı ise web sayfalarının içerdikleri metinlerdir. Bu yaklaşım ile web sayfalarının sınıflandırılması ve aynı içeriğe sahip sayfaların listelenmesi sağlanabilir.
ii. Veritabanı Yaklaşımı: Webdeki veriyi veritabanına kaydederek modellemek ve veriyi bütünleştirerek daha karmaşık bilgilerin yönetilmesi için kullanılan yaklaşımdır. Bu yaklaşım sayesinde webde yer alan veriler sınıflanarak veya kümelenerek modellenmek suretiyle veritabanları ve veri ambarları oluşturulur. Bu sayede de anahtar kelime tabanlı arama yerine daha gelişmiş sorgular çalıştırmak mümkün olur.
Soru 59
"................................, akademik olarak yazarlar ile yayınları arasındaki ilişkiyi kurmak için yapılan alıntıları inceleyen bir araştırma alanıdır. Bir yayın başka bir yayından alıntı yaptığında bu iki yayın arasında bir ilişki veya bağlantı kurulmuş olur. Dolayısıyla bu bağlantılar incelenerek yayınların önem düzeyleri ortaya konulmaya çalışılır."
Metinde verilen boşluğa aşağıdakilerden hangisi getirilmelidir?
Metinde verilen boşluğa aşağıdakilerden hangisi getirilmelidir?
Seçenekler
A
Örüntü analizi
B
Bilgi keşfi
C
Örüntü keşfi
D
Atıf analizi
E
Bağlantı köprüleri
Açıklama:
Atıf analizi, akademik olarak yazarlar ile yayınları arasındaki ilişkiyi kurmak için yapılan alıntıları inceleyen bir araştırma alanıdır. Bir yayın başka bir yayından alıntı yaptığında bu iki yayın arasında bir ilişki veya bağlantı kurulmuş olur. Dolayısıyla atıf analizinde de bu bağlantılar incelenerek yayınların önem düzeyleri ortaya konulmaya çalışılır.
Soru 60
Örüntü analizleri sonucunda elde edilecek veya keşfedilecek örüntülerin kullanılabilir yararlı bir bilgi olabilmesi için aşağıdakilerden hangisi gerekli değildir?
Seçenekler
A
İnsanlar tarafından kolayca anlaşılabilir olmalıdır.
B
Daha önceden keşfedilmemiş olmalıdır.
C
Belirli bir oranda geçerliliğinin sağlanmış olmalıdır.
D
İhtiyaçları karşılayan ve kullanılabilir olması gerekir.
E
Kullanıcı erişim dosyaları içerisinde yer alan geçerliliği olmayan verileri ayıklaması gerekir.
Açıklama:
Yapılacak analizler sonucunda elde edilecek veya keşfedilecek örüntülerin kullanılabilir yararlı bir bilgi olabilmesi için;
• İnsanlar tarafından kolayca anlaşılabilir olması
• Daha önceden keşfedilmemiş olması
• Belirli bir oranda geçerliliğinin sağlanmış olması
• İhtiyaçları karşılayan ve kullanılabilir olması gerekir.
• İnsanlar tarafından kolayca anlaşılabilir olması
• Daha önceden keşfedilmemiş olması
• Belirli bir oranda geçerliliğinin sağlanmış olması
• İhtiyaçları karşılayan ve kullanılabilir olması gerekir.
Soru 61
- Mesleki
- Eğitim
- Hobi
- Akademik
- Haber
Seçenekler
A
Yalnız I
B
II - III
C
III - IV - V
D
II - III - IV - V
E
I - II - III - IV - V
Açıklama:
Günümüzde kullanılmakta olan sosyal medya hizmetlerini temel olarak izleyen biçimde sınıflandırmak mümkündür.
1. Genel amaçlı veya arkadaş tabanlı: Bu hizmetler belirli bir konu üzerine odaklanmayan arkadaşlık temeline dayanan paylaşım hizmetleridir.
2. Bilgilendirici: Bu hizmetlerin amacı günlük sorunlara yanıtlar sunmaktır.
3. Mesleki: Bu hizmetler kariyer veya meslek planlamasında yeni fırsatlar edinmek için kullanılır.
4. Eğitim: Bu hizmetler öğrencinin deneyimini geliştirmek için kullanılır.
5. Hobiler: Bu hizmetler aynı şeylere ilgi duyan insanlar için bir buluşma noktasıdır.
6. Akademik: Bu hizmetler akademik ve bilimsel çalışmalar için güncel bilgi kaynağına erişim sunan hizmetlerdir.
7. Haberler: Bu hizmetler tüm toplumu ilgilendiren haber yayıncılığına ilişkin hizmetlerdir.
1. Genel amaçlı veya arkadaş tabanlı: Bu hizmetler belirli bir konu üzerine odaklanmayan arkadaşlık temeline dayanan paylaşım hizmetleridir.
2. Bilgilendirici: Bu hizmetlerin amacı günlük sorunlara yanıtlar sunmaktır.
3. Mesleki: Bu hizmetler kariyer veya meslek planlamasında yeni fırsatlar edinmek için kullanılır.
4. Eğitim: Bu hizmetler öğrencinin deneyimini geliştirmek için kullanılır.
5. Hobiler: Bu hizmetler aynı şeylere ilgi duyan insanlar için bir buluşma noktasıdır.
6. Akademik: Bu hizmetler akademik ve bilimsel çalışmalar için güncel bilgi kaynağına erişim sunan hizmetlerdir.
7. Haberler: Bu hizmetler tüm toplumu ilgilendiren haber yayıncılığına ilişkin hizmetlerdir.
Soru 62
- Kelime Bulutu
- Kümeleme
- Sınıflandırma
- n-gram
Seçenekler
A
Yalnız I
B
Yalnız IV
C
II - III
D
I - II - III
E
II - III - IV
Açıklama:
API (Application Programming Interface / Uygulama Programlama Arayüzü), bir yazılımın başka bir yazılımda tanımlanmış fonksiyonlarını kullanabilmesi için uygulama oluşturmada kullanılan alt program, protokol ve araçlar bütünüdür.
Bireylerin anlık bilgileri paylaşma isteğine cevap vermesi bakımından kullanıcıları için kullanışlı bir ortam olan Twitter, özellikle kısa mesajlaşma aşamasında faydalı bir platform olarak karşımıza çıkmaktadır. Twitter verileri ile R’de birçok farklı analiz gerçekleştirmek mümkündür. Ancak yapılacak analizlerde kullanılacak Twitter verilerini kullanıcının kendi verileri ve tüm kullanıcıların verileri olmak üzere iki kısımda incelemek yerinde olacaktır.
Analiz I: Kişisel Twitter Verilerinizin Analizi
Twitter’da kullanıcı hesabınızı (profilinizi) oluşturduğunuz andan itibaren ilk attığınız tweet’ten son attığınız tweete kadar olan tüm tweet verilerinize ulaşmanız ve bu verilerle bir takım analizler yapmanız mümkündür.
Analiz II : Kelime Bulutu
Kişisel Twitter verilerinizin haricinde tüm Twitter kullanıcılarının göndermiş oldukları tweetler, R’de belirli anahtar kelime veya kelimeler girmek suretiyle süzgeçten geçirilebilir ve sonuçta girilen anahtar kelime(ler) ile ilişkili bir kelime bulutu grafiği elde edilebilir. Twitter ortamındaki tüm tweetleri tarayabilmek için R kullanıcıların Twitter’ın uygulama programlama arayüzüne(API) erişim sağlamaları gerekmektedir.
Bireylerin anlık bilgileri paylaşma isteğine cevap vermesi bakımından kullanıcıları için kullanışlı bir ortam olan Twitter, özellikle kısa mesajlaşma aşamasında faydalı bir platform olarak karşımıza çıkmaktadır. Twitter verileri ile R’de birçok farklı analiz gerçekleştirmek mümkündür. Ancak yapılacak analizlerde kullanılacak Twitter verilerini kullanıcının kendi verileri ve tüm kullanıcıların verileri olmak üzere iki kısımda incelemek yerinde olacaktır.
Analiz I: Kişisel Twitter Verilerinizin Analizi
Twitter’da kullanıcı hesabınızı (profilinizi) oluşturduğunuz andan itibaren ilk attığınız tweet’ten son attığınız tweete kadar olan tüm tweet verilerinize ulaşmanız ve bu verilerle bir takım analizler yapmanız mümkündür.
Analiz II : Kelime Bulutu
Kişisel Twitter verilerinizin haricinde tüm Twitter kullanıcılarının göndermiş oldukları tweetler, R’de belirli anahtar kelime veya kelimeler girmek suretiyle süzgeçten geçirilebilir ve sonuçta girilen anahtar kelime(ler) ile ilişkili bir kelime bulutu grafiği elde edilebilir. Twitter ortamındaki tüm tweetleri tarayabilmek için R kullanıcıların Twitter’ın uygulama programlama arayüzüne(API) erişim sağlamaları gerekmektedir.
Soru 63
Veri madenciliğinde gelişmiş algoritmalarla ileriye dönük çıkarmalarda bulunmaya hangi senelerde başlanılmıştır?
Seçenekler
A
1960' lar
B
1980' lar
C
1990' lar
D
2000' ler
E
Günümüz
Açıklama:
Tablo 8.1' de görülebileceği gibi veri madenciliğinde gelişmiş algoritmalarla ileriye dönük çıkarmalarda bulunmaya 2000' li yıllarda başlanılmıştır.
Soru 64
Web Madenciliği hakkında aşağıdakilerden hangisi yanlıştır?
Seçenekler
A
Geniş bir veritabanından bilgi sağlanır.
B
Sunucu veritabanı 10 milyon iş içerirmesine rağmen işleme süreci kısadır.
C
Çevrimiçi veriler kullanılır.
D
Veri kişisel ve gizlidir. Ancak yetkili kullanıcı tarafından erişilebilir.
E
Veriler, sunucu günlükleri ve web sunucusu veritabanında saklanır.
Açıklama:
Web Madenciliğinde veri gizli değildir. Sadece kayıt dosyalarına erişebilmek için izin gerekir.
Soru 65
İnternet ortamından yararlı bilginin keşfi için, web madenciliği sürecini dört temel adımda ele alabiliriz. Bu adımlar hangi şıkta doğru sırasıyla verilmiştir?
Seçenekler
A
Bilgi Seçimi ve Ön İşleme - Kaynakların Tespiti - Analiz - Genelleştirme
B
Kaynakların Tespiti - Bilgi Seçimi ve Ön İşleme - Genelleştirme - Analiz
C
Bilgi Seçimi ve Ön İşleme - Kaynakların Tespiti - Genelleştirme - Analiz
D
Kaynakların Tespiti - Bilgi Seçimi ve Ön İşleme - Analiz - Genelleştirme
E
Bilgi Seçimi ve Ön İşleme - Analiz - Kaynakların Tespiti - Genelleştirme
Açıklama:
Doğru sıralama; Kaynakların Tespiti - Bilgi Seçimi ve Ön İşleme - Genelleştirme - Analiz, şeklindedir.
Soru 66
Bir ağ üzerinde sunucu bilgisayarlardan hizmet alan, bilgiye erişim yetkileri sunucu tarafından belirlenen kullanıcı bilgisayarlara ............. denir.
Yukarıdaki boşluğa aşağıdaki ifadelerden hangisi gelmelidir?
Yukarıdaki boşluğa aşağıdaki ifadelerden hangisi gelmelidir?
Seçenekler
A
Server
B
Vekil
C
İstemci
D
Veri tabanı
E
Veri ambarı
Açıklama:
Bir ağ üzerinde sunucu bilgisayarlardan hizmet alan, bilgiye erişim yetkileri sunucu tarafından belirlenen kullanıcı bilgisayarlara istemci denir.
Soru 67
...........................kullanıcıların web kaynaklarına erişimleri sırasında sunucu ya da tarayıcılar tarafından kayıt altına alınan verilerdir.
Yukarı boş bırakılan yere aşağıdaki ifadelerden hangisi gelmelidir?
Yukarı boş bırakılan yere aşağıdaki ifadelerden hangisi gelmelidir?
Seçenekler
A
İçerik verisi
B
Yapı verisi
C
Kullanım verisi
D
Kullanıcı profili verisi
E
Web verisi
Açıklama:
Kullanım verisi: Kullanıcıların web kaynaklarına erişimleri sırasında sunucu ya da tarayıcılar tarafından kayıt altına alınan verilerdir.
Soru 68
Web verisinin özellikleri hakkında aşağıdakilerden hangisi yanlıştır?
Seçenekler
A
Web ortamındaki veri miktarı aşırı büyüklüktedir.
B
Web ortamındaki veri dağınık ve heterojen bir yapıdadır.
C
Web ortamındaki veri yapılandırılmamıştır.
D
Web ortamındaki veri dinamiktir.
E
Web ortamındaki verinin işleme süreci veri madenciliğine göre daha uzundur.
Açıklama:
Web madenciliğinde sunucu veritabanı 10 milyon iş içermesine rağmen işleme süreci kısadır. Veri madenciliğine göre daha uzun değildir.
Soru 69
Web madenciliği, veri madenciliği sürecinde kullanılan web verilerinin türüne göre Web İçerik Madenciliği, Web Yapı Madenciliği ve Web Kullanım Madenciliği şeklinde sınıflandırılır. Aşağıdakilerden hangisi Web Yapı Madenciliğine bir örnektir?
Seçenekler
A
Bilgi Keşfi
B
Kısa Metin İşleme
C
Atıf Analizi
D
Örüntü Analizi
E
Kişiselleştirme
Açıklama:
Atıf analizi, akademik olarak yazarlar ile yayınları arasındaki ilişkiyi kurmak için yapılan alıntıları inceleyen bir araştırma alanıdır. Web yapı madenciliğine örnek olarak verilebilir.
Soru 70
Aşağıdakilerden hangisi bir örüntü keşfi değildir?
Seçenekler
A
İstatiksel Analiz
B
İlişki Kuralları
C
Sınıflandırma Analizi
D
Kümeleme Analizi
E
Veri Ön İşleme
Açıklama:
Veri Ön İşleme web kullanım madenciliğinin farklı bir aşamasıdır. Örüntü keşfinin bir türü değildir.
Soru 71
Web İçerik Madenciliği hakkında aşağıdakilerden hangisi doğrudur?
Seçenekler
A
Kullanılan veri tipi ikincildir.
B
Grafiksel gösterime sahiptir.
C
Veri görünümü etkileşimli veri yapısı şeklindedir.
D
İçerik verilerinden yararlı bilginin ortaya çıkarılması, keşfedilmesi amaçlanır.
E
Tarayıcı kayıtları ana verilerdendir.
Açıklama:
Web İçerik Madenciliğinde içerik verilerinden yararlı bilginin ortaya çıkarılması, keşfedilmesi amaçlanır.
Soru 72
Web Kullanım Madenciliği hakkında aşağıdaki ifadelerden hangisi doğrudur?
Seçenekler
A
Kullanılan veri tipi birincildir.
B
Ana veri kaynağı metin ve hiper metinlerdir.
C
Kullanıcı profilinin ve davranışlarının analizi hedeflenir.
D
Kümeleme, Sınıflandırma Örüntü ve Kural Çıkarımı uygulama alanlarındandır.
E
Bölgesel kapsamlıdır.
Açıklama:
Kullanıcı profilinin ve davranışlarının analizi hedeflenir.
Soru 73
- Elektronik ticaret
- Dijital kütüphaneler
- Hükümet ve savunma
- Bilgisayar donanımı ve yazılımı
Seçenekler
A
I ve II
B
II ve IV
C
I, II ve III
D
II, III ve IV
E
I, II, III ve IV
Açıklama:
Web Madenciliği Uygulama Alanları:
- E-Öğrenme
- Dijital Kütüphaneler
- E-Devlet
- Elektronik Ticaret
- E-Siyaset
- E-Demokrasi
- Güvenlik ve Suç Soruşturması vb.
Soru 74
- Ölçeklenebilirlik
- Gizliliğin korunması
- Karmaşık ve heterojen veri
- Kullanıcı iletişiminin çeşitliliği
Seçenekler
A
I ve II
B
II ve IV
C
I, II ve III
D
II, III ve IV
E
I, II, III ve IV
Açıklama:
Veri Madenciliği Zorluklar:
- Ağ ayarları
- Veri kalitesi
- Gizliliğin korunması
- Ölçeklenebilirlik
- Karmaşık ve heterojen veri
Soru 75
Aşağıdakilerden hangisi Web sayfalarında kullanıcının erişimine sunulan verilerdir?
Seçenekler
A
Yapı verisi
B
İçerik verisi
C
Sunucu verisi
D
Kullanım verisi
E
Kullanıcı profil verisi
Açıklama:
İçerik verisi: Web sayfalarında kullanıcının erişimine sunulan verilerdir. Bunlar şekil, resim, grafik, görüntü ve ses dosyaları gibi gerçek verilerin yanı sıra, tanımlayıcı kelimeler, etiketler ve doküman özellikleri gibi verilerden oluşmaktadır. İçerik verisi düz metin gibi yapılandırılmamış, HTML dokümanları gibi yarı yapılandırılmış veya veritabanlarından elde edilen veriler şeklindeki yapılandırılmış verileri içerir. Doğru cevap B’dir.
Soru 76
 Yukarıdaki şekilde “?” ile gösterilen yere aşağıdakilerden hangisi gelmelidir?
Yukarıdaki şekilde “?” ile gösterilen yere aşağıdakilerden hangisi gelmelidir?Seçenekler
A
Veri madenciliği
B
Web madenciliği
C
Metin madenciliği
D
Multimedya madenciliği
E
Sosyal medya madenciliği
Açıklama:
 Doğru cevap B’dir.
Doğru cevap B’dir.Soru 77
Aşağıdakilerden hangisi web sitesinin yapısal özetini yani kendi içerisindeki sayfalarla ve diğer sitelerle olan bağlantı yapılarını elde ederek, bu yapılardan yararlı bilginin ortaya çıkarılması olarak tanımlanabilir?
Seçenekler
A
Veri madenciliği
B
Metin madenciliği
C
Web yapı madenciliği
D
Web görüş madenciliği
E
Multimedya madenciliği
Açıklama:
Web yapı madenciliği, web sitesinin yapısal özetini yani kendi içerisindeki sayfalarla ve diğer sitelerle olan bağlantı yapılarını elde ederek, bu yapılardan yararlı bilginin ortaya çıkarılması olarak tanımlanabilir. Doğru cevap C’dir.
Soru 78
Aşağıdakilerden hangisi veri ön işleme aşamasının alt adımları arasında yer almaz?
Seçenekler
A
Verinin Belirlenmesi
B
İz (Yol) Tamamlama
C
Verinin Temizlenmesi
D
Oturum Bilgisinin Belirlenmesi
E
Kullanıcı Bilgisinin Belirlenmesi
Açıklama:
Veri ön işleme aşaması sunucularda depolanan kullanıcı erişim dosyalarının düzensiz ve karmaşık bir yapıda olmalarından ve çok büyük boyutlarda olabilmelerinden dolayı uzun bir uğraş gerektiren ve en zor aşamasıdır. Bu aşama, genel hatlarıyla ifade etmek gerekirse,
- Verinin Temizlenmesi: Kullanıcı erişim dosyaları içerisinde yer alan geçerliliği olmayan veri ve gereksiz bilgilerin ayıklanması işlemidir.
- Kullanıcı Bilgisinin Belirlenmesi: Web kayıt dosyalarında yer alan erişim bilgilerinin, kullanıcıların kimlik bilgilerinden ziyade, aynı kullanıcıya ait olup olmadığının tespit edilmesi işlemidir.
- Oturum Bilgisinin Belirlenmesi: Kullanıcının bir web sitesine giriş-çıkışı arasında geçen süre yani bir oturumda gerçekleştirdiği davranış ve aktivitelerin kümelenmesi işlemidir.
- İz (Yol) Tamamlama: Kullanıcı erişim kayıtları içerisinde çeşitli sebeplerden dolayı yer almayan eksik referansların veya kayıt dışı bağlantıların tamamlanması işlemidir.
Soru 79
Aşağıdakilerden hangisi Web Kullanım Madenciliğinin uygulama alanları arasında yer alır?
Seçenekler
A
Web şeması modelleme
B
Örüntü ve kural çıkarımı
C
Sınıflandırma
D
Kümeleme
E
Pazarlama
Açıklama:
Web Kullanım Madenciliği uygulama alanları:
- Kullanıcı modellemesi
- Web sitesi tasarımı, uyarlaması ve yönetimi
- Pazarlama
Soru 80
Aşağıdakilerden hangisi R’de ilgilenilen Facebook profil verilerine erişim sağlayabilmek için kullanılan fonksiyondur?
Seçenekler
A
str(veri)
B
fbOAuth()
C
c(“fb”, “veri”)
D
sapply(Facebook, function(x) x$getText())
E
search Facebook (‘veri’,resultType=”recent”)
Açıklama:
R’de ilgilenilen Facebook profil verilerine erişim sağlayabilmek için fbOAuth() fonksiyonundan yararlanılır. Doğru cevap B’dir.
Soru 81
Aşağıdakilerden hangisi günümüzde kullanılmakta olan sosyal medya hizmetlerinin temel sınıfları arasında yer almaz?
Seçenekler
A
Bilgilendirici
B
Haberler
C
Mesleki
D
Resmi
E
Eğitim
Açıklama:
Günümüzde kullanılmakta olan sosyal medya hizmetlerini temel olarak izleyen biçimde sınıflandırmak mümkündür.
- Genel amaçlı veya arkadaş tabanlı: Bu hizmetler belirli bir konu üzerine odaklanmayan arkadaşlık temeline dayanan paylaşım hizmetleridir.
- Bilgilendirici: Bu hizmetlerin amacı günlük sorunlara yanıtlar sunmaktır.
- Mesleki: Bu hizmetler kariyer veya meslek planlamasında yeni fırsatlar edinmek için kullanılır.
- Eğitim: Bu hizmetler öğrencinin deneyimini geliştirmek için kullanılır.
- Hobiler: Bu hizmetler aynı şeylere ilgi duyan insanlar için bir buluşma noktasıdır.
- Akademik: Bu hizmetler akademik ve bilimsel çalışmalar için güncel bilgi kaynağına erişim sunan hizmetlerdir.
- Haberler: Bu hizmetler tüm toplumu ilgilendiren haber yayıncılığına ilişkin hizmetlerdir.
Soru 82
Aşağıdakilerden hangisi 2016 yılı başında yapılan araştırmalara göre Türkiye’de internet kullanıcılarının sosyal medya sitelerine erişim oranıdır?
Seçenekler
A
%5
B
%15
C
%35
D
%53
E
%93
Açıklama:
2016 yılı başında yapılan araştırmalara göre Türkiye’de internet kullanıcılarının %53’ü sosyal medya sitelerine erişim sağlamaktadır. Doğru cevap D’dir.